
【嵌入式基礎】嵌入式軟體開發:筆試總結
從CSDN各個部落格上摘選的一些容易做錯的嵌入式軟體的筆試題,做一下記錄,讓自己記住。
程式語言的基礎考察
1、以下程式碼執行結果為:
#include <iostream>
using namespace std;
int func(int x)
{
int count=0;
while(x)
{
count++;
x=x&(x-1);
}
return count;
}
int main()
{
cout<<(9867)<<endl;
return 0;
}解答:本題func函式返回值是形參x轉化成二進位制後包含1的數量。理解這一點很容易解答出來。是因為x&(x-1)每執行一次就會消去一個1,這樣只要判斷x的二進位制有多少個1就可以了。
ARM嵌入式的相關基本概念
2、簡述一下boot loader的作用。
解答:在一般情況下嵌入式Linux系統中的軟體主要分為以下及部分:
- 引導載入程式: 其中包括內部ROM中的固化啟動程式碼和Boot Loader兩部分。而這個內部固化ROM是廠家在晶片生產時候固化的,作用基本上是引導Boot Loader。有的晶片比較複雜,比如Omap3,它在flash中沒有程式碼的時候有許多啟動方式:USB、UART或乙太網等等。而S3C24x0則很簡單,只有Norboot和Nandboot;
- Linux kernel 和drivers;
- 檔案系統。 包括根檔案系統和建立於Flash記憶體裝置之上的檔案系統(EXT4、UBI、CRAMFS等等)。它是提供管理系統的各種配置檔案以及系統執行使用者應用程式的良好執行環境的載體;
- 應用程式。 使用者自定義的應用程式,存放於檔案系統之中。
在嵌入式Linux中為什麼要有BootLoader?
在linux核心的啟動執行除了核心映像必須在主存的適當位置(作業系統檔案的來源,可以是flash、sd card、PC(可以通過網路,USB,甚至串列埠傳輸)等等,所謂的EBOOT、UBOOT,其實就是表明了系統檔案是通過Ethernet或者USB從PC傳輸過去的。),CPU還必須具備一定的條件:
| CPU 暫存器的設定 | R0=0; R1=Machine ID(即Machine Type Number,定義在linux/arch/arm/tools/mach-types); R2=核心啟動引數在 RAM 中起始基地址; |
| CPU 模式 | 必須禁止中斷(IRQs和FIQs); CPU 必須 SVC 模式; |
| Cache和MMU的設定 | MMU 必須關閉; 指令 Cache 可以開啟也可以關閉; 資料 Cache 必須關閉; |
但是在CPU剛上電啟動的時候,一般連記憶體控制器都沒有配置過,根本無法在記憶體中執行程式,更不可能處在Linux核心的啟動環境中。為了把作業系統映像檔案拷貝到RAM中去、初始化CPU及其他外設,然後跳轉到它的入口處去執行,使得Linux核心可以在系統主存中跑起來,並讓系統符合Linux核心啟動的必備條件,必須要有一個先於核心執行的程式,他就是所謂的引導載入程式(Boot Loader)。
而Boot Loader並不是Linux才需要,是幾乎所有的執行作業系統的裝置都具備的。
Boot Loader的功能和選擇 :
通過上面的講述,我們可以知道:Boot Loader是在作業系統核心執行之前執行的一段小程式。通過這段小程式,我們可以初始化硬體裝置,從而將系統的軟硬體環境帶到一個合適的狀態,以便為最終呼叫作業系統核心準備好正確的環境,最後從別處(Flash、乙太網、UART)載入核心映像並跳到入口地址。
由於BootLoader直接操作硬體,所以它嚴重依賴於硬體,而且依據所引導的作業系統的不同,也有不同的選擇對於嵌入式世界中更是如此。所以在嵌入式世界中建立一個通用的 BootLoader 幾乎是不可能的,而有可能的是讓一個 Boot Loader程式碼支援多種不同的構架和作業系統,並讓它方便移植。
3、簡述一下嵌入式處理器的分類。
嵌入式系統中的處理器可以分成下面四大類類:
- 嵌入式微處理器(MPU):它是由計算機中的CPU演變而來。它的特徵是具有32位以上的處理器,具有較高的效能,價格也相對比較昂貴。但與計算機處理器不同的不是,它保留和嵌入式應用緊密相關的功能硬體,去除其他的冗餘功能部分,這樣就以最低的功耗和資源實現嵌入式應用的特殊要求;
- 嵌入式微控制器(MCU):其典型代表是微控制器;
- 嵌入式DSP處理器(DSP):專門處理訊號方面的處理器,其系統結構和指令演算法方面進行了特殊的設計。具有很高的編譯效率和程式碼執行能力。在數字濾波、FFT、譜分析等各種儀器上DSP獲得了大規模的運用;
- 嵌入式片上系統(SOC):一般來說稱之為系統晶片。它是一個產品,是一個有專用目標的積體電路。其中包含完整系統和嵌入軟體的全部。從廣義上而言,SOC是一個微小型系統,如果說CPU是大腦,那麼SOC就包括大腦、眼睛和鼻子等。
4、嵌入式交叉編譯環境有哪兩部分組成?簡述交叉編譯過程。
- 本地編譯可以理解為,在當前編譯平臺下,編譯出來的程式只能放到當前平臺下執行。平時我們常見的軟體開發,都是屬於本地編譯;
- 交叉編譯可以理解為,在當前編譯平臺下,編譯出來的程式能執行在體系結構不同的另一種目標平臺上,但是編譯平臺本身卻不能執行該程式。
以Linux-arm而言,我們在PC上開發的程式,只能夠在Linux平臺上能夠執行,那我們的終極目的是能夠在ARM產品上進行執行。對於這種跨平臺而言,就需要交叉編譯工具(arm-linux-gcc)進行編譯,這樣的程式碼才能夠在ARM上進行執行。
至於為什麼進行交叉編譯?
- Speed: 目標平臺的執行速度往往比主機慢得多,許多專用的嵌入式硬體被設計為低成本和低功耗,沒有太高的效能;
- Capability: 整個編譯過程是非常消耗資源的,嵌入式系統往往沒有足夠的記憶體或磁碟空間;
- Availability: 即使目標平臺資源很充足,可以本地編譯,但是第一個在目標平臺上執行的本地編譯器總需要通過交叉編譯獲得;
- Flexibility: 一個完整的Linux編譯環境需要很多支援包,交叉編譯使我們不需要花時間將各種支援包移植到目標板上。
整個編譯過程包括了預處理、編譯、彙編、連結等功能。既然有不同的子功能,那每個子功能都是一個單獨的工具來實現,它們合在一起形成了一個完整的工具集。同時編譯過程又是一個有先後順序的流程,它必然牽涉到工具的使用順序,每個工具按照先後關係串聯在一起,這就形成了一個鏈式結構。
因此,交叉編譯鏈就是為了編譯跨平臺體系結構的程式程式碼而形成的由多個子工具構成的一套完整的工具集,一般由編譯器、聯結器、直譯器和偵錯程式組成。同時,它隱藏了預處理、編譯、彙編、連結等細節,當我們指定了原始檔(.c)時,它會自動按照編譯流程呼叫不同的子工具,自動生成最終的二進位制程式映像(.bin)。
交叉編譯的基本過程,用一個圖來詳解一下:

5、ARM的體系要點。
Linux系統相關知識
6、給了一個TCP/IP的通訊例程,畫出socket通訊的流程圖。
解答:網路程式設計中,一般是服務端程式先啟動,等待客戶端程式啟動並連線,一般來說在服務端程式在一個埠上監聽,直到有一個客戶端的程式發來了請求。如果沒有客戶端程式傳送請求,則服務端程式會一直阻塞。直到客戶端程式發來請求為止。
在網路程式設計主要會有三個方面:基於TCP/IP協議的網路程式設計、基於UDP/IP協議的網路程式設計、併發伺服器程式設計。
關於TCP客戶伺服器程式設計的基於TCP連線的socket程式設計流程圖如下圖:
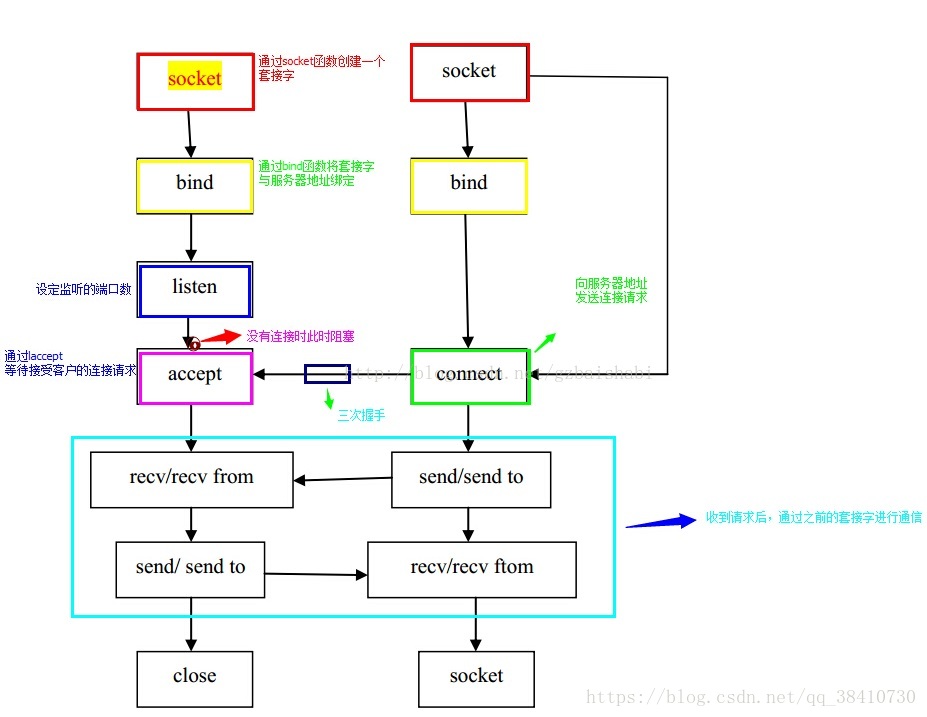
演示了 Linux 下的程式碼,server.cpp 是伺服器端程式碼,client.cpp 是客戶端程式碼,要實現的功能是:客戶端從伺服器讀取一個字串並打印出來。
伺服器端程式碼 server.cpp:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <netinet/in.h>
int main(){
//建立套接字
int serv_sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
//將套接字和IP、埠繫結
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof(serv_addr)); //每個位元組都用0填充
serv_addr.sin_family = AF_INET; //使用IPv4地址
serv_addr.sin_addr.s_addr = inet_addr("127.0.0.1"); //具體的IP地址
serv_addr.sin_port = htons(1234); //埠
bind(serv_sock, (struct sockaddr*)&serv_addr, sizeof(serv_addr));
//進入監聽狀態,等待使用者發起請求
listen(serv_sock, 20);
//接收客戶端請求
struct sockaddr_in clnt_addr;
socklen_t clnt_addr_size = sizeof(clnt_addr);
int clnt_sock = accept(serv_sock, (struct sockaddr*)&clnt_addr, &clnt_addr_size);
//向客戶端傳送資料
char str[] = "Hello World!";
write(clnt_sock, str, sizeof(str));
//關閉套接字
close(clnt_sock);
close(serv_sock);
return 0;
}客戶端程式碼 client.cpp:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/socket.h>
int main(){
//建立套接字
int sock = socket(AF_INET, SOCK_STREAM, 0);
//向伺服器(特定的IP和埠)發起請求
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof(serv_addr)); //每個位元組都用0填充
serv_addr.sin_family = AF_INET; //使用IPv4地址
serv_addr.sin_addr.s_addr = inet_addr("127.0.0.1"); //具體的IP地址
serv_addr.sin_port = htons(1234); //埠
connect(sock, (struct sockaddr*)&serv_addr, sizeof(serv_addr));
//讀取伺服器傳回的資料
char buffer[40];
read(sock, buffer, sizeof(buffer)-1);
printf("Message form server: %s\n", buffer);
//關閉套接字
close(sock);
return 0;
}先編譯 server.cpp 並執行:
[[email protected] ~]$ g++ server.cpp -o server
[[email protected] ~]$ ./server
|正常情況下,程式執行到 accept() 函式就會被阻塞,等待客戶端發起請求。 接下來編譯 client.cpp 並執行:
[[email protected] ~]$ g++ client.cpp -o client
[[email protected] ~]$ ./client
Message form server: Hello World!
[[email protected] ~]$client 執行後,通過 connect() 函式向 server 發起請求,處於監聽狀態的 server 被啟用,執行 accept() 函式,接受客戶端的請求,然後執行 write() 函式向 client 傳回資料。client 接收到傳回的資料後,connect() 就執行結束了,然後使用 read() 將資料讀取出來。
需要注意的是:
- server 只接受一次 client 請求,當 server 向 client 傳回資料後,程式就執行結束了。如果想再次接收到伺服器的資料,必須再次執行 server,所以這是一個非常簡陋的 socket 程式,不能夠一直接受客戶端的請求;
- 上面的原始檔字尾為.cpp,是C++程式碼,所以要用g++命令來編譯。