
深入理解計算機系統_第零部分_第一章_計算機系統漫遊
深入,並且廣泛
-沉默犀牛
寫在前面
今天是2018/12/14,還有一週我的實習期就結束了,發現自己的基礎特別薄弱,選了幾本提升基礎的書籍,《深入理解計算機系統》是我將要看的第一本書,特別開這個系列文章,記錄所學所得所想,也用作檢驗自己學習進度的指標之一。
PS:大部分是摘抄書中原話,[]方括號中的內容是自己所想所得。
文章導讀
這一章漫遊式的介紹了計算機系統。
- 資訊就是位+上下文
- 程式被其他程式翻譯成不同的格式:介紹了
源程式經過哪些步驟成為可執行目標程式的 - 瞭解編譯系統如何工作是大有益處的
- 處理器讀並解釋儲存在記憶體中的指令
4.1 系統的硬體組成:介紹了匯流排、I/O裝置、主存、處理器的概念和它們的聯絡
4.2 執行hello程式:介紹了hello程式執行的時候在機器裡面發生了什麼 - 快取記憶體至關重要:介紹了快取記憶體是什麼以及它的重要性
- 儲存裝置形成層級結構:按照從儲存裝置中的讀取速度劃分了層次結構
- 作業系統管理硬體:介紹了作業系統的基本功能和三個抽象表示
7.1 程序:介紹了程序的概念和程序切換時機器做了什麼
7.2 執行緒:介紹了執行緒的概念
7.3 虛擬記憶體:介紹了虛擬記憶體的概念和其中各個區的功能
7.4 檔案:介紹了檔案的概念 - 系統之間利用網路通訊:介紹了各個系統如何通過網路聯絡起來
- 重要主題:介紹了系統是硬體軟體交織的集合體
9.1 Amdahl定律:介紹了這一提高計算機整體效能的定律
9.2 併發和並行:介紹了併發和並行概念和三種並行方式
9.3 計算機系統中抽象的重要性 - 小結
計算機系統漫遊
所有的計算機都有相似的硬體和軟體結構,它們又執行著相似的功能。這本書就是為了那些希望深入瞭解這些元件如何工作以及這些元件是如何影響程式的正確性和效能的程式設計師而寫的。
以下將以一個hello程式的生命週期來開始對系統的學習——從它被程式設計師建立開始,到在系統上執行,輸出簡單的訊息,然後終止。我們將沿著這個生命週期,簡要的介紹一些逐步出現的關鍵概念,專業術語和組成部分。
#include <stdio.h>
int main()
{
printf("hello,world \n");
return 0;
}
[以前從未考慮過類似於此的問題,大學時只是簡單的編譯一下看到輸出結果就很開心了,現在來了解一下它的生命週期。]
1.1 資訊就是位+上下文
hello程式的生命週期是從一個源程式(或者說原始檔)開始的,即程式設計師通過編輯器建立並儲存的文字檔案,檔名是hello.c。源程式實際上就是一個由值0和1組成的位(又稱為位元)序列,8個位被組織成一組,成為位元組。每個位元組表示程式中的某些文字字元。
所以hello程式是以位元組序列的方式儲存的檔案中的。每個位元組都有一個整數值,對應於某些字元。例如第一個位元組的整數值為35,它對應的字元是"#",第二個位元組的整數值為105,它對應的字元是"i"。像hello.c這樣只由ASCII字元構成的文字稱為文字檔案,其他所有的檔案都稱為二進位制檔案。
- hello.c的表示方法說明了一個基本思想:系統中的所有資訊——包括磁碟檔案、記憶體中的程式、記憶體中存放的使用者資料以及網路上傳輸的資料,都是有一串位元表示的。區分不同資料物件的唯一方法是我們讀到這些資料物件時的
上下文。比如,在不同的上下文中,一個同樣的位元組序列可能表示為一個整數,浮點數,字串或者機器指令。
[看這些內容的時候,想到了一個生活中類比的事情(也與我最近在看哲學書籍有關):假設有外在存在的世界(位),這個世界在不同的人眼中看,反射出來的就是不一樣的(這裡暫不討論陽明心學中的吾心光明,只討論西方哲學思想),如果我相信世界是消極的,是無序的,是黑暗的(上下文),那麼世界在我這裡反射出來的就是消極的,無序的,黑暗的(資訊),如果我相信世界是積極的,是有序的,是光明的(上下文),那麼世界在我這裡反射出來的就是積極的(資訊)。]
1.2 程式被其他程式翻譯成不同的格式
hello程式的生命週期是從一個高階C語言程式開始的(因為這種形式能夠被人讀懂)。然而,為了在系統上執行hello.c程式,每條C語句都必須被其他程式轉化為一系列的低階機器語言指令。然後這些執行按照一種稱為可執行目標程式的格式打好包,並且以二進位制磁碟檔案的形式存放起來,目標程式也稱為可執行目標檔案。
GCC編譯器驅動程式讀取原始檔hello.c,並把它翻譯成一個可執行目標檔案hello。翻譯過程如下圖:

- 預處理階段:前處理器(cpp)根據以字元#開頭!的命令,修改原始的C程式。比如hello.c中的第一行 #include <stdio.h> 命令告訴前處理器讀取系統標頭檔案stdio.h的內容,並把它直接插入程式文字中。結果得到了另一個C程式,通常以.i作為副檔名。
- 編譯階段:編譯器(ccl)將文字檔案hello.i翻譯成文字檔案hello.s,它包含一個
組合語言程式。 - 彙編階段:彙編器(as)將hello.s翻譯成
機器指令語言,把這些指令打包為一種叫做可重定位目標程式(relocatable object program)的格式,並將結果儲存在目標檔案hello.o中。 - 連結階段:hello程式呼叫的printf函式,printf函式存在一個名為printf.o的單獨的預編譯好了的目標檔案中,而這個檔案必須以某種方式合併到我們的hello.o程式中。連結器(ld)就負責處理這種合併。結果就得到了hello檔案,它是一個
可執行目標檔案(或可執行檔案),可以被載入到記憶體中,由系統執行。
1.3 瞭解編譯系統如何工作是大有益處的
有一些重要的原因促使程式設計師必須知道編譯系統是如何工作的:
- 優化程式效能。比如,一個switch語句是否總是比一些列的if-else語句高效得多?一個函式呼叫的開銷有多大?while迴圈比for迴圈更有效嗎?指標引用比資料索引更有效嗎?為什麼迴圈求和的結果放到一個本地變數中,會比將其放到一個通過引用傳遞過來的引數中,執行起來快很多呢?為什麼只是簡單地重新排列一下算術表示式中括號就能讓函式執行的更快呢?
- 理解連結事出現的錯誤。比如,連結器報告說它無法解析一個引用,這是什麼意思?靜態變數和全域性變數的區別是什麼?如果你在不同的C檔案中定義了名字相同的兩個全域性變數會發生什麼?靜態庫和動態庫的區別是什麼?我們在命令列上排列庫的順序有什麼影響?最嚴重的是,為什麼有些連結錯誤直到執行時才會出現?
- 避免安全漏洞。緩衝區溢位錯誤是造成大多數網路和Internet伺服器上安全漏洞的主要原因。存在這些錯誤的因為很少有程式設計師能夠理解需要限制從不受信任的源接受資料的數量和格式。
1.4 處理器讀出並解釋儲存在記憶體中的指令
此刻,hello.c源程式已經被編譯系統翻譯成了可執行目標檔案hello,並被存放在磁碟中。想要在Unix系統上執行該可執行檔案,我們將它的檔名輸入到稱為shell的應用程式中即可。
shell是一個命令列直譯器,它輸出一個提示符,等待輸入一個命令列,然後執行這個命令。如果該命令列的第一個單詞不是一個內建的shell命令,那麼shell就會假設這是一個可執行檔案的名字,它將載入並執行這個檔案。
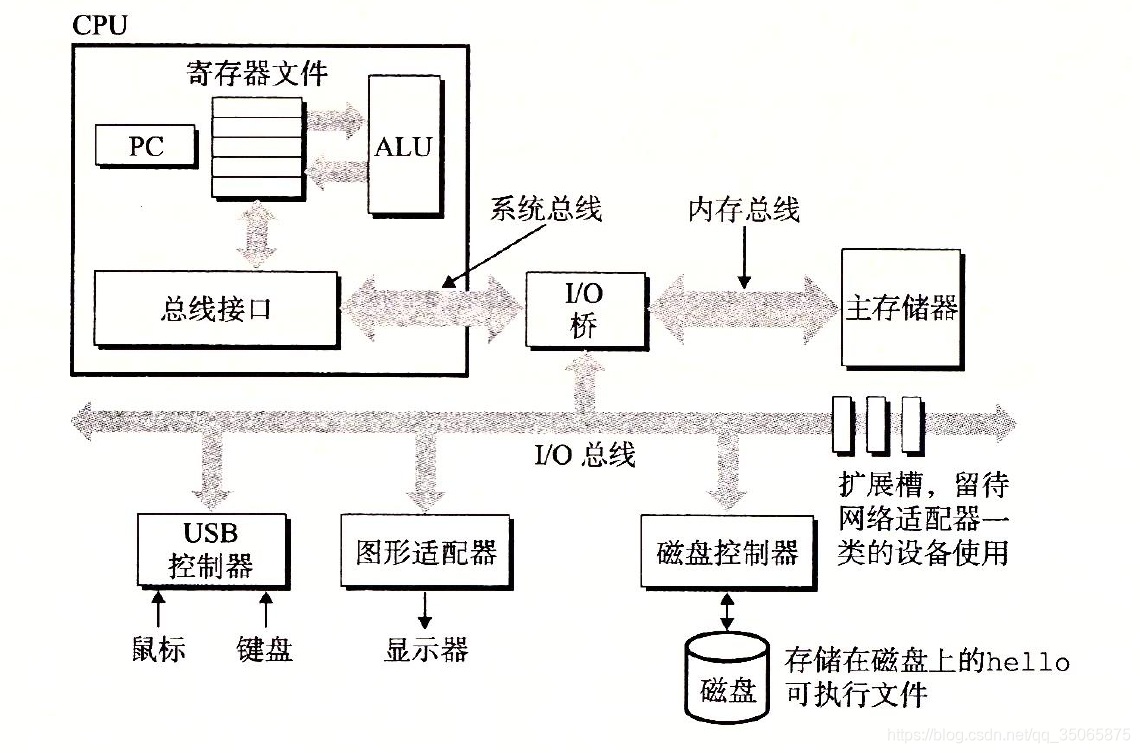
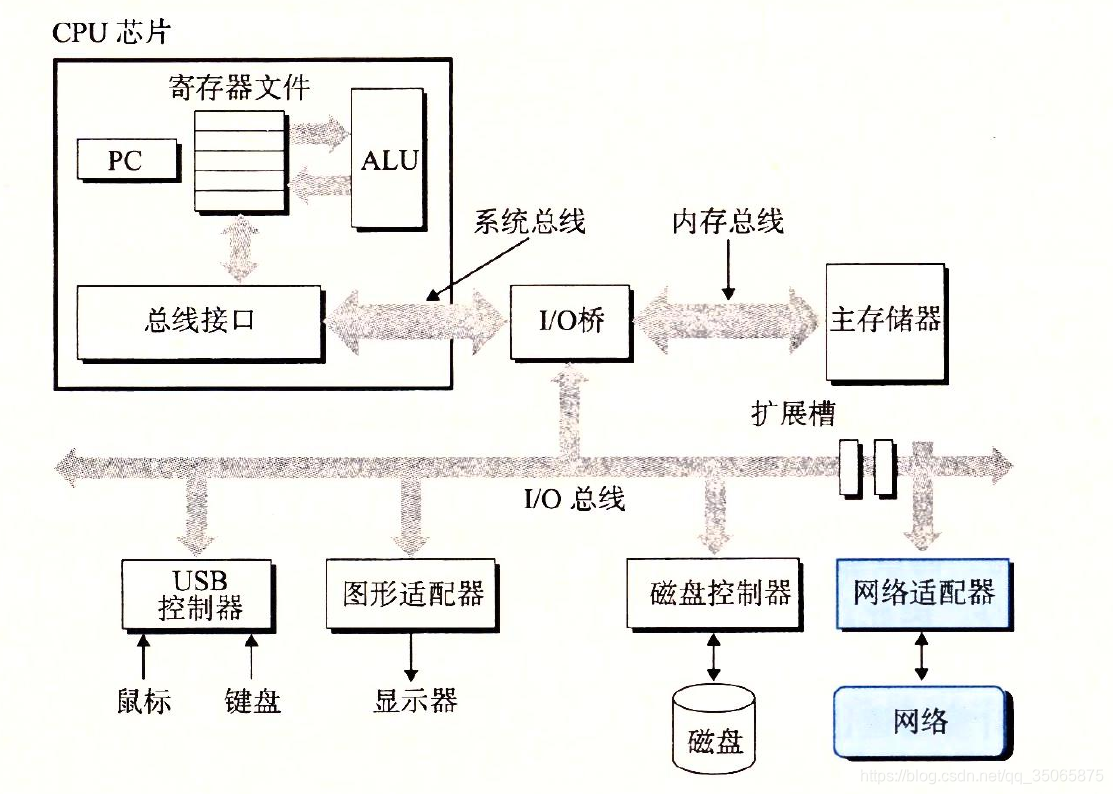
1.4.1 系統的硬體組成
這張圖是Intel系統產品族的模型,但是所有其他系統也有相同的外觀和特性。
-
匯流排。貫穿整個系統的一組電子管道,稱為匯流排,它攜帶資訊位元組並負責在各個部件間傳遞。通常匯流排被設計成傳送定長的位元組快,也就是字(Word)。字中的位元組數(即字長)是一個基本的系統引數,各個系統中都不盡相同。現在大多數機器字長要麼是4個位元組(32位),要麼是8個位元組(64位)。
-
I/O裝置。I/O裝置是系統與外部世界的聯絡通道。上圖中的示例系統包括四個I/O裝置:作為使用者輸入的鍵盤和滑鼠,作為使用者輸出的顯示器,用於長期儲存資料和程式的磁碟驅動器(簡單的說就是磁碟)。最開始,可執行程式hello就存放在磁碟上。
每個I/O裝置都通過一個控制器或者介面卡與I/O匯流排相連。控制器是I/O裝置本身或者系統的主印製電路板(通常稱為主機板)上的晶片組,介面卡則是一塊插在主機板插槽上的卡。它們的功能都是在I/O匯流排和I/O裝置之間傳遞資訊。 -
主存。主存是一個臨時儲存裝置,在處理器執行程式時,用來存放程式和程式處理的資料。從物理上來說,主存是由一組
動態隨機存取儲存器(DRAM)晶片組成的。從邏輯上來說,儲存器是一個線性的位元組陣列,每個位元組都有其唯一的地址(資料索引),這些地址是從零開始的。一般來說,組成程式的每條機器指令都由不同數量的位元組構成。與C程式變數相對應的資料項的大小是根據型別變化的。比如,在執行Linux的x86-64機器上,short型別的資料需要2個位元組,int 和 float 型別需要4個位元組,而long 和 double 型別需要8個位元組。 -
處理器。中央處理單元(CPU),簡稱樹立起,是解釋(或執行)儲存在主存中指令的引擎。處理器的核心是一個大小為一個字的儲存裝置(或暫存器),成為
程式計數器(PC)。在任何時候,PC都指向主存中的某條機器語言指令(即含有該條指令的地址)。
從系統通電,到系統斷電,處理器一直在不斷地執行PC指向的指令,再更新程式計數器,使其指向下一條指令。處理器看上去是按照一個非常簡單的指令執行模型來操作的,這個模型由指令集架構決定。在這個模型中,指令按照嚴格的順序執行,而執行一條指令包含執行一系列的步驟。處理器從PC指向的記憶體處讀取指令,解釋指令中的位,執行該指令指示的簡單操作,然後更新PC,使其指向下一條指令(這條指令不一定與剛剛執行的指令相鄰)。
這樣簡單的操作並不多,它們圍繞著主存、暫存器檔案(register file)和算數/邏輯單元(ALU)進行。暫存器檔案是一個小的儲存裝置,由一些單個字長的暫存器組成,每個暫存器都有唯一的名字。ALU計算新的資料和地址值。CPU在指令的要求下可能會執行這些操作。4.1 載入:從主存複製一個位元組或者一個字到暫存器,以覆蓋暫存器原來的內容。
4.2 儲存:從暫存器複製一個位元組或者一個字到主存的某個位置,以覆蓋這個位置上原來的內容。
4.3 操作:把兩個暫存器的內容複製到ALU,ALU對這兩個字做算術運算,並將結果存放到一個暫存器中,以覆蓋該暫存器中原來的內容。
4.4 跳轉:從指令本身中抽取一個字,並將這個字複製到PC中,以覆蓋PC中原來的值。
PS:我們需要將處理器的指令集架構和處理器的微體系結構區分開來:指令集架構描述的是每條機器指令的效果;微體系結構描述的是處理器實際上是如何實現的。
[這些內容對我來說都只是單純的輸入,有一些與之前學的微機對應了起來,PC,暫存器檔案,ALU等,對整個系統硬體有了一個總體認知]
1.4.2 執行hello程式
現在介紹當我們執行示例程式時到底發生了些什麼,這裡先做整體上的描述,省略很多細節,之後再補充。
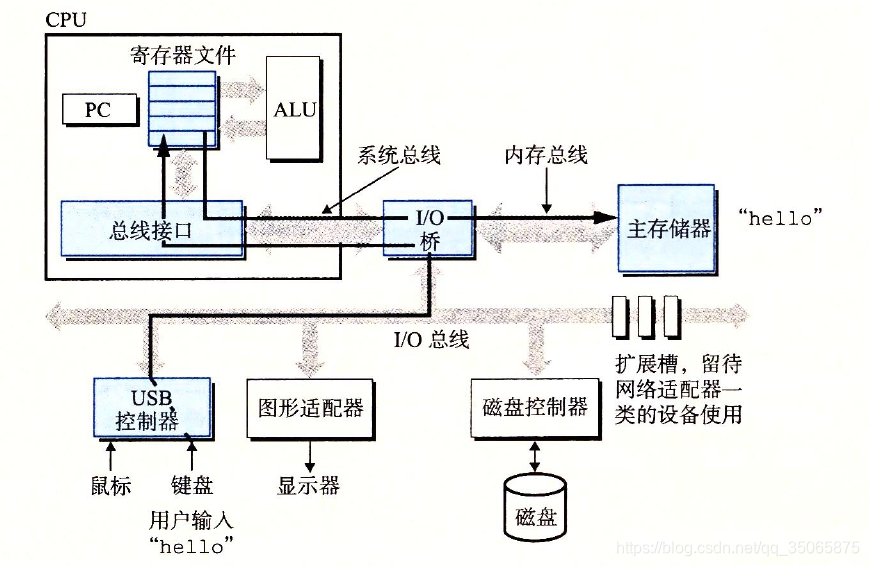
- 初始時,shell程式執行它的指令,等待我們輸入一個命令。當我們在鍵盤上輸入字串“./hello”後,shell程式將字元逐一讀入暫存器,再把它們放到記憶體([記憶體就是圖中的主存])中,如下圖:
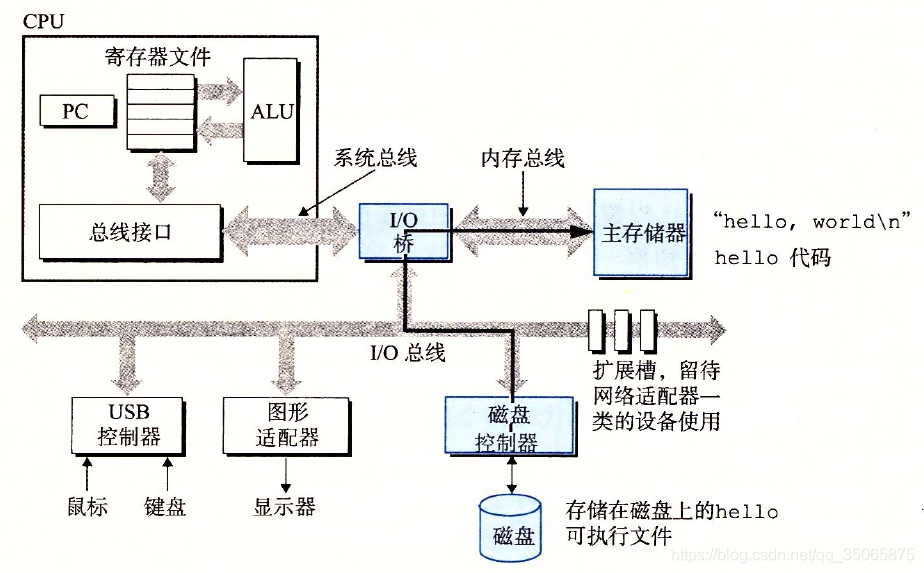
- 當我們在鍵盤上敲回車時,shell程式就知道我們已經結束了命令的輸入。然後shell執行一系列指令來載入可執行的 hello 檔案,這些指令將hello目標檔案中的程式碼和資料從磁碟複製到主存。資料包括最終會被輸出的字串“hello,world \n”。
- 一旦目標檔案 hello中的程式碼和資料被載入到主存,處理器就開始執行hello程式的main程式中的機器語言指令。這些指令將“hello,world \n”字串中的位元組從主存複製到暫存器檔案,再從暫存器檔案中複製到顯示裝置,最終顯示在螢幕上。
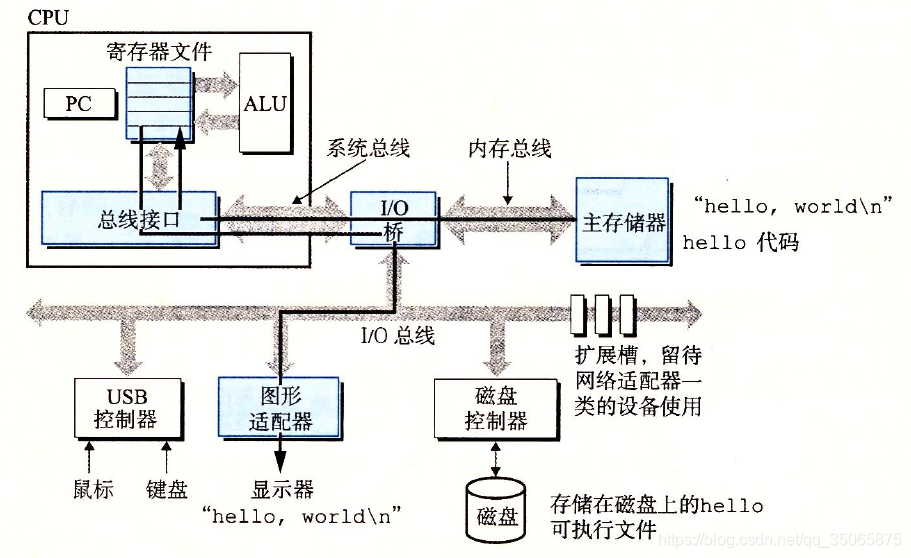
[通過這三幅圖我才理解一個程式的執行都經歷了什麼,再簡要概括一下:1.在shell輸入指令的時候,這些指令從鍵盤走到CPU中的暫存器,再到主存中;2.敲入回車之後,就把程式目標檔案中的程式碼和資料從磁碟(硬碟)複製到主存(記憶體);3.程式碼和資料被複制到主存後,CPU就執行程式的機器語言指令,這些指令會從主存複製到暫存器,如果有輸出,再從暫存器中複製到顯示裝置,最終顯示在螢幕上。]
快取記憶體至關重要
這個簡單示例揭示了一個重要問題:系統花費了大量的時間把資訊從一個地方挪到另一個地方。hello程式的機器指令最初是存放在磁碟上,程式載入時把機器指令複製到主存;當處理器執行程式時,指令從主存複製到處理器(準確的說是處理器中的暫存器)。這種複製就是開銷,減慢了程式“真正”的工作。因此,系統設計者的一個主要目標就是使這些複製操作儘可能快地完成。
比如說:一個典型系統上的磁碟可能比主存大1000倍,但是對處理器而言,從磁碟驅動器上讀取一個字的時間開銷要比從主存中讀取的開銷大1000萬倍!處理器從暫存器檔案中讀取資料比從主存中讀取又幾乎快了100倍。而且隨著半導體技術的進步,這種處理器與主存之間的差距還在持續增大。加快處理器的執行速度比加快主存的執行速度要容易和便宜的多。
針對這種處理器與主存之間的差異,系統設計者採用了更小更快的儲存裝置,稱為快取記憶體儲存器(cache memory,簡稱為cache或快取記憶體),作為暫時的集結區域,存放處理器近期可能會需要的資訊。下圖展示了典型系統中的cache。
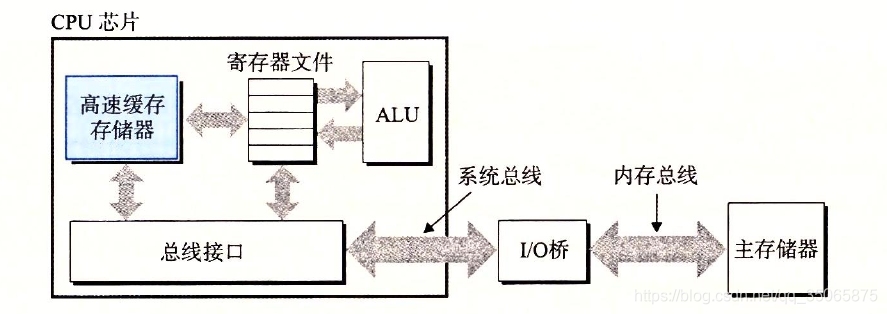
位於CPU晶片上的L1 cache的容量可以達到數萬位元組,訪問速度幾乎和訪問暫存器檔案一樣快。一個容量為數十萬到數百萬位元組的更大的L2 cache通過一條特殊的匯流排連線到CPU,程序訪問L2 cache的時間要比訪問L1 cache的時間長5倍,但是這仍然比訪問主存的時間快5~10倍。
L1 和 L2 cache是用一種叫做靜態隨機訪問儲存器(SRAM)的硬體計數實現的。更強大的系統甚至有3級cache:L1 和 L2 和 L3。使得系統獲得了一個很大的儲存區,同時訪問速度也很快,原因是利用了cache的區域性性原理(即程式具有訪問區域性區域裡資料和程式碼的趨勢)。通過讓cache裡存放可能經常訪問的資料,大部分的記憶體操作都能在高速cache中完成。
- 本書得出的重要結論之一就是,意識到cache存在的程式設計師能夠利用cache將程式的效能提高一個數量級。
1.6 儲存裝置形成層次結構
在處理器和一個較大較慢的裝置(例如主存)之間插入一個更小更快的儲存裝置(例如cache)的想法已經成為一個普遍的觀念。實際上,每一個計算機系統中的儲存裝置都被組織成了一個儲存器層次結構,如下圖。
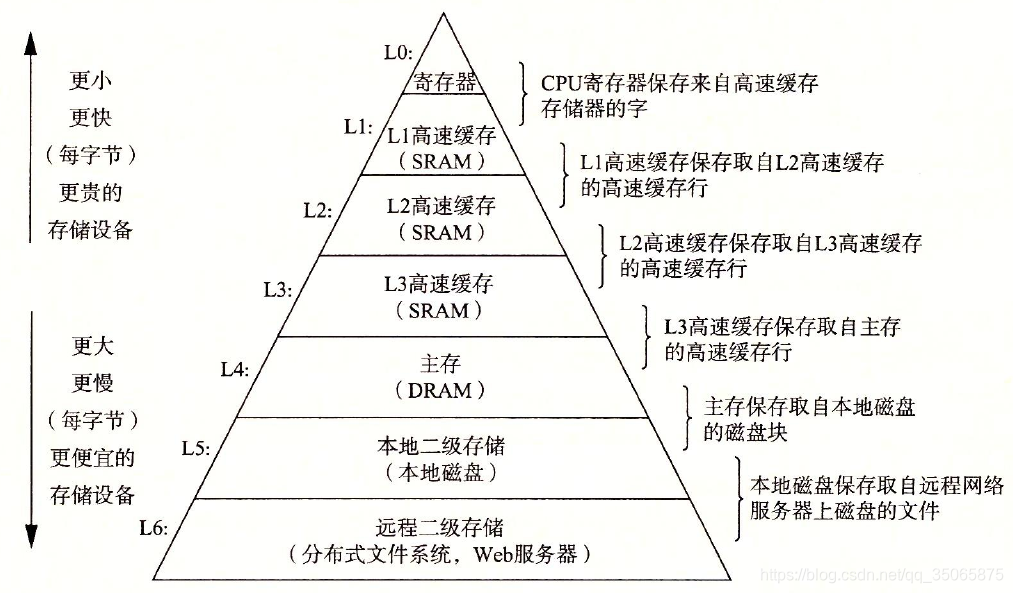
在這個層次結構中,從上至下,裝置的訪問速度越來越慢、容量越來越大,並且每位元組的造價也越來越便宜。暫存器檔案在層級結構中位於最頂部,也就是第0級或記為L0,上述說過的L1、L2、L3佔據了第1到3層,主存在第4層,以此類推。
正如可以運用不同的cache的知識來提高程式效能一樣,程式設計師同樣可以利用對整個儲存器層次結構的理解來提高程式效能。
[這幾節內容我理解了儲存器層次結構,實在太希望快點學習,能利用這些知識來讓我的程式更加高效了!另外我也在設想,是否可以利用cache的思想來改善一下我的生活,比如說努力提高自己的開發(空間)和任務交付(速度)的水平,讓自己成為公司系統中的主存,進而成為cache,甚至是暫存器?!?!,哈哈哈哈哈 whatever~]
1.7 作業系統管理硬體
回到hello程式的例子。當shell載入和執行hello程式時,以及hello程式輸出自己的訊息時,shell和hello程式都沒有直接訪問鍵盤、顯示器、磁碟或者主存。它們依靠的是作業系統提供的服務。我們可以把作業系統看成是應用程式和硬體之間插入的一層軟體。所有的應用程式對硬體的操作嘗試都必須通過作業系統。如下圖

作業系統有兩個基本功能:1.防止硬體被失控的應用程式濫用;2.嚮應用程式提供簡單一致的機制來控制複雜而又通常大不相同的低階硬體裝置。作業系統通過幾個基本的抽象概念(程序、虛擬記憶體和檔案)來實現這兩個功能。如下圖
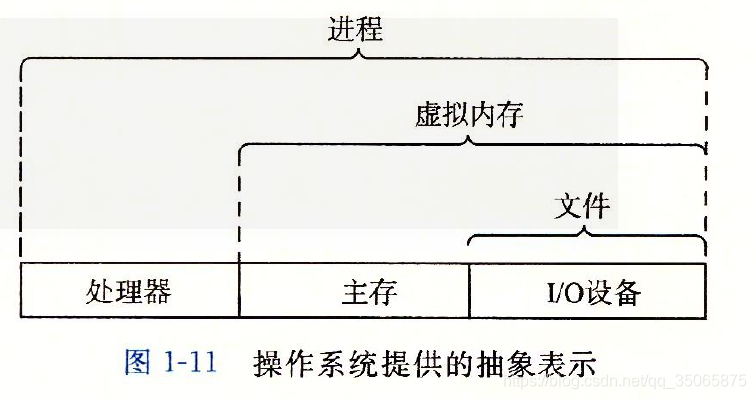
檔案是對I/O裝置的抽象表示。
虛擬記憶體是對主存和磁碟I/O裝置的抽象表示。
程序則是對處理器、主存和I/O裝置的抽象表示。
1.71 程序
像hello這樣的程式在現在系統上執行時,OS會提供一種假象,好像OS上只有這個程式在執行。程式看上去是獨佔地使用CPU、主存和I/O裝置。CPU看上去就像在不間斷地一條接一條地執行程式中的指令,即該程式的程式碼和資料是系統記憶體中唯一的物件。這些假象是通過程序的概念來實現的,程序是電腦科學中最重要和最成功的概念之一。
程序是OS對一個正在執行的程式的一種抽象。在一個OS上可以執行多個程序,而每個程序都好像在獨佔地使用硬體。而併發執行,則是說一個程序的指令和另一個程序的指令是交錯執行的。在大多數系統中,需要執行的程序數量是多於可以執行它們的CPU的個數的。傳統系統在一個時刻只能執行一個程式,而多核處理器可以同時執行多個程式[這個傳統系統得多久遠。。。]。無論是在單核還是多核系統中,一個CPU看上去都像是在併發地執行多個程序,這是通過CPU在程序間切換來實現的。OS實現這種交錯執行的機制成為上下文切換。(為了簡化討論,以下先只討論單處理器系統的情況)
OS保持跟蹤程序執行所需的所有狀態資訊。這種狀態,也就是上下文,包括許多資訊,比如PC和暫存器檔案的當前值,以及主存的內容。在任何時刻,單處理器系統都只能執行一個程序的程式碼。當OS決定要把控制權從當前程序轉移到某個新程序時,就會進行上下文切換(即儲存當前程序的上下文、恢復新程序的上下文,然後將控制權傳遞到新程序)。新程序就會從它上次停止的地方開始。
讓我們看看示例hello程序執行場景的基本理念
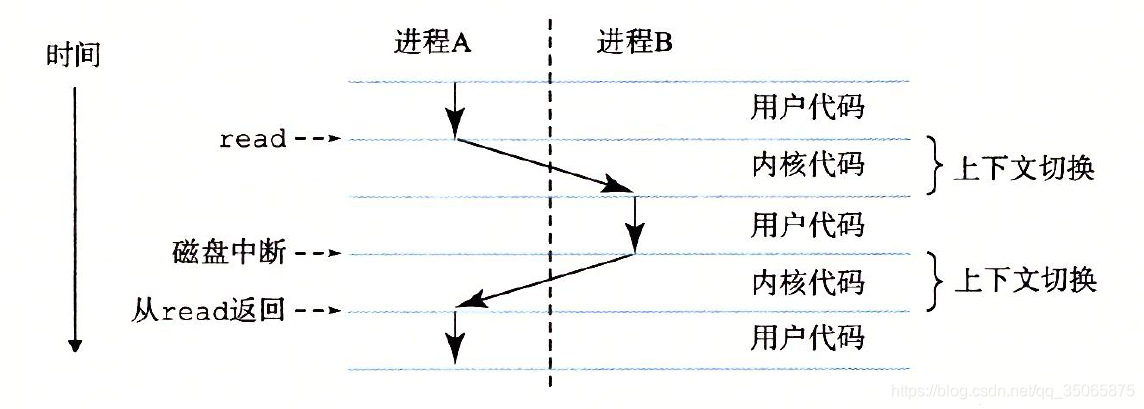
示例場景中有兩個併發的程序:shell程序 和 hello程序。最開始,只有shell程序在執行,即等待命令列上的輸入。當我們讓它執行hello程式時,shell通過呼叫一個專門的函式,即系統呼叫,來執行我們的請求,系統呼叫會將控制權傳遞給OS。OS儲存shell程序的上下文,建立新的hello程序及其上下文。然後將控制權傳給新的hello程序。hello程序終止後,OS恢復shell程序的上下文,並將控制權傳回給它,shell程序會繼續等待下一個命令列輸入。
從一個程序到另一個程序的轉換是由OS核心(kernel)管理的。核心是OS系統程式碼常駐主存的部分。當應用程式需要OS的某些操作時,比如讀寫檔案,它就執行一條特殊的系統呼叫(System call)指令,將控制權傳遞給kernel。然後核心執行被請求的操作並返回應用程式(注意,kernel不是一個獨立的程序。而是系統管理全部程序所用程式碼和資料結構的結合)。
1.7.2 執行緒
儘管通常我們認為一個程序只有單一的控制流,但是在現代系統中,一個程序實際上可以由多個稱為執行緒的執行單元組成,每個執行緒都執行在程序的上下文中,並共享同樣的程式碼和全域性資料。由於網路伺服器中對並行處理的需求,執行緒成為越來越重要的程式設計模型。當有多處理器可以用的時候,多執行緒也是一種使得程式可以執行得更快的方法。
1.7.3 虛擬記憶體
虛擬記憶體是一個抽象概念,它為每個程序提供了一個假象,即每個程序都在獨佔地使用主存。每個程序看到的記憶體都是一致的,稱為虛擬地址空間。下圖是Linux程序的虛擬地址空間。
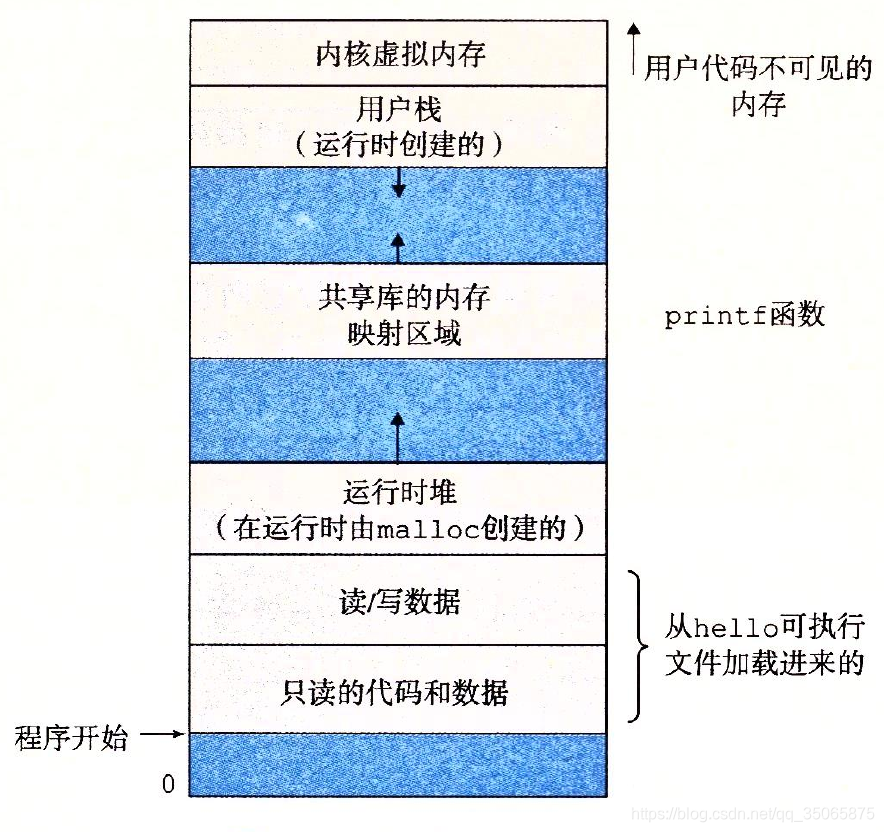
在Linux中,地址空間最上面的區域是保留給OS中的程式碼和資料的,這對所有程序來說都是一樣的。地址空間的底部區域存放使用者程序定義的程式碼和資料。圖中的地址是從下往上增大的。
每個程序看到的虛擬地址空間由大量準確定義的區構成,每個區都有專門的功能。簡單的瞭解一下各個區:
- 程式程式碼和資料。對所有的程序來說,程式碼是從同一固定地址開始,緊接著的是和C全域性變數相對應的資料位置。程式碼和資料區是直接按照可執行目標檔案的內容初始化的,在例子中就是可執行檔案hello。
- 堆。程式碼和資料區後緊隨著的是執行時
堆。程式碼和資料區在程序一開始時就被指定了大小,與此不同,當呼叫像malloc和free這樣的C標準庫函式時,堆可以在執行時動態地擴充套件和收縮。 - 共享庫。大約在地址空間的中間部分是一塊用來存放像C標準庫和數學庫這樣的共享庫的程式碼和資料的區域。共享庫的概念非常強大,也相當難懂
- 棧。位於使用者虛擬地址空間頂部的是
使用者棧,編譯器用它來實現函式呼叫。和堆一樣,使用者棧在程式執行期間可以動態地擴充套件和收縮。特別的,每次我們呼叫一個函式時,棧就會增長;從一個函式返回時,棧就會收縮。 - 核心虛擬記憶體。地址空間頂部的區域是為核心保留的。不允許應用程式讀寫這個區域的內容或者直接呼叫核心程式碼定義的函式。相反,它們必須呼叫核心來執行這些操作。
虛擬記憶體的運作需要硬體和作業系統軟體之間精密複雜的互動,包括對處理器生成的每一個地址的硬體翻譯。基本思想是把一個程序虛擬記憶體的內容儲存在磁碟上,然後用主存作為磁碟的快取記憶體。
[現在只是知道了虛擬記憶體的用途和每個區的用途,但是還是沒有感受到它有什麼好的,以後的學習中應該會體會到吧。]
1.7.4 檔案
檔案就是位元組序列,僅此而已。每一個I/O裝置,包括磁碟、鍵盤、顯示器,甚至網路,都可以看成是檔案。系統中的所有輸入輸出都是通過使用一組稱為Unix I/O的系統函式呼叫讀寫檔案來實現的。
檔案這個簡單而精緻的概念是非常強大的,因為它嚮應用程式提供了一個統一的檢視,來看待系統中可能含有的所有各式各樣的I/O裝置。例如,處理磁碟檔案內容的應用程式設計師可以非常幸福,因為他們無須瞭解具體的磁碟計數。進一步說,同一個程式可以在使用不同磁碟技術的不同系統上執行。
[實習期間學習了TP和LCD的移植,在閱讀它們的驅動的時候,就能體會到這裡描述的概念,比如想讓LCD顯示一些東西,就在指定的快取地址寫入希望顯示的東西,這不就是“把LCD看成了一個檔案,我想要顯示什麼,我就在這個檔案裡寫入什麼”嗎]
1.8 系統之間利用網路通訊
系統漫遊至此,我們一直是把系統視為一個孤立的硬體和軟體的集合體。實際上,現代系統經常通過網路和其他系統連線到一起。從一個單獨的系統來看,網路可以視為一個I/O裝置,如下圖。
當系統從主存複製一串位元組到網路介面卡時,資料流經過網路到達另一臺機器,而不是比如說到達本地磁碟驅動器[這是說我發到網路上的資訊,在本地是沒有儲存的意思嗎?我可以理解成我在CSDN寫這篇部落格的文字時,我釋出文章後,我本地確實沒有這篇部落格的文字嗎?]。相似的,系統可以讀取從其他機器傳送來的資料,並把資料複製到自己的主存。
隨著Internet這樣的全球網路的出現,從一臺主機複製資訊到另外一臺主機已經成為計算機系統中最重要的用途之一。比如email、FTP、Telnet這樣的應用都是基於網路複製資訊的功能。
再拿上面的hello例子,我們可以使用熟悉的Telnet應用在一個遠端主機上執行hello程式[我一點也不熟悉…]。假設用本地主機上的Telnet客戶端連線遠端主機上的Telnet伺服器。在我們登入到遠端主機並執行shell後,遠端的shell就在等待接收輸入命令。此後在遠端執行hello程式包括下圖的五個步驟。

當我們在Telnet客戶端鍵入“hello”字串並敲下回車後,客戶端軟體就會將這個字串傳送到Telnet的伺服器。Telnet伺服器從網路上接收到這個字串後,會把它傳遞給遠端shell程式。接下來,遠端shell執行hello程式,並將輸出返回給Telnet伺服器。最後,Telnet伺服器通過網路把輸出串轉發給Telnet客戶端,客戶端就將輸出串輸出到我們的本地終端上。
這種客戶端和伺服器之間互動的型別在所有網路應用中是非常典型的。
[我們自己買境外伺服器來搭建VPN應該是一個道理吧?在科學上網的時候資訊傳到伺服器上,再轉發給我們的裝置。]
1.9 重要主題
在此有一個很重要的觀點,那就是系統不僅僅只是硬體。系統是硬體和系統軟體相互交織的集合體,它們必須共同協作以達到執行應用程式的最終目的。
1.9.1 Amdahl定律
該定律的主要思想是,當我們對系統的某個部分加速時,其對系統整體效能的影響取決於該部分的重要性和加速程度。
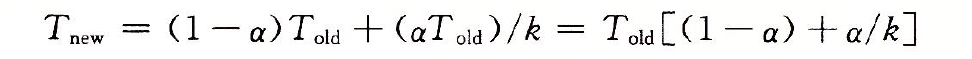
T old 是系統性能提升前執行某應用程式需要時間
α 系統某部分所執行時間與執行應用程式總時間比例
k 該部分效能提升比例
T new 系統性能提升後執行某應用程式需要的時間
由此可以計算加速比為:
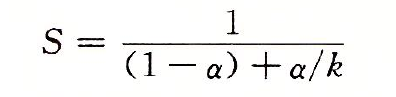
舉個例子,α = 60%,k = 3 則 S = 1.67,雖然我們對系統的一個部分做出了重大改進,但是獲得的系統加速比卻明顯小於這部分的加速比。這就是Amdahl定律的重要觀點——想要顯著加速整個系統,必須提升全系統中相當大的部分的速度
[這個定律似乎可以用於任何由多方複雜因素共同影響的事情,比如大學生想提高GPA,我們想減肥等,因為經歷過減肥的痛苦,所以感受頗深。減肥需要控制飲食、改變作息、改變日常習慣、增強鍛鍊等幾個部分,妄圖單單改變其中某一個部分來整體提升減肥加速比,簡直是痴心妄想,哈哈哈不小心暴露了自己對於減肥這件事情的深惡痛絕。]
1.9.2 併發和並行
數字計算機的整個歷史中,有兩個需求是驅動進步的持續動力:一個是我們想要計算機做的更多,另一個是我們想要計算機執行的更快。
我們用的術語併發(concurrency)是一個通用的概念,指一個同時具有多個活動的系統
並行(parallelism)指的是用併發使一個系統執行得更快。並行可以在計算機系統的多個抽象層次上運用。
1.執行緒級併發。構建在程序這個抽象上,我們可以設計出同時有多個程式執行的系統,這就導致了併發。使用執行緒,我們甚至能夠在一個程序中控制多個控制流。傳統意義上,這種併發執行只是模擬出來的,是通過一臺計算機在它正在執行的程序間快速切換來實現的。這種併發形式允許多個使用者同時與系統互動,例如,在一個視窗中開啟Web瀏覽器,在另一個視窗中執行字處理器,同時又播放音樂。在以前,即使處理器必須在多個任務間切換,大多數實際的計算也都是由一個處理器來完成的。這種配置成為單處理器系統。
當構建一個由單作業系統核心控制的多處理器組成的系統時,我們就得到了一個多處理器系統。隨著多核處理器和超執行緒的出現,這種系統才變得常見。
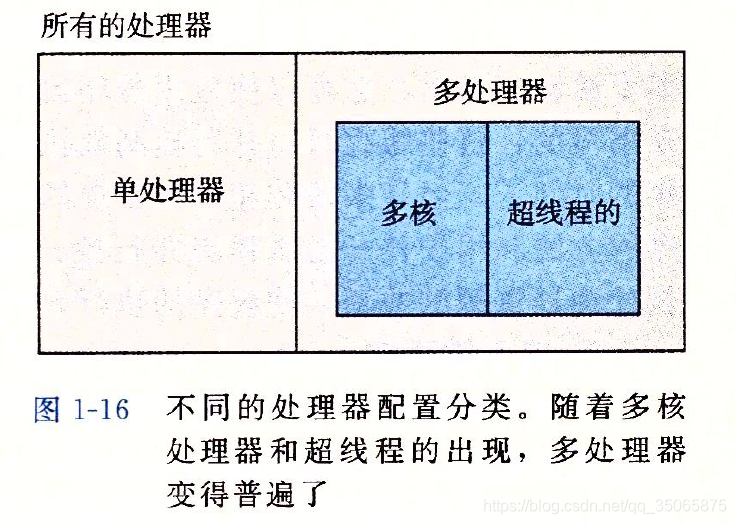
多核處理器是將多個CPU(稱為核)整合到一個積體電路晶片上。下圖描述了典型的多核處理器的組織結構。
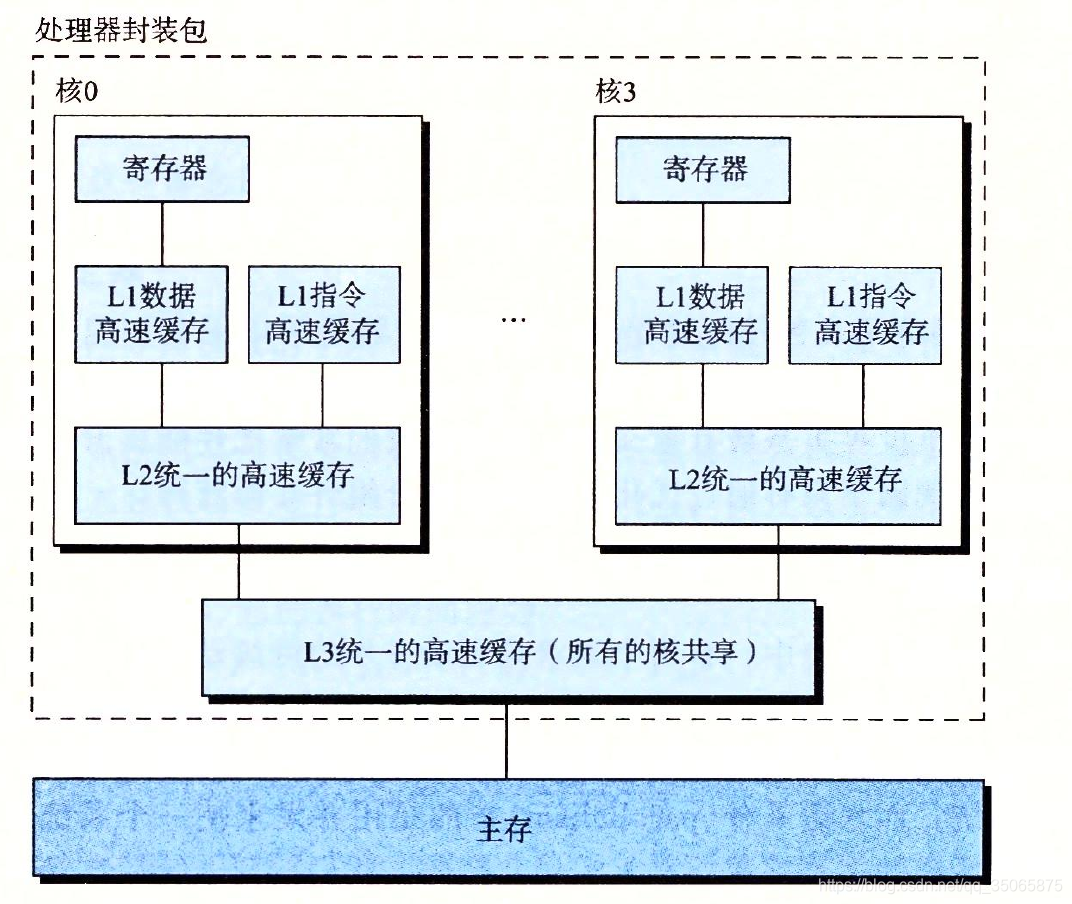
其中微處理器晶片有4個CPU核,每個核都有自己的L1和L2快取記憶體,其中的L1快取記憶體分為兩個部分——一個儲存最近取到的指令,另一個存放資料。這些核共享更高層次的快取記憶體,以及到主存的介面。
超執行緒,有時稱為同時多執行緒,是一項允許一個CPU執行多個控制流的計數。它設計CPU某些硬體有多個備份,必須程式計數器和暫存器檔案,而其他的硬體部分只有一份,比如執行浮點算術運算的單元。常規的處理器需要大約20000個時鐘週期做不同執行緒間的轉換,而超執行緒的處理器可以在單個週期的基礎上決定要執行哪一個執行緒。這使得CPU能夠更好的利用它的處理資源。
比如,假設一個執行緒必須等到某些資料被裝載到快取記憶體中,那CPU就可以繼續去執行另一個執行緒。舉例來說,Intel Core i7處理器可以讓每個核執行兩個執行緒,所以一個4核的系統實際上可以並行地執行8個執行緒。
多處理器的使用可以從兩方面提高系統性能。首先,它減少了在執行多個任務時模擬併發的需要。正如前面提到的,即使是隻有一個使用者使用的個人計算機也需要併發地執行多個活動。其次,它可以使應用程式執行得更快,當然,這必須要求程式是以多執行緒方式來書寫的,這些執行緒可以並行地高效執行。
[我實在有一種願望,就是找到一種應用程式的寫法利用硬體開發執行緒級別並行性,不過這樣的話似乎對於電腦的配置有了要求,不太符合分層思想,不過現在電腦都是多核處理器的吧。。。]
2.指令級並行,在較低的抽象層次上,現代處理器可以同時執行多條指令的屬性成為指令級並行。早起的微處理器,比如Intel 8086,需要多個時鐘週期來執行一條指令。最近的處理器可以保持每個時鐘週期執行2~4條指令、其實每條指令從開始到結束需要長得多的時間,大約20個週期,但是處理器使用了非常多的聰明技巧來同時處理多達100條指令。之後會研究流水線的使用。在流水線中,將執行一條指令所需要的活動劃分為不同的步驟,將處理器的硬體組織成一系列的階段,每個階段執行一個步驟。這些階段可以並行地操作,來處理不同指令的不同部分。
如果處理器可以達到比一個週期一個指令更快的執行速率,就稱之為超標量處理器。大多數現代處理器都支援超標量操作。
3 .單指令、多資料並行,在最低層次上,許多現代處理器擁有特殊的硬體,允許一條指令生產多個可以並行執行的操作,這種方式稱為單指令、多資料,即SIMD並行。例如,比較新的Intel和AMD處理器都具有並行地對8對單精度浮點數(C資料型別float)做加法的指令。
提供這些SIMD指令多是為了提高處理影像、聲音和視訊資料應用的執行速度。雖然有些編譯器會試圖從C程式中自動抽取SIMD並行性,但是更可靠的方法是用編譯器支援的特殊向量資料型別來寫程式,比如GCC就支援向量資料型別。
[簡要的理一下,併發是描述同時有多個活動的系統,是個通用概念,並行是指用併發來使一個系統執行得更快。並行分為執行緒級並行、指令集並行和單指令、多資料並行。
執行緒級並行是較高抽象層次的概念,就是同時執行多個程式,在早先的單處理器只是通過快速切換程式間切換來模擬的,現在是由多核處理器和超執行緒實現的,多核處理器就是多個CPU,每個CPU執行一個任務,超執行緒就是一個CPU可以執行多個任務,兩種方法通常結合起來實現更多工的並行。
指令級並行是在較低的抽象層次上,讓處理器同時執行多條指令,比如同時執行復制和相加的指令。
單指令、多資料並行是最低層次上,通過處理器擁有的特殊硬體,讓一條指令產生多個可以並行執行的操作,比如同時對好幾對資料執行加法指令。]
1.9.3 計算機系統中抽象的重要性
抽象的使用是電腦科學中最為重要的概念之一。例如,為一組函式規定一個簡單的API就是很好的程式設計習慣,程式設計師無須瞭解它內部的工作便可以使用這些程式碼。
我們已經介紹了計算機系統中使用的幾個抽象。如下圖
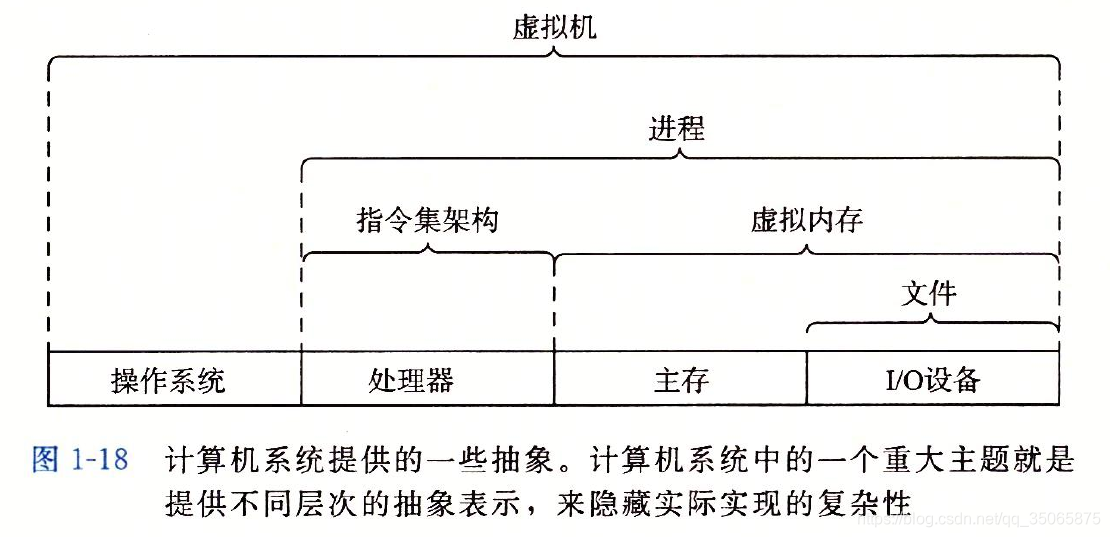
在處理器中,指令集架構提供了對實際處理器硬體的抽象。使用這個抽象,機器程式碼程式表現得就好像執行在一個一次只執行一條指令的處理器上。底層的硬體遠比抽象描述的要複雜精細,它並行地執行多條指令,但又總是與那個簡單有序的模型保持一致。只要執行模型一樣,不同的處理器實現也能執行同樣的機器程式碼,而又提供不同的開銷和效能。
在學習作業系統時,我們介紹了三個抽象:檔案是對I/O裝置的抽象,虛擬記憶體是對程式儲存器的抽象,而程序是對一個正在執行的程式的抽象。我們再增加一個新的抽象:虛擬機器,它提供對整個計算機的抽象,包括作業系統、處理器和程式。因為一些計算機必須能夠執行為不同的作業系統或同一作業系統的不同版本設計的程式,虛擬機器才顯示出其管理計算機方式上的優勢。
1.10 小結
計算機系統是由硬體和系統軟體組成的,它們共同協作以執行應用程式。計算機內部的資訊被表示為一組組的位,它們依據上下文有不同的解釋方式。程式被其他程式翻譯成不同的形式,開始時是ASCII文字,然後被編譯器和連結器翻譯成二進位制可執行檔案。
處理器讀取並解釋存放在主存裡的二進位制指令。因為計算機花了大量的時間在主存、I/O裝置和CPU暫存器之間複製資料,所以將系統中儲存裝置劃分成層次結構——CPU暫存器在頂部,接著是多層的硬體快取記憶體儲存器,DRAM主存和磁碟儲存器。在層次模型中位於更高層的儲存裝置比磁層的儲存裝置要更快,單位位元造價也更高。層次結構中較高層次的儲存裝置可以作為較低層次裝置的快取記憶體。通過理解和運用這種儲存層次結構的知識,程式設計師可以優化C程式的效能。
作業系統核心是應用程式和硬體之間的媒介。它系統了三個基本抽象:1.檔案是對I/O裝置的抽象;2.虛擬記憶體是對主存和磁碟的抽象;3.程序是處理器、主存和I/O裝置的抽象。
最後,網路提供了計算機系統之間通訊的手段。從特出系統的角度來看,網路就是一種I/O裝置。
[第一章-計算機系統漫遊的內容就全部結束了,看完了這一章對計算機系統有了初步的瞭解。]