
【神經網路】VGG、ResNet、GoogleLeNet、AlexNet等常用網路程式碼及預訓練模型
常用資料集:
模型們在ImageNet競賽上的top-5錯誤率概況:

常用預訓練模型池:

AlexNet資訊如上圖
- 在當時第一次使用了ReLU
- 使用了Norm層(在當時還不廣泛)
- 訓練資料量增大
- dropout 0.5
- 每批資料大小 128
- 優化方式:隨機梯度下降+Momentum 0.9
- 學習率為0.01。每次損失到達瓶頸時除以10
- L2 正則 引數為5e-4
VGG:
VGG是最符合典型CNN的一種網路,它在AlexNet的基礎上加深了網路,以達到更好的效果。
(以下引用http://blog.csdn.net/u012767526/article/details/51442367#vggnet分析)
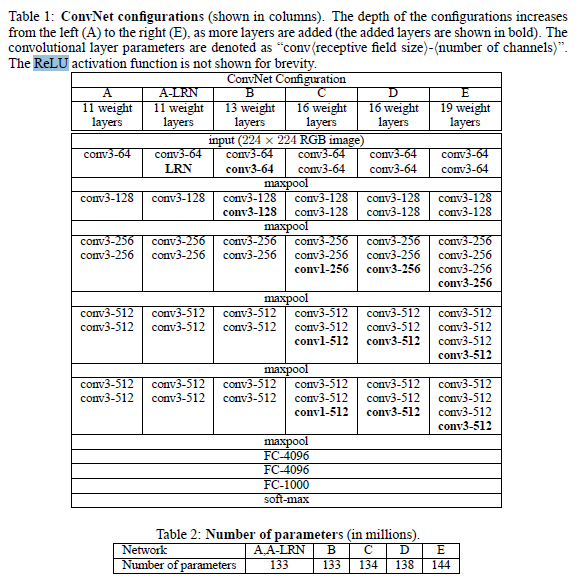
這裡有兩個表格,其中第一個表格是描述的是VGGNet的誕生過程。為了解決初始化(權重初始化)等問題,VGG採用的是一種Pre-training的方式,這種方式在經典的神經網路中經常見得到,就是先訓練一部分小網路,然後再確保這部分網路穩定之後,再在這基礎上逐漸加深。表1從左到右體現的就是這個過程,並且當網路處於D階段的時候,效果是最優的,因此D階段的網路也就是最後的VGGNet啦!
ResNet:
ResNet-1001在CIFAR-10上的表現
| mini-batch | CIFAR-10 test error (%): (median (mean+/-std)) |
|---|---|
| 128 (as in [a]) | 4.92 (4.89+/-0.14) |
| 64 (as in this code) | 4.62 (4.69+/-0.20) |
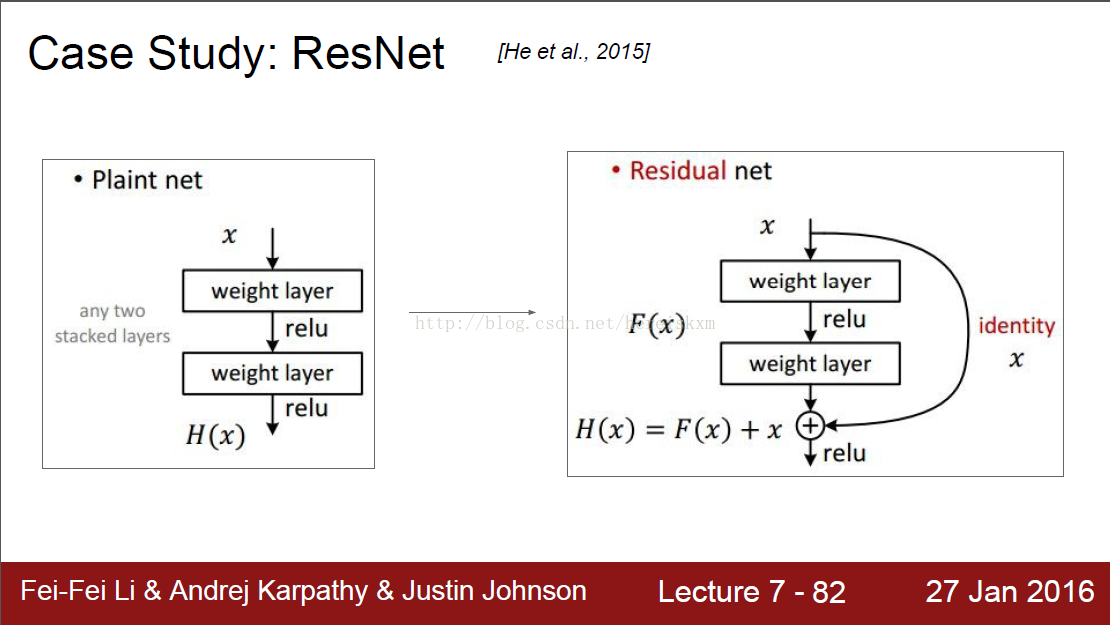
正常的網路是生成一個關於輸入的函式,而ResNet生成的是一個對於輸入的一個修飾:H(x) = F(x)+x。即神經網路生成的結果還要加上輸入,才是最終輸出。

訓練引數如上圖:
- 每一個Conv層後面都會有Batch Normalization層。
- 權重初始化方式:Xavier/2
- optimization方式:隨機梯度下降+Momentum(0.9)
- 學習率:0.1,每一次錯誤率達到瓶頸時除以10,直到錯誤率無法再優化為止。
- Mini-batch(每批訓練資料) 大小為256
- Weight 衰減1e-5(?)
- 不需要dropout