
SparkSQL如何實現聚合下推
簡介
在之前效能分析的文章中,我們用火焰圖看到了程式的一個瓶頸點,Spark的聚合操作執行,

其中GeneratedIterator#agg_doAggregateWithKeys是使用Code Generation技術生成的程式碼,生成的程式碼可參考這裡,或者這樣來看,
scala> val pairsDF = Seq((1,1), (2,2), (3,3)).toDF("a", "b")
pairsDF: org.apache.spark.sql.DataFrame = [a: int, b: int]
scala> pairsDF.createOrReplaceTempView("pairs" 之前我們也是留下了TODO準備來實現聚合操作下推到資料來源去執行。現在這個優化已經完成了,今天就來分享下是如何實現的。
為什麼要實現聚合下推
這個問題似乎問得比較蠢:)很明顯,如果資料來源能夠支援聚合操作,那麼將聚合下推就不必傳輸大量資料給到SparkSQL再進行聚合,而是直接返回聚合結果就行了。而且資料來源本身可能就對聚合有很多優化(快取什麼的),所以聚合下推才是一個較優的選擇。
聚合下推的需求其實在社群也已經提了很久了,當前SparkSQL只支援了Filter跟Project下推,下面幾個issue都是希望SparkSQL能夠支援更多的operator下推,
而且在SparkSummit上也有人分享過他們所做的實現,The Pushdown of Everything。在評論他們的實現之前,我們先來看下,原生的SparkSQL是怎麼實現聚合的,
spark.read.format("org.apache.spark.examples.sql.DefaultSource")
.option("from", "1").option("to", "10")
.load().createOrReplaceTempView("tt")
// scalastyle:off println
var df = spark.sql("SELECT count(*) FROM tt WHERE a>1 GROUP BY c")
println(df.queryExecution)DefaultSource的程式碼在這裡,輸出結果如下,
INFO SparkSqlParser: Parsing command: SELECT count(*) FROM tt WHERE a>1 GROUP BY c
== Parsed Logical Plan ==
'Aggregate ['c], [unresolvedalias('count(1), None)]
+- 'Filter ('a > 1)
+- 'UnresolvedRelation `tt`
== Analyzed Logical Plan ==
count(1): bigint
Aggregate [c#2], [count(1) AS count(1)#21L]
+- Filter (a#0 > 1)
+- SubqueryAlias tt
+- Relation[a#0,b#1L,c#2,d#3,e#4,g#5,f#6,i#7,j#8] ComplicatedScan(1,10)
== Optimized Logical Plan ==
Aggregate [c#2], [count(1) AS count(1)#21L]
+- Project [c#2]
+- Filter (isnotnull(a#0) && (a#0 > 1))
+- Relation[a#0,b#1L,c#2,d#3,e#4,g#5,f#6,i#7,j#8] ComplicatedScan(1,10)
== Physical Plan ==
*HashAggregate(keys=[c#2], functions=[count(1)], output=[count(1)#21L])
+- Exchange hashpartitioning(c#2, 200)
+- *HashAggregate(keys=[c#2], functions=[partial_count(1)], output=[c#2, count#25L])
+- *Project [c#2]
+- *Scan ComplicatedScan(1,10) [c#2] PushedFilters: [*IsNotNull(a), *GreaterThan(a,1)], ReadSchema: struct<c:string>通過Physical Plan可以看到資料來源通過PrunedFilteredScan#buildScan介面返回資料給到SparkSQL,下層的HashAggregate執行部分聚合,Exchange進行shuffle,最後由上層的HashAggregate進行最終聚合。
回到那個SparkSummit上的分享,他們實現了什麼呢?看下他們的slide,對於聚合操作是這樣的,

可以理解為將上面Physical Plan中的這一部分,
+- *HashAggregate(keys=[c#2], functions=[partial_count(1)], output=[c#2, count#25L])
+- *Project [c#2]
+- *Scan ComplicatedScan(1,10) [c#2] PushedFilters: [*IsNotNull(a), *GreaterThan(a,1)], ReadSchema: struct<c:string>替換成了CatalystSource,由資料來源來實現這個介面,

也就是說資料來源需要去解析LogicalPlan,然後實現部分聚合。
這個方案在SPARK-12449裡面有一番討論,最主要的問題是,對於資料來源來說,實現CatalystSource,解析LogicalPlan的成本太高,而且LogicalPlan是SparkSQL內部的資料結構,如果暴露給資料來源,API compatibility會是一個大問題。
如何實現聚合下推
那麼我們又是怎麼實現的呢?實際上跟上面的方案也是類似的,來看下,
spark.conf.set(SQLConf.AGGREGATION_PUSHDOWN_ENABLED.key, true)
println("==========AGGREGATION_PUSHDOWN_ENABLED==========")
df = spark.sql("SELECT count(*) FROM tt WHERE a>1 GROUP BY c")
println(df.queryExecution)
// scalastyle:on printlnAGGREGATION_PUSHDOWN_ENABLED是增加的一個配置項。輸出如下,
==========AGGREGATION_PUSHDOWN_ENABLED==========
INFO SparkSqlParser: Parsing command: SELECT count(*) FROM tt WHERE a>1 GROUP BY c
== Parsed Logical Plan ==
'Aggregate ['c], [unresolvedalias('count(1), None)]
+- 'Filter ('a > 1)
+- 'UnresolvedRelation `tt`
== Analyzed Logical Plan ==
count(1): bigint
Aggregate [c#2], [count(1) AS count(1)#27L]
+- Filter (a#0 > 1)
+- SubqueryAlias tt
+- Relation[a#0,b#1L,c#2,d#3,e#4,g#5,f#6,i#7,j#8] ComplicatedScan(1,10)
== Optimized Logical Plan ==
Aggregate [c#2], [count(1) AS count(1)#27L]
+- Project [c#2]
+- Filter (isnotnull(a#0) && (a#0 > 1))
+- Relation[a#0,b#1L,c#2,d#3,e#4,g#5,f#6,i#7,j#8] ComplicatedScan(1,10)
== Physical Plan ==
*HashAggregate(keys=[c#2], functions=[count(1)], output=[count(1)#27L])
+- Exchange hashpartitioning(c#2, 200)
+- *Scan ComplicatedScan(1,10) [c#2,count#31L] AggregateFunctions: [CountStar()], GroupingColumns: [c], PushedFilters: [*IsNotNull(a), *GreaterThan(a,1)]通過Physical Plan可以看到,資料來源通過AggregatedFilteredScan#buildScan直接返回了部分聚合的結果。這個AggregatedFilteredScan是我新增的一個介面,定義如下,
/**
* A BaseRelation that can perform aggregation and filter using selected predicates.
*
* Row fields MUST be as below:
* ([GroupingColumn1, GroupingColumn2 ... ,]
* AggregateFunction1Result[, AggregateFunction2Result ...])
*/
@InterfaceStability.Unstable
trait AggregatedFilteredScan {
def buildScan(groupingColumns: Array[String],
aggregateFunctions: Array[AggregateFunc],
filters: Array[Filter]): RDD[Row]
}相比於CatalystSource,實現AggregatedFilteredScan非常簡單,SparkSQL會將Filter,GroupBy欄位以及聚合函式直接下推給到資料來源,資料來源根據這些資訊執行聚合操作並返回聚合結果就可以了。
OK,上面只是直接展示了實現的結果,還沒有說到是如何實現的。不過實際上也已經看到了,要實現下推主要就是需要修改SparkSQL的Physical Plan的生成邏輯,也就是SparkPlanner。這裡有必要先介紹下SparkSQL大致的執行流程,如下圖,
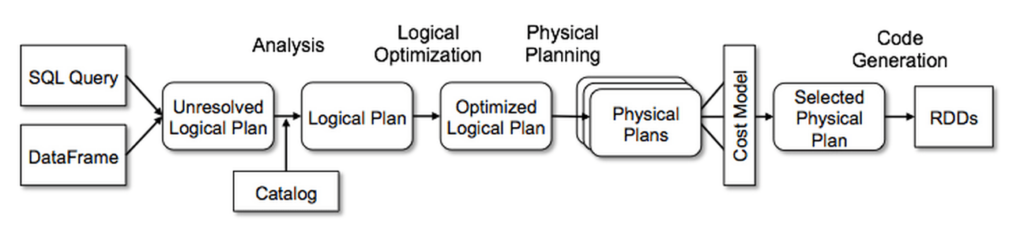
SparkSQL基於ANTLRv4的SQL Parser(語法檔案戳這裡)將SQL查詢轉換成Unresolved Logical Plan,此時的表,欄位都是unresolved的;然後Analyzer使用元資訊將其轉換成Resolved Logical Plan;接著SparkOptimizer進行一系列優化,包括常量摺疊,謂詞下推,Join重排等等;然後就是上面我們提到的SparkPlanner將Optimized Logical Plan轉換成Physical Plan,例如Logical Plan中有Join操作,那麼這一步就是要決定是使用HashJoin還是BroadcastJoin等最終的物理操作;圖中在Physical Plan轉換成RDD之前還有一步基於代價來選擇Physical Plan,這實際上就是Cost-Based Optimization(CBO),然而目前的SparkSQL是還沒有實現的,計劃是在2.3.0版本實現,可參考[SPARK-16026] Cost-based Optimizer framework,貌似主要是華為的同學貢獻的程式碼。OK,最後就是將Physical Plan轉換成RDD對應的API,執行RDD就可以了。囉嗦一句,RDD的樹狀結構真是天然可以match到SQL語法的樹狀結構,從這個層面來講,Spark真是太適合作為一個分散式的SQL引擎了。
回到聚合下推的實現上來,Logical Plan通過SparkPlanner轉換成Physical Plan,SparkPlanner內部基於一系列策略來完成轉換操作,
def strategies: Seq[Strategy] =
extraStrategies ++ (
FileSourceStrategy ::
DataSourceStrategy ::
DDLStrategy ::
SpecialLimits ::
Aggregation ::
JoinSelection ::
InMemoryScans ::
BasicOperators :: Nil)而我們做的其實就是通過修改Aggregation這個策略來將原本Physical Plan的這部分,
+- *HashAggregate
+- *Project
+- *Scan PrunedFilteredScan替換成Scan AggregatedFilteredScan就可以了。
完整的實現可以看看我提的這個PR。這個PR沒有得到反饋,我猜大概是因為這個issue吧:[SPARK-15689] Data source API v2,也就是2.3.0版本準備實現一套新的DataSource API,為什麼需要一套新的API?主要是兩個原因:
1. 老的API是面向行存的(RowDataSourceScanExec),並且需要進行資料來源與SparkSQL之間的資料型別轉換;
2. 老的API太過於依賴SparkSQL內部的實現,這樣一來如果SparkSQL內部要做一些大的改動,還需要考慮API的相容問題。這裡其實跟上面提到的CatalystSource暴露出LogicalPlan給資料來源是同樣的問題;
然後前幾天在微博上看到Spark PMC的一位大大說了,在2.3.0版本,SparkSQL將會原生支援聚合下推。這對Spark使用者來說是個好訊息,通過下面給出的效能對比可以看到聚合下推所帶來的效能提升。
簡單的效能對比
這是在測試環境上所做的一個簡單的效能對比,測試了多次,耗時都差不多。
聚合不下推的情況下,

下推的情況下,

- 第一條SQL,對2億條資料的count操作,效能提升了十倍以上,主要還是Hxxx本身的效能,妥妥的;
- 第二條SQL,資料量變小,2千萬左右,聚合操作增多的情況下,效能提升沒有第一條SQL那麼誇張,但是依然能有3倍多的提升;
暫時只有這麼簡單的效能對比,後面再找時間做一次完整的測試。
Limit及OrderBy下推
聚合下推實現了之後,我又如法炮製,修改SpecialLimits策略,實現了Limit及OrderBy的下推^_^
不測不知道,一測嚇一跳哈,效能提升能有幾十倍。
Limit及OrderBy不下推的情況下,

Limit及OrderBy下推的情況下,

在不下推的情況下,SparkSQL需要請求資料來源返回所有的資料,也就是2億條,然後進行排序。可想而知這是相當耗時的;而下推給到資料來源,則資料來源本地直接排序返回LIMIT條數即可。
可以猜想,資料量越大的情況下,Limit及OrderBy下推的效能提升就越大。
這塊程式碼還沒有去提交PR,等到2.3.0新版的DataSource API出來之後再看看哈。也歡迎感興趣的同學一起交流。alright,今天就先到這了,have fun ^_^