
CNN英文垃圾郵件分類(資料預處理)
整理自唐宇迪老師的視訊課程,感謝他!
本文最後會貼出所有的原始碼檔案,下文只是針對每個小點貼出程式碼進行註釋說明,可以略過。
1.思路
關於利用CNN做文字分類,其主要思想通過下面這幅圖就能夠一目瞭然。
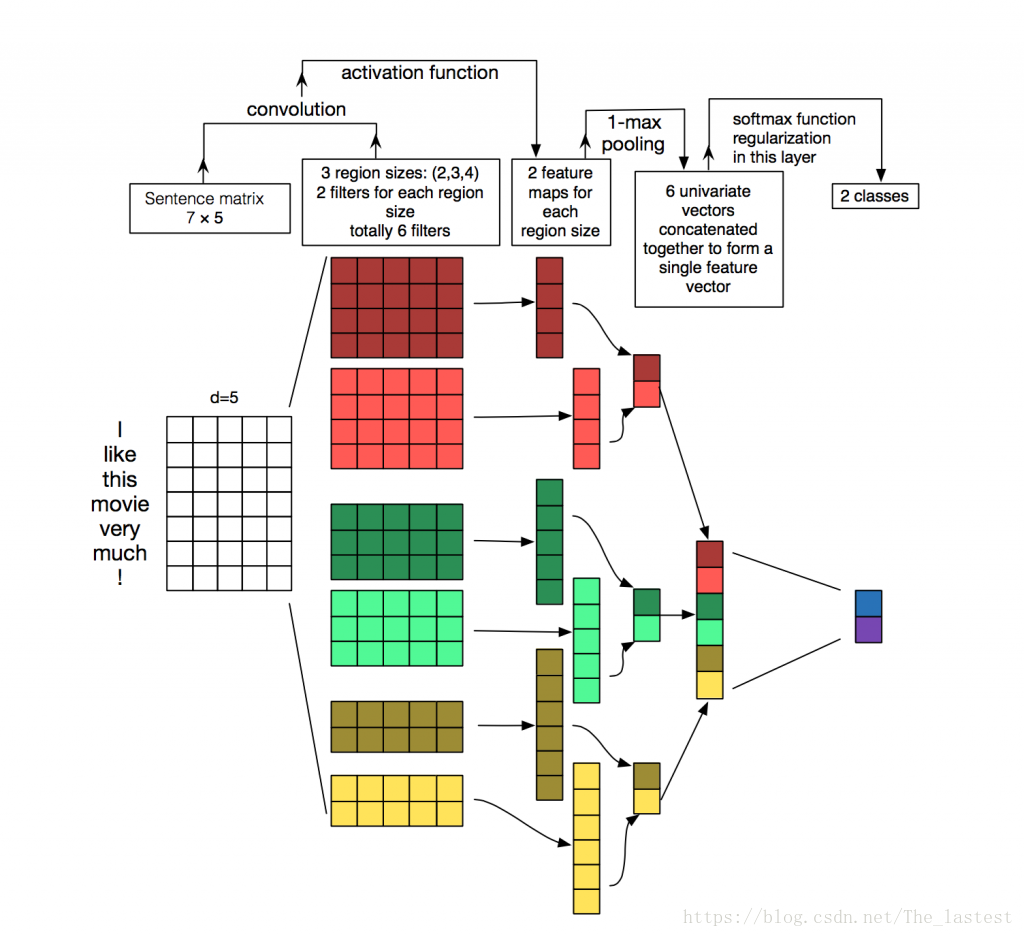
本文主要記錄了利用CNN來分類英文垃圾郵件的全過程。資料集主要包含兩個檔案:裡面分別是垃圾郵件和正常郵件,用記事本就能開啟。先來看看資料集長什麼樣:
simplistic , silly and tedious .
unfortunately the story and the actors are served with a hack script .
all the more disquieting for its relatively gore-free allusions to the serial murders , but it falls down in its attempts to humanize its subject .
a sentimental mess that never rings true .
while the performances are often engaging , this loose collection of largely improvised numbers would probably have worked better as a one-hour tv documentary .
interesting , but not compelling .
這裡展示的是其中的6封郵件,可以看到每封郵件之間是通過回車換行來分隔的,我們等下也通過這個特點來分割每一個樣本。
我們知道,在CNN文字分類中,是通過將每個單詞對應的詞向量堆疊起來,形成一個二維矩陣,以此來進行卷積和池化的。但在此處我們沒有詞向量怎麼辦呢?既然沒有,那索性就不要,把它也當做一個引數,讓它在訓練中產生。具體做法就是:
①根據所有郵件中的單詞,選取出現頻率靠前的k個或者全部(本例採用全部)產生一個長度為vocabulary_size的字典(詞表);
②隨機初始化一個大小為[vocabulary_size,embedding_size]的詞向量矩陣,embedding_size
③對於每一封郵件,找出其每個單詞在字典中對應的索引,然後按照索引從詞向量矩陣中取出對應位置的詞向量,堆疊形成表示該郵件的二維矩陣;
④為所有的郵件設定一個最大長度,即最多由多少個單詞構成,多的擷取,少的用0填充。
例如:
一封郵件內容為tomorrow is sunny,假設這三個單詞在字典中對應的索引為6,2,3,且郵件的最大長度為7;那麼我們首先得到這封郵件對應單詞的索引序列就為:56,28,97,0,0,0,0。同時初始化的詞向量矩陣為:
[[0.398 0.418 0.29 0.344 0.898 0.555 0.033 0.056 0.923] 0
[0.668 則tomorrow is sunny這封郵件對應的矩陣就為:
[[0.966 0.016 0.218 0.732 0.523 0.263 0.749 0.813 0.547] 6
[0.329 0.618 0.189 0.544 0.76 0.702 0.009 0.811 0.882] 2
[0.912 0.042 0.777 0.765 0.708 0.887 0.944 0.272 0.5 ] 3
[0.398 0.418 0.29 0.344 0.898 0.555 0.033 0.056 0.923] 0
[0.398 0.418 0.29 0.344 0.898 0.555 0.033 0.056 0.923] 0
[0.398 0.418 0.29 0.344 0.898 0.555 0.033 0.056 0.923] 0
[0.398 0.418 0.29 0.344 0.898 0.555 0.033 0.056 0.923]] 0同時,這也就對應著一個樣本。可能有人就會問,初始化的詞向量本來就不能表示每個詞,那這樣構造出來的矩陣能代表一封郵件嗎?對於這個問題可以從兩個角度來看:第一,開始可能它是不正確的,但由於我們這裡是有監督學習,只要它不正確,最後就會會產生誤差,演算法可以根據產生誤差來糾正這一錯誤,通過多次的迭代,就自然正確了;第二,雖然這個詞向量矩陣是隨機產生的,可能是錯的,但所有郵件的表示方式都是根據這個錯誤的矩陣形成的,從某種意義上來說也就是對的了,我們之所以覺得它錯了,是因為我們找不到一種度量方式來說明它是對的。咳,扯遠了……
2 預處理
有了上面的總體思路,我們下面就細緻的來對郵件進行預處理。
2.1 構造資料集
一次讀入所有郵件(為一個字串),按’\n’作為分割符分開,並去掉每個樣本前後的空格。
positive = open(positive_data_file, 'rb').read().decode('utf-8') # 得到一個字串,因為含有中文所以加decode('utf-8')
negative = open(negative_data_file, 'rb').read().decode('utf-8')
positive_examples = positive.split('\n')[:-1] # 將整個文字用換行符分割成一個一個的郵件
negative_examples = negative.split('\n')[:-1] # 得到的是一個list,list中的每個元素都是一封郵件(並且去掉最後一個換行符,[:-1]表示去掉最後一個元素)
positive_examples = [s.strip() for s in positive_examples] # 去掉每個郵件開頭和結尾的的空格
negative_examples = [s.strip() for s in negative_examples]
x_text = positive_examples + negative_examples # 兩個列表相加構成資料集
x_text = [clean_str(sent) for sent in x_text] # 去除每個郵件中的標點等無用的字元其中函式clean_str()是去除每個樣本(郵件)中的其它字元。
處理完後如下(前3個):
[“the rock is destined to be the 21st century ‘s new conan and that he ‘s going to make a splash even greater than arnold schwarzenegger , jean claud van damme or steven segal”, “the gorgeously elaborate continuation of the lord of the rings trilogy is so huge that a column of words cannot adequately describe co writer director peter jackson ‘s expanded vision of j r r tolkien ‘s middle earth”, ‘effective but too tepid biopic’]
2.2 構造標籤
positive_label = [[0, 1] for _ in positive_examples] # 構造one-hot 標籤[[0, 1], [0, 1], [0, 1], [0, 1],....]
negative_label = [[1, 0] for _ in negative_examples]對於每個樣本,我們用One-hot的形式進行標籤化處理,結果這樣處理後的結果如下:
print(positive_label[:5])
[[0, 1], [0, 1], [0, 1], [0, 1], [0, 1]]同理,負樣本的標籤也是如此。接著就是將兩者合併到一起:
y = np.concatenate([positive_label, negative_label], axis=0)其中axis=0表示縱向堆疊,結果如下:
print(y[:5])
[[0 1]
[0 1]
[0 1]
[0 1]
[0 1]]2.3 數字化資料集
所謂數字化資料集就是我們在第一部分中說道的,先建立一個字典,然後找到每個郵件中的單詞在字典中對應的索引。好在TensorFlow已經為我們提供了這麼一個模組from tensorflow.contrib import learn,讓我們可以方便的得到這些。
首先我們取郵件中最長單詞數作為每封郵件的長度(不足的按0填充)
max_document_length = max([len(x.split(' ')) for x in x_text])本例中max_document_length=56,也就代表著每封郵件都按56個單詞處理。
接著:
vocab_processor = learn.preprocessing.VocabularyProcessor(max_document_length)
x = np.array(list(vocab_processor.fit_transform(x_text))) # 得到每個樣本中,每個單詞對應在詞典中的序號
print(x[:3])
#
[[ 1 2 3 4 5 6 1 7 8 9 10 11 12 13 14 9 15 5 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 1 31 32 33 34 1 35 34 1 36 37 3 38 39 13 17 40 34 41 42 43 44 45 46 47 48 49 9 50 51 34 52 53 53
54 9 55 56 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]2.4 打亂資料並構造訓練集和測試集
到目前為止,我們已經將郵件轉化成了一個數字化的表現形式;但此時所有的樣本都是正負樣本密集聚在一起的,所有要先將其打亂。
np.random.seed(10)# 生成一個種子
shuffle_indices = np.random.permutation(np.arange(len(y)))#產生隨機數
x_shuffled = x[shuffle_indices] # 打亂資料
y_shuffled = y[shuffle_indices]
dev_sample_index = -1 * int(0.2 * float(len(y)))
x_train, x_dev = x_shuffled[:dev_sample_index], x_shuffled[dev_sample_index:]
y_train, y_dev = y_shuffled[:dev_sample_index], y_shuffled[dev_sample_index:] # 劃分訓練集和驗證集此時,經過上面一系列的處理,我們已經得到了每封郵件每個單詞對應的索引序列,和其對應的標籤,並進行了打亂。
接著在下面一篇博文中,我們就開始進行二維矩陣的構造,然後卷積,池化全連線等。