
cs231n:python3.6.4對實驗資料影象的讀取,課後作業程式碼解釋
時間:2018年3月。
僅供參考,錯誤歡迎指正!!!
1.相信大家都已經在其他地方找到了cs231n的翻譯課程,鄰近演算法原理和KNN自己看其他人部落格,我就直接進入正題,解決操作上遇到的問題!!!
3.解壓資料放在Python的下路徑裡面。
4.重點來了,一般小白同學,剛開始學cs231n時候讀取資料不會,python下沒有讀取資料的函式,這就需要去下載,但是下載下來是python2.x的程式碼,必須做簡單的調整才可以在python3.6.4上執行,進而讀取資料!下面我直接給出程式碼,儲存為py檔案,就可以python編譯器裡面執行。
# -*- coding: utf-8 -*- """ Created on Tue Mar 27 16:03:04 2018 @author: 78175 """ import pickle as pickle #2.x的版本是cpickle,這裡從別人那裡copy是有問題的,3.x版本是pickle import numpy as np import os from scipy.misc import imread def load_CIFAR_batch(filename): """ load single batch of cifar """ with open(filename, 'rb') as f: datadict = pickle.load(f,encoding='iso-8859-1')#encoding='iso-8859-1這個在2.x版本中不需要,3.x中必須需要,會出編碼問題,也不需要懂,先copy X = datadict['data'] Y = datadict['labels'] X = X.reshape(10000, 3, 32, 32).transpose(0,2,3,1).astype("float") Y = np.array(Y) return X, Y def load_CIFAR10(ROOT):#這是root是資料夾的根目錄,在python工作空間裡面,把資料集解壓放在工作目錄下。 """ load all of cifar """ xs = [] ys = [] for b in range(1,6): f = os.path.join(ROOT, 'data_batch_%d' % (b, )) X, Y = load_CIFAR_batch(f) xs.append(X) ys.append(Y) Xtr = np.concatenate(xs) Ytr = np.concatenate(ys) del X, Y Xte, Yte = load_CIFAR_batch(os.path.join(ROOT, 'test_batch')) return Xtr, Ytr, Xte, Yte def load_tiny_imagenet(path, dtype=np.float32): """ Load TinyImageNet. Each of TinyImageNet-100-A, TinyImageNet-100-B, and TinyImageNet-200 have the same directory structure, so this can be used to load any of them. Inputs: - path: String giving path to the directory to load. - dtype: numpy datatype used to load the data. Returns: A tuple of - class_names: A list where class_names[i] is a list of strings giving the WordNet names for class i in the loaded dataset. - X_train: (N_tr, 3, 64, 64) array of training images - y_train: (N_tr,) array of training labels - X_val: (N_val, 3, 64, 64) array of validation images - y_val: (N_val,) array of validation labels - X_test: (N_test, 3, 64, 64) array of testing images. - y_test: (N_test,) array of test labels; if test labels are not available (such as in student code) then y_test will be None. """ # First load wnids with open(os.path.join(path, 'wnids.txt'), 'r') as f: wnids = [x.strip() for x in f] # Map wnids to integer labels wnid_to_label = {wnid: i for i, wnid in enumerate(wnids)} # Use words.txt to get names for each class with open(os.path.join(path, 'words.txt'), 'r') as f: wnid_to_words = dict(line.split('\t') for line in f) for wnid, words in wnid_to_words.iteritems(): wnid_to_words[wnid] = [w.strip() for w in words.split(',')] class_names = [wnid_to_words[wnid] for wnid in wnids] # Next load training data. X_train = [] y_train = [] for i, wnid in enumerate(wnids): if (i + 1) % 20 == 0: print ('loading training data for synset %d / %d' % (i + 1, len(wnids))) # To figure out the filenames we need to open the boxes file boxes_file = os.path.join(path, 'train', wnid, '%s_boxes.txt' % wnid) with open(boxes_file, 'r') as f: filenames = [x.split('\t')[0] for x in f] num_images = len(filenames) X_train_block = np.zeros((num_images, 3, 64, 64), dtype=dtype) y_train_block = wnid_to_label[wnid] * np.ones(num_images, dtype=np.int64) for j, img_file in enumerate(filenames): img_file = os.path.join(path, 'train', wnid, 'images', img_file) img = imread(img_file) if img.ndim == 2: ## grayscale file img.shape = (64, 64, 1) X_train_block[j] = img.transpose(2, 0, 1) X_train.append(X_train_block) y_train.append(y_train_block) # We need to concatenate all training data X_train = np.concatenate(X_train, axis=0) y_train = np.concatenate(y_train, axis=0) # Next load validation data with open(os.path.join(path, 'val', 'val_annotations.txt'), 'r') as f: img_files = [] val_wnids = [] for line in f: img_file, wnid = line.split('\t')[:2] img_files.append(img_file) val_wnids.append(wnid) num_val = len(img_files) y_val = np.array([wnid_to_label[wnid] for wnid in val_wnids]) X_val = np.zeros((num_val, 3, 64, 64), dtype=dtype) for i, img_file in enumerate(img_files): img_file = os.path.join(path, 'val', 'images', img_file) img = imread(img_file) if img.ndim == 2: img.shape = (64, 64, 1) X_val[i] = img.transpose(2, 0, 1) # Next load test images # Students won't have test labels, so we need to iterate over files in the # images directory. img_files = os.listdir(os.path.join(path, 'test', 'images')) X_test = np.zeros((len(img_files), 3, 64, 64), dtype=dtype) for i, img_file in enumerate(img_files): img_file = os.path.join(path, 'test', 'images', img_file) img = imread(img_file) if img.ndim == 2: img.shape = (64, 64, 1) X_test[i] = img.transpose(2, 0, 1) y_test = None y_test_file = os.path.join(path, 'test', 'test_annotations.txt') if os.path.isfile(y_test_file): with open(y_test_file, 'r') as f: img_file_to_wnid = {} for line in f: line = line.split('\t') img_file_to_wnid[line[0]] = line[1] y_test = [wnid_to_label[img_file_to_wnid[img_file]] for img_file in img_files] y_test = np.array(y_test) return class_names, X_train, y_train, X_val, y_val, X_test, y_test def load_models(models_dir): """ Load saved models from disk. This will attempt to unpickle all files in a directory; any files that give errors on unpickling (such as README.txt) will be skipped. Inputs: - models_dir: String giving the path to a directory containing model files. Each model file is a pickled dictionary with a 'model' field. Returns: A dictionary mapping model file names to models. """ models = {} for model_file in os.listdir(models_dir): with open(os.path.join(models_dir, model_file), 'rb') as f: try: models[model_file] = pickle.load(f)['model'] except pickle.UnpicklingError: continue return models
5.上面一長串程式碼,其實不用懂,只是讀資料的函式,不影響後面的操作。
6.接下來是讀取程式碼
Xtr, Ytr, Xte, Yte = load_CIFAR10('cifar-10-python/cifar-10-batches-py/')#這個位置一定是資料集資料夾,不是檔案,understand Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 *3) # 這是訓練集,這重新組成了一個新矩陣50000*3072,解釋下3072是指影象每個畫素下的每個顏色都表示一個特徵32*32*3 Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 *3)#測試集,1000*32*32*3
7.開始訓練
nn = NearestNeighbor() # 建立一個鄰近演算法物件
nn.train(Xtr_rows, Ytr) # 訓練樣本
Yte_predict = nn.predict(Xte_rows) # 預測集
print ('accuracy: %f' % ( np.mean(Yte_predict == Yte) ))# 平均分類精度計算8.訓練函式NearestNeighbor上面7所用到的函式
class NearestNeighbor(object): def __init__(self): pass def train(self, X, y): """ X is N x D where each row is an example. Y is 1-dimension of size N """ # the nearest neighbor classifier simply remembers all the training data self.Xtr = X self.ytr = y def predict(self, X): """ X is N x D where each row is an example we wish to predict label for """ num_test = X.shape[0]#獲取輸入樣本數量 # lets make sure that the output type matches the input type Ypred = np.zeros(num_test, dtype = self.ytr.dtype) # loop over all test rows for i in range(num_test): # find the nearest training image to the i'th test image # using the L1 distance (sum of absolute value differences) distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)#計算距離,訓練集每個影象特徵與樣本集特徵的距離 min_index = np.argmin(distances) # argmin取最小值座標 Ypred[i] = self.ytr[min_index] # 預測 return Ypred
距離選擇:計算向量間的距離有很多種方法,另一個常用的方法是L2距離,從幾何學的角度,可以理解為它在計算兩個向量間的歐式距離。L2距離的公式如下:
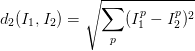
換句話說,我們依舊是在計算畫素間的差值,只是先求其平方,然後把這些平方全部加起來,最後對這個和開方。在Numpy中,我們只需要替換上面程式碼中的1行程式碼就行:
distances = np.sqrt(np.sum(np.square(self.Xtr - X[i,:]), axis = 1))注意在這裡使用了np.sqrt,但是在實際中可能不用。因為求平方根函式是一個單調函式,它對不同距離的絕對值求平方根雖然改變了數值大小,但依然保持了不同距離大小的順序。所以用不用它,都能夠對畫素差異的大小進行正確比較。如果你在CIFAR-10上面跑這個模型,正確率是35.4%,比剛才低了一點。
L1和L2比較。比較這兩個度量方式是挺有意思的。在面對兩個向量之間的差異時,L2比L1更加不能容忍這些差異。也就是說,相對於1個巨大的差異,L2距離更傾向於接受多箇中等程度的差異。L1和L2都是在p-norm常用的特殊形式。
9.KNN訓練,KNearestNeighbor類,直接上程式碼
# -*- coding: utf-8 -*-
"""
Created on Wed Mar 28 09:49:26 2018
@author: 78175
"""
import numpy as np
class KNearestNeighbor(object):#首先是定義一個處理KNN的類
""" a kNN classifier with L2 distance """
def __init__(self):
pass
def train(self, X, y):
"""
Train the classifier. For k-nearest neighbors this is just
memorizing the training data.
Inputs:
- X: A numpy array of shape (num_train, D) containing the training data
consisting of num_train samples each of dimension D.
- y: A numpy array of shape (N,) containing the training labels, where
y[i] is the label for X[i].
"""
self.X_train = X
self.y_train = y
def predict(self, X, k=1, num_loops=0):
"""
Predict labels for test data using this classifier.
Inputs:
- X: A numpy array of shape (num_test, D) containing test data consisting
of num_test samples each of dimension D.
- k: The number of nearest neighbors that vote for the predicted labels.
- num_loops: Determines which implementation to use to compute distances
between training points and testing points.
Returns:
- y: A numpy array of shape (num_test,) containing predicted labels for the
test data, where y[i] is the predicted label for the test point X[i].
"""
if num_loops == 0:#選擇三種不同計算距離的方法
dists = self.compute_distances_no_loops(X)
elif num_loops == 1:
dists = self.compute_distances_one_loop(X)
elif num_loops == 2:
dists = self.compute_distances_two_loops(X)
else:
raise ValueError('Invalid value %d for num_loops' % num_loops)
return self.predict_labels(dists, k=k)
def compute_distances_two_loops(self, X):#兩個迴圈
"""
Compute the distance between each test point in X and each training point
in self.X_train using a nested loop over both the training data and the
test data.
Inputs:
- X: A numpy array of shape (num_test, D) containing test data.
Returns:
- dists: A numpy array of shape (num_test, num_train) where dists[i, j]
is the Euclidean distance between the ith test point and the jth training
point.
"""
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
for j in range(num_train):
dists[i][j] = np.sqrt(np.sum(np.square(self.X_train[j,:] - X[i,:])))
#####################################################################
# TODO: #
# Compute the l2 distance between the ith test point and the jth #
# training point, and store the result in dists[i, j]. You should #
# not use a loop over dimension. #
#####################################################################
#####################################################################
# END OF YOUR CODE #
#####################################################################
return dists
def compute_distances_one_loop(self, X):
"""
Compute the distance between each test point in X and each training point
in self.X_train using a single loop over the test data.
Input / Output: Same as compute_distances_two_loops
"""
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
#######################################################################
# TODO: #
# Compute the l2 distance between the ith test point and all training #
# points, and store the result in dists[i, :]. #
#######################################################################
dists[i,:] = np.sqrt(np.sum(np.square(self.X_train-X[i,:]),axis = 1))
#######################################################################
# END OF YOUR CODE #
#######################################################################
return dists
def compute_distances_no_loops(self, X):#沒用迴圈完全用的矩陣執行,可能會出現,Memory error,建議把編譯器關了重新操作,是之前佔用的記憶體太多,用64位的儘量
"""
Compute the distance between each test point in X and each training point
in self.X_train using no explicit loops.
Input / Output: Same as compute_distances_two_loops
"""
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
#########################################################################
# TODO: #
# Compute the l2 distance between all test points and all training #
# points without using any explicit loops, and store the result in #
# dists. #
# #
# You should implement this function using only basic array operations; #
# in particular you should not use functions from scipy. #
# #
# HINT: Try to formulate the l2 distance using matrix multiplication #
# and two broadcast sums. #
#########################################################################
dists = np.multiply(np.dot(X,self.X_train.T),-2)
sq1 = np.sum(np.square(X),axis=1,keepdims = True) #保持二維特性
sq2 = np.sum(np.square(self.X_train),axis=1)
dists = np.add(dists,sq1)
dists = np.add(dists,sq2)
dists = np.sqrt(dists)
#########################################################################
# END OF YOUR CODE #
#########################################################################
return dists
def predict_labels(self, dists, k=1):
"""
Given a matrix of distances between test points and training points,
predict a label for each test point.
Inputs:
- dists: A numpy array of shape (num_test, num_train) where dists[i, j]
gives the distance betwen the ith test point and the jth training point.
Returns:
- y: A numpy array of shape (num_test,) containing predicted labels for the
test data, where y[i] is the predicted label for the test point X[i].
"""
num_test = dists.shape[0]
y_pred = np.zeros(num_test)
for i in range(num_test):
# A list of length k storing the labels of the k nearest neighbors to
# the ith test point.
closest_y = []
#########################################################################
# TODO: #
# Use the distance matrix to find the k nearest neighbors of the ith #
# training point, and use self.y_train to find the labels of these #
# neighbors. Store these labels in closest_y. #
# Hint: Look up the function numpy.argsort. #
#########################################################################
closest_y = self.y_train[np.argsort(dists[i,:])[:k]]
#排序argsort,把排序後的位置返回為一個向量,
#後面的[:,k]取前k個值 #並且前K個值數對應y_train裡面位置上,
#並取出值這些位置上的值,這些值代表了K個位置上的標籤,給closest_y #########
################################################################
#########################################################################
# TODO: #
# Now that you have found the labels of the k nearest neighbors, you #
# need to find the most common label in the list closest_y of labels. #
# Store this label in y_pred[i]. Break ties by choosing the smaller #
# label. #
#########################################################################
y_pred[i] = np.argmax(np.bincount(closest_y))
# #統計closest_y,bincount就是統計函式,統計每個數出現個數####
# 返回最大個數所在的位置,這個位置的數值就是標籤,標籤就是預測的結果
# END OF YOUR CODE #
#########################################################################
return y_pred10.上面程式碼直接複製用,對於小白來說,難點我已經中文備註,解釋,不清楚的自行百度下函式用法,下面KNN訓練。
Xval_rows = Xtr_rows[:1000, :] # take first 1000 for validation
Yval = Ytr[:1000]
Xtr_rows = Xtr_rows[1000:, :] # keep last 49,000 for train
Ytr = Ytr[1000:]#分成了49000個訓練集1000驗證集
validation_accuracies = []
for k in [1, 3, 5, 10, 20, 50, 100]:
# use a particular value of k and evaluation
#on validation data
nn = KNearestNeighbor()
nn.train(Xtr_rows, Ytr)
# here we assume a modified NearestNeighbor
#class that can take a k as input
Yval_predict = nn.predict(Xval_rows, k = k)
acc = np.mean(Yval_predict == Yval)
print ('accuracy: %f' % (acc,))
# keep track of what works on the validation
#set
validation_accuracies.append((k, acc))
結語:以上程式碼我已經完全調通可以直接用python3.6.4測試,可能這個過程都是現成的,但是小白會遇到很多問題,對比網上其他資料,主要就是直接從資料讀取程式碼,到讀取到訓練,小白會反映不過來的。我也只是把該改的改了,執行通了,把我認為需要加強理解的地方備註了,大牛勿噴!!!
第一次寫部落格,堅持!!!