
Storm 簡介及元件的基本概念
如果需要實現一個實時計算系統
全量資料處理使用的大多是鼎鼎大名的hadoop或者hive,作為一個批處理系統,hadoop以其吞吐量大、自動容錯等優點,在海量資料處理上得到了廣泛的使用。但是,hadoop不擅長實時計算,因為它天然就是為批處理而生的,這也是業界一致的共識。否則最近這兩年也不會有s4, Storm ,puma這些實時計算系統如雨後春筍般冒出來啦。先拋開s4, Storm ,puma這些系統不談,我們首先來看一下,如果讓我們自己設計一個實時計算系統,我們要解決哪些問題。
● 低延遲。都說了是實時計算系統了,延遲是一定要低的。
● 高效能。效能不高就是浪費機器,浪費機器就是浪費錢。
● 分散式。系統都是為應用場景而生的,如果你的應用場景、你的資料和計算單機就能搞定,那麼不用考慮這些複雜的問題了。我們所說的是單機搞不定的情況。
● 可擴充套件。伴隨著業務的發展,我們的資料量、計算量可能會越來越大,所以希望這個系統是可擴充套件的。
● 容錯。這是分散式系統中通用問題。一個節點掛了不能影響我的應用。
好,如果僅僅需要解決這5個問題,可能會有無數種方案,而且各有千秋,隨便舉一種方案,使用訊息佇列+分佈在各個機器上的工作程序就可以了。
1. 容易在上面開發應用程式。你設計的系統需要應用程式開發人員考慮各個處理元件的分佈、訊息的傳遞嗎?如果是,那有點麻煩啊,開發人員可能會用不好,也不會想去用。
2. 訊息不丟失。使用者釋出的一個寶貝訊息不能在實時處理的時候給丟了,對吧?更嚴格一點,如果是一個精確資料統計的應用,那麼它處理的訊息要不多不少才行。這個要求有點高。
3. 訊息嚴格有序。有些訊息之間是有強相關性的,比如同一個寶貝的更新和刪除操作訊息,如果處理時搞亂順序完全是不一樣的效果了。
不知道大家對這些問題是否都有了自己的答案,下面讓我們帶著這些問題,一起來看一看 Storm 的吧。
Storm 是什麼
如果只用一句話來描述 Storm 的話,可能會是這樣:分散式實時計算系統。按照 Storm 作者的說法, Storm 對於實時計算的意義類似於hadoop對於批處理的意義。我們都知道,根據google mapreduce來實現的hadoop為我們提供了map、reduce原語,使我們的批處理程式變得非常地簡單和優美。同樣, Storm 也為實時計算提供了一些簡單優美的原語。我們會在第三節中詳細介紹。
我們來看一下 Storm 的適用場景。
1.流資料處理:Storm可以用來用來處理源源不斷的訊息,並將處理之後的結果儲存到資料庫中。
2.連續計算:Storm可以進行連續查詢並把結果即時反饋給客戶,比如將熱門話題傳送到客戶端,網站指標等。
3.分散式RPC
Storm 中的一些概念
首先我們通過一個 Storm 和 hadoop 的對比來了解 Storm 中的基本概念。

接下來我們再來具體看一下這些概念。
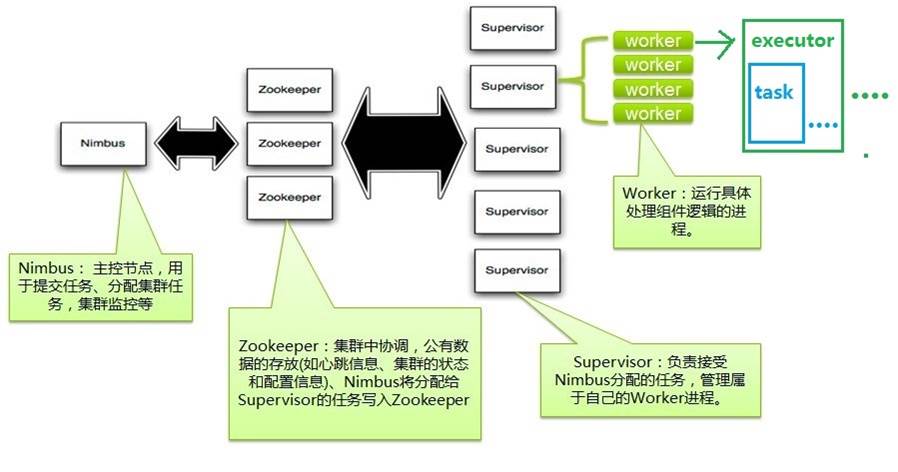
1. Nimbus:負責資源分配和任務排程。
2. Supervisor:負責接受nimbus分配的任務,啟動和停止屬於自己管理的worker程序。
3. Worker:執行具體處理元件邏輯的程序。
4. Task:worker中每一個 Spout /bolt的執行緒稱為一個task. 在 Storm 0.8之後,task不再與物理執行緒對應,同一個 Spout /bolt的task可能會共享一個物理執行緒,該執行緒稱為executor。
下面這個圖描述了以上幾個角色之間的關係:
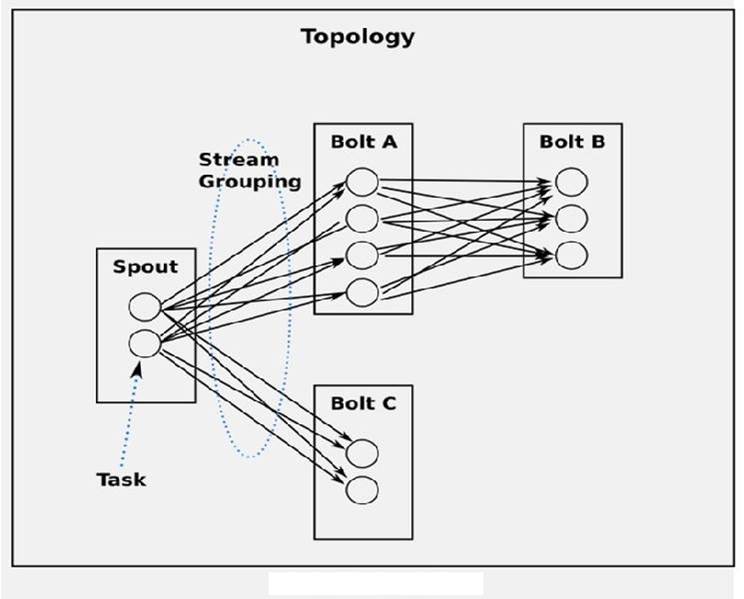
5,Topology: Storm 中執行的一個實時應用程式,因為各個元件間的訊息流動形成邏輯上的一個拓撲結構。
6, Spout:在一個topology中產生源資料流的元件。通常情況下 Spout 會從外部資料來源中讀取資料,然後轉換為topology內部的源資料。 Spout 是一個主動的角色,其介面中有個nextTuple()函式, Storm 框架會不停地呼叫此函式,使用者只要在其中生成源資料即可。
7,Bolt:在一個topology中接受資料然後執行處理的元件。Bolt可以執行過濾、函式操作、合併、寫資料庫等任何操作。Bolt是一個被動的角色,其介面中有個execute(Tuple input)函式,在接受到訊息後會呼叫此函式,使用者可以在其中執行自己想要的操作。
8, Tuple:一次訊息傳遞的基本單元。
9,Stream:源源不斷傳遞的tuple就組成了stream。
10,Stream Grouping:即訊息的partition方法。流分組策略告訴topology如何在兩個元件之間傳送tuple。 Storm 中提供若干種實用的grouping方式,包括shuffle, fields hash, all, global, none, direct和localOrShuffle等。
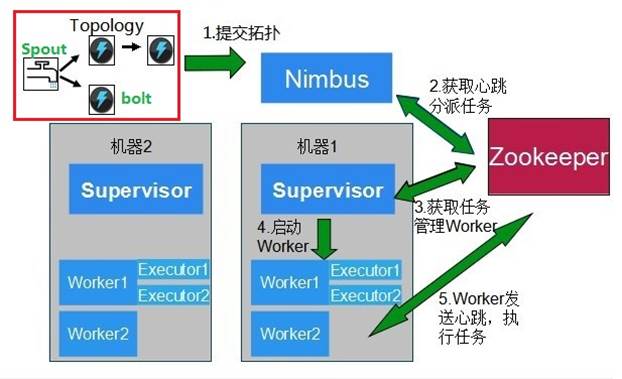
執行中的Topology :
•執行中的Topology主要由以下三個元件組成的:
•Worker processes(程序)
•Executors (threads)(執行緒)
•Tasks
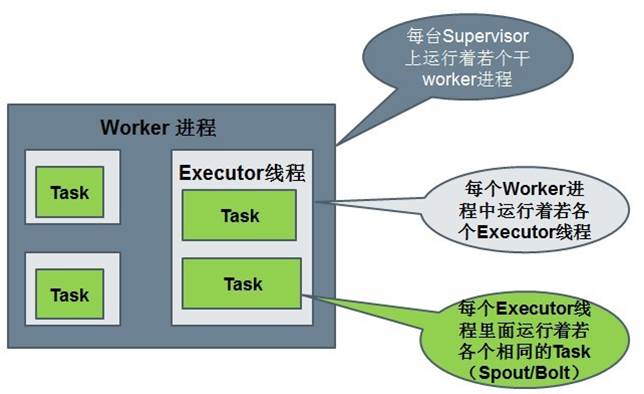
Stream的概念
•Stream是storm裡面的關鍵抽象。一個stream是一個沒有邊界的tuple序列。storm提供一些原語來分散式地、可靠地把一個stream傳輸進一個新的stream。
•通常Spout會從外部資料來源(佇列、資料庫等)讀取資料,然後封裝成Tuple形式,之後傳送到Stream中,bolt可以接收任意多個輸入stream, 作一些處理, 有些bolt可能還會發射一些新的stream
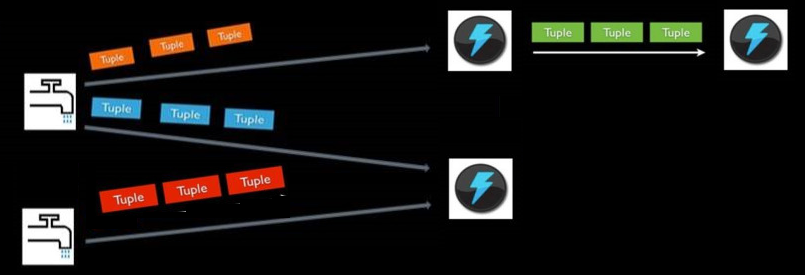
Stream Grouping
定義topology的很重要的一部分就是定義資料流資料流應該傳送到那些bolt中。資料流分組就是將資料流進行分組,按需要進入不同的bolt中。可以使用Storm提供的分組規則,也可以實現backtype.storm.grouping.CustomStreamGrouping自定義分組規則。Storm定義了8種內建的資料流分組方法:
1. Shuffle grouping(隨機分組):隨機分發tuple給bolt的各個task,每個bolt例項接收到相同數量的tuple;
2. Fields grouping(按欄位分組):根據指定欄位的值進行分組。比如,一個數據流按照”user-id”分組,所有具有相同”user-id”的tuple將被路由到同一bolt的task中,不同”user-id”可能路由到不同bolt的task中;
3. Partial Key grouping(部分key分組):資料流根據field進行分組,類似於按欄位分組,但是將在兩個下游bolt之間進行均衡負載,當資源發生傾斜的時候能夠更有效率的使用資源。
4. All grouping(全複製分組):將所有tuple複製後分發給所有bolt的task。小心使用。
5. Global grouping(全域性分組):將所有的tuple路由到唯一一個task上。Storm按照最小的task ID來選取接收資料的task;(注意,當時用全域性分組是,設定bolt的task併發是沒有意義的,因為所有tuple都轉發到一個task上。同時需要注意的是,所有tuple轉發到一個jvm例項上,可能會引起storm叢集某個jvm或伺服器出現效能瓶頸或崩潰)
6. None grouping(不分組):這種分組方式指明不需要關心分組方式。實際上,不分組功能與隨機分組相同。預留功能。
7. Direct grouping(指向型分組):資料來源會呼叫emitDirect來判斷一個tuple應該由哪個storm元件接收,只能在聲明瞭指向型的資料流上使用。
8. Local or shuffle grouping(本地或隨機分組):當同一個worker程序中有目標bolt,將把資料傳送到這些bolt中。否則,功能將與隨機分組相同。該方法取決與topology的併發度,本地或隨機分組可以減少網路傳輸,降低IO,提高topology效能。