
大資料架構師從入門到精通
經常有初學者在部落格和QQ問我,自己想往大資料方向發展,該學哪些技術,學習路線是什麼樣的,覺得大資料很火,就業很好,薪資很高。如果自己很迷茫,為了這些原因想往大資料方向發展,也可以,那麼我就想問一下,你的專業是什麼,對於計算機/軟體,你的興趣是什麼?是計算機專業,對作業系統、硬體、網路、伺服器感興趣?是軟體專業,對軟體開發、程式設計、寫程式碼感興趣?還是數學、統計學專業,對資料和數字特別感興趣。
其實這就是想告訴你的大資料的三個發展方向,平臺搭建/優化/運維/監控、大資料開發/ 設計/ 架構、資料分析/挖掘。請不要問我哪個容易,哪個前景好,哪個錢多。
先扯一下大資料的4V特徵:
資料量大,TB->PB
資料型別繁多,結構化、非結構化文字、日誌、視訊、圖片、地理位置等;
商業價值高,但是這種價值需要在海量資料之上,通過資料分析與機器學習更快速的挖掘出來;
處理時效性高,海量資料的處理需求不再侷限在離線計算當中。
現如今,正式為了應對大資料的這幾個特點,開源的大資料框架越來越多,越來越強,先列舉一些常見的:
檔案儲存:Hadoop HDFS、Tachyon、KFS
離線計算:Hadoop MapReduce、Spark
流式、實時計算:Storm、Spark Streaming、S4、Heron
K-V、NOSQL資料庫:HBase、Redis、MongoDB
資源管理:YARN、Mesos
日誌收集:
訊息系統:Kafka、StormMQ、ZeroMQ、RabbitMQ
查詢分析:Hive、Impala、Pig、Presto、Phoenix、SparkSQL、Drill、Flink、Kylin、Druid
分散式協調服務:Zookeeper
叢集管理與監控:Ambari、Ganglia、Nagios、Cloudera Manager
資料探勘、機器學習:Mahout、Spark MLLib
資料同步:Sqoop
任務排程:Oozie
眼花了吧,上面的有30多種吧,別說精通了,全部都會使用的,估計也沒幾個。就我個人而言,主要經驗是在第二個方向(開發/設計/架構),且聽聽我的建議吧。

第一章:初識Hadoop1.1 學會百度與Google
不論遇到什麼問題,先試試搜尋並自己解決。Google首選,翻不過去的,就用百度吧。
1.2 參考資料首選官方文件
特別是對於入門來說,官方文件永遠是首選文件。相信搞這塊的大多是文化人,英文湊合就行,實在看不下去的,請參考第一步。
1.3 先讓Hadoop跑起來
Hadoop可以算是大資料儲存和計算的開山鼻祖,現在大多開源的大資料框架都依賴Hadoop或者與它能很好的相容。
關於Hadoop,你至少需要搞清楚以下是什麼:
Hadoop 1.0、Hadoop 2.0
MapReduce、HDFS
NameNode、DataNode
JobTracker、TaskTracker
Yarn、ResourceManager、NodeManager
自己搭建Hadoop,請使用第一步和第二步,能讓它跑起來就行。建議先使用安裝包命令列安裝,不要使用管理工具安裝。另外:Hadoop1.0知道它就行了,現在都用Hadoop 2.0.
1.4 試試使用Hadoop
HDFS目錄操作命令;上傳、下載檔案命令;提交執行MapReduce示例程式;開啟Hadoop WEB介面,檢視Job執行狀態,檢視Job執行日誌。知道Hadoop的系統日誌在哪裡。
1.5 你該瞭解它們的原理了MapReduce:如何分而治之;HDFS:資料到底在哪裡,什麼是副本;
Yarn到底是什麼,它能幹什麼;NameNode到底在幹些什麼;Resource Manager到底在幹些什麼;
1.6 自己寫一個MapReduce程式
請仿照WordCount例子,自己寫一個(照抄也行)WordCount程式,
打包並提交到Hadoop執行。你不會Java?Shell、Python都可以,有個東西叫Hadoop Streaming。如果你認真完成了以上幾步,恭喜你,你的一隻腳已經進來了。
第二章:更高效的WordCount2.1 學點SQL吧
你知道資料庫嗎?你會寫SQL嗎?如果不會,請學點SQL吧。
2.2 SQL版WordCount
在1.6中,你寫(或者抄)的WordCount一共有幾行程式碼?給你看看我的:
SELECT word,COUNT(1) FROM wordcount GROUP BY word;
這便是SQL的魅力,程式設計需要幾十行,甚至上百行程式碼,我這一句就搞定;使用SQL處理分析Hadoop上的資料,方便、高效、易上手、更是趨勢。不論是離線計算還是實時計算,越來越多的大資料處理框架都在積極提供SQL介面。
2.3 SQL On Hadoop之Hive
什麼是Hive?官方給的解釋如下:The Apache Hive data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage and queried using SQL syntax.
為什麼說Hive是資料倉庫工具,而不是資料庫工具呢?有的朋友可能不知道資料倉庫,資料倉庫是邏輯上的概念,底層使用的是資料庫,資料倉庫中的資料有這兩個特點:最全的歷史資料(海量)、相對穩定的;所謂相對穩定,指的是資料倉庫不同於業務系統資料庫,資料經常會被更新,資料一旦進入資料倉庫,很少會被更新和刪除,只會被大量查詢。而Hive,也是具備這兩個特點,因此,Hive適合做海量資料的資料倉庫工具,而不是資料庫工具。
2.4 安裝配置Hive
請參考1.1 和 1.2 完成Hive的安裝配置。可以正常進入Hive命令列。
2.5 試試使用Hive
請參考1.1 和 1.2 ,在Hive中建立wordcount表,並執行2.2中的SQL語句。
在Hadoop WEB介面中找到剛才執行的SQL任務。看SQL查詢結果是否和1.4中MapReduce中的結果一致。
2.6 Hive是怎麼工作的
明明寫的是SQL,為什麼Hadoop WEB介面中看到的是MapReduce任務?
2.7 學會Hive的基本命令
建立、刪除表;載入資料到表;下載Hive表的資料;請參考1.2,學習更多關於Hive的語法和命令。
如果你已經按照《寫給大資料開發初學者的話》中第一章和第二章的流程認真完整的走了一遍,那麼你應該已經具備以下技能和知識點:
MapReduce的原理(還是那個經典的題目,一個10G大小的檔案,給定1G大小的記憶體,如何使用Java程式統計出現次數最多的10個單詞及次數);
HDFS讀寫資料的流程;向HDFS中PUT資料;從HDFS中下載資料;
自己會寫簡單的MapReduce程式,執行出現問題,知道在哪裡檢視日誌;
會寫簡單的SELECT、WHERE、GROUP BY等SQL語句;
Hive SQL轉換成MapReduce的大致流程;
Hive中常見的語句:建立表、刪除表、往表中載入資料、分割槽、將表中資料下載到本地;
從上面的學習,你已經瞭解到,HDFS是Hadoop提供的分散式儲存框架,它可以用來儲存海量資料,MapReduce是Hadoop提供的分散式計算框架,它可以用來統計和分析HDFS上的海量資料,而Hive則是SQL On Hadoop,Hive提供了SQL介面,開發人員只需要編寫簡單易上手的SQL語句,Hive負責把SQL翻譯成MapReduce,提交執行。
此時,你的”大資料平臺”是這樣的:那麼問題來了,海量資料如何到HDFS上呢?
第三章:把別處的資料搞到Hadoop上
此處也可以叫做資料採集,把各個資料來源的資料採集到Hadoop上。
3.1 HDFS PUT命令
這個在前面你應該已經使用過了。put命令在實際環境中也比較常用,通常配合shell、python等指令碼語言來使用。建議熟練掌握。
3.2 HDFS API
HDFS提供了寫資料的API,自己用程式語言將資料寫入HDFS,put命令本身也是使用API。
實際環境中一般自己較少編寫程式使用API來寫資料到HDFS,通常都是使用其他框架封裝好的方法。比如:Hive中的INSERT語句,Spark中的saveAsTextfile等。建議瞭解原理,會寫Demo。
3.3 Sqoop
Sqoop是一個主要用於Hadoop/Hive與傳統關係型資料庫,Oracle、MySQL、SQLServer等之間進行資料交換的開源框架。就像Hive把SQL翻譯成MapReduce一樣,Sqoop把你指定的引數翻譯成MapReduce,提交到Hadoop執行,完成Hadoop與其他資料庫之間的資料交換。
自己下載和配置Sqoop(建議先使用Sqoop1,Sqoop2比較複雜)。瞭解Sqoop常用的配置引數和方法。
使用Sqoop完成從MySQL同步資料到HDFS;使用Sqoop完成從MySQL同步資料到Hive表;如果後續選型確定使用Sqoop作為資料交換工具,那麼建議熟練掌握,否則,瞭解和會用Demo即可。
3.4 Flume
Flume是一個分散式的海量日誌採集和傳輸框架,因為“採集和傳輸框架”,所以它並不適合關係型資料庫的資料採集和傳輸。Flume可以實時的從網路協議、訊息系統、檔案系統採集日誌,並傳輸到HDFS上。
因此,如果你的業務有這些資料來源的資料,並且需要實時的採集,那麼就應該考慮使用Flume。
下載和配置Flume。使用Flume監控一個不斷追加資料的檔案,並將資料傳輸到HDFS;Flume的配置和使用較為複雜,如果你沒有足夠的興趣和耐心,可以先跳過Flume。
3.5 阿里開源的DataX
之所以介紹這個,是因為我們公司目前使用的Hadoop與關係型資料庫資料交換的工具,就是之前基於DataX開發的,非常好用。
可以參考我的博文《異構資料來源海量資料交換工具-Taobao DataX 下載和使用》。現在DataX已經是3.0版本,支援很多資料來源。你也可以在其之上做二次開發。有興趣的可以研究和使用一下,對比一下它與Sqoop。
第四章:把Hadoop上的資料搞到別處去
前面介紹瞭如何把資料來源的資料採集到Hadoop上,資料到Hadoop上之後,便可以使用Hive和MapReduce進行分析了。那麼接下來的問題是,分析完的結果如何從Hadoop上同步到其他系統和應用中去呢?其實,此處的方法和第三章基本一致的。
4.1 HDFS GET命令
把HDFS上的檔案GET到本地。需要熟練掌握。
4.2 HDFS API
同3.2.
4.3 Sqoop
同3.3.使用Sqoop完成將HDFS上的檔案同步到MySQL;使用Sqoop完成將Hive表中的資料同步到MySQL。
4.4 DataX
同3.5. 如果你認真完成了上面的學習和實踐,此時,你的”大資料平臺”應該是這樣的:
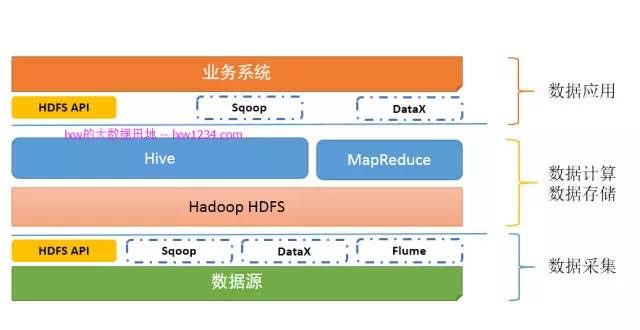
如果你已經按照《寫給大資料開發初學者的話2》中第三章和第四章的流程認真完整的走了一遍,那麼你應該已經具備以下技能和知識點:
知道如何把已有的資料採集到HDFS上,包括離線採集和實時採集;你已經知道sqoop(或者還有DataX)是HDFS和其他資料來源之間的資料交換工具;你已經知道flume可以用作實時的日誌採集。
從前面的學習,對於大資料平臺,你已經掌握的不少的知識和技能,搭建Hadoop叢集,把資料採集到Hadoop上,使用Hive和MapReduce來分析資料,把分析結果同步到其他資料來源。
接下來的問題來了,Hive使用的越來越多,你會發現很多不爽的地方,特別是速度慢,大多情況下,明明我的資料量很小,它都要申請資源,啟動MapReduce來執行。
第五章:快一點吧,我的SQL
其實大家都已經發現Hive後臺使用MapReduce作為執行引擎,實在是有點慢。因此SQL On Hadoop的框架越來越多,按我的瞭解,最常用的按照流行度依次為SparkSQL、Impala和Presto.這三種框架基於半記憶體或者全記憶體,提供了SQL介面來快速查詢分析Hadoop上的資料。關於三者的比較,請參考1.1.
我們目前使用的是SparkSQL,至於為什麼用SparkSQL,原因大概有以下吧:使用Spark還做了其他事情,不想引入過多的框架;Impala對記憶體的需求太大,沒有過多資源部署。
5.1 關於Spark和SparkSQL
什麼是Spark,什麼是SparkSQL。
Spark有的核心概念及名詞解釋。
SparkSQL和Spark是什麼關係,SparkSQL和Hive是什麼關係。
SparkSQL為什麼比Hive跑的快。
Spark有哪些部署模式?
如何在Yarn上執行SparkSQL?
使用SparkSQL查詢Hive中的表。Spark不是一門短時間內就能掌握的技術,因此建議在瞭解了Spark之後,可以先從SparkSQL入手,循序漸進。
關於Spark和SparkSQL,如果你認真完成了上面的學習和實踐,此時,你的”大資料平臺”應該是這樣的。
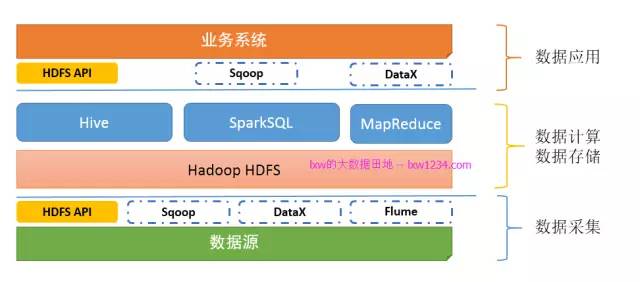
第六章:一夫多妻制
請不要被這個名字所誘惑。其實我想說的是資料的一次採集、多次消費。
在實際業務場景下,特別是對於一些監控日誌,想即時的從日誌中瞭解一些指標(關於實時計算,後面章節會有介紹),這時候,從HDFS上分析就太慢了,儘管是通過Flume採集的,但Flume也不能間隔很短就往HDFS上滾動檔案,這樣會導致小檔案特別多。
為了滿足資料的一次採集、多次消費的需求,這裡要說的便是Kafka。
6.1 關於Kafka
什麼是Kafka?Kafka的核心概念及名詞解釋。
6.2 如何部署和使用Kafka
使用單機部署Kafka,併成功執行自帶的生產者和消費者例子。使用Java程式自己編寫並執行生產者和消費者程式。Flume和Kafka的整合,使用Flume監控日誌,並將日誌資料實時傳送至Kafka。
如果你認真完成了上面的學習和實踐,此時,你的”大資料平臺”應該是這樣的。

這時,使用Flume採集的資料,不是直接到HDFS上,而是先到Kafka,Kafka中的資料可以由多個消費者同時消費,其中一個消費者,就是將資料同步到HDFS。
如果你已經按照《寫給大資料開發初學者的話3》中第五章和第六章的流程認真完整的走了一遍,那麼你應該已經具備以下技能和知識點:
為什麼Spark比MapReduce快。
使用SparkSQL代替Hive,更快的執行SQL。
使用Kafka完成資料的一次收集,多次消費架構。
自己可以寫程式完成Kafka的生產者和消費者。
從前面的學習,你已經掌握了大資料平臺中的資料採集、資料儲存和計算、資料交換等大部分技能,而這其中的每一步,都需要一個任務(程式)來完成,各個任務之間又存在一定的依賴性,比如,必須等資料採集任務成功完成後,資料計算任務才能開始執行。如果一個任務執行失敗,需要給開發運維人員傳送告警,同時需要提供完整的日誌來方便查錯。
第七章:越來越多的分析任務
不僅僅是分析任務,資料採集、資料交換同樣是一個個的任務。這些任務中,有的是定時觸發,有點則需要依賴其他任務來觸發。當平臺中有幾百上千個任務需要維護和執行時候,僅僅靠crontab遠遠不夠了,這時便需要一個排程監控系統來完成這件事。排程監控系統是整個資料平臺的中樞系統,類似於AppMaster,負責分配和監控任務。
7.1 Apache Oozie
1. Oozie是什麼?有哪些功能?
2. Oozie可以排程哪些型別的任務(程式)?
3. Oozie可以支援哪些任務觸發方式?
4. 安裝配置Oozie。
7.2 其他開源的任務排程系統
Azkaban,light-task-scheduler,Zeus,等等。另外,我這邊是之前單獨開發的任務排程與監控系統,具體請參考《大資料平臺任務排程與監控系統》。如果你認真完成了上面的學習和實踐,此時,你的”大資料平臺”應該是這樣的:
第八章:我的資料要實時
在第六章介紹Kafka的時候提到了一些需要實時指標的業務場景,實時基本可以分為絕對實時和準實時,絕對實時的延遲要求一般在毫秒級,準實時的延遲要求一般在秒、分鐘級。對於需要絕對實時的業務場景,用的比較多的是Storm,對於其他準實時的業務場景,可以是Storm,也可以是Spark Streaming。當然,如果可以的話,也可以自己寫程式來做。
8.1 Storm
1. 什麼是Storm?有哪些可能的應用場景?
2. Storm由哪些核心元件構成,各自擔任什麼角色?
3. Storm的簡單安裝和部署。
4. 自己編寫Demo程式,使用Storm完成實時資料流計算。
8.2 Spark Streaming
1. 什麼是Spark Streaming,它和Spark是什麼關係?
2. Spark Streaming和Storm比較,各有什麼優缺點?
3. 使用Kafka + Spark Streaming,完成實時計算的Demo程式。
至此,你的大資料平臺底層架構已經成型了,其中包括了資料採集、資料儲存與計算(離線和實時)、資料同步、任務排程與監控這幾大模組。接下來是時候考慮如何更好的對外提供資料了。
第九章:我的資料要對外
通常對外(業務)提供資料訪問,大體上包含以下方面。
離線:比如,每天將前一天的資料提供到指定的資料來源(DB、FILE、FTP)等;離線資料的提供可以採用Sqoop、DataX等離線資料交換工具。
實時:比如,線上網站的推薦系統,需要實時從資料平臺中獲取給使用者的推薦資料,這種要求延時非常低(50毫秒以內)。根據延時要求和實時資料的查詢需要,可能的方案有:HBase、Redis、MongoDB、ElasticSearch等。
OLAP分析:OLAP除了要求底層的資料模型比較規範,另外,對查詢的響應速度要求也越來越高,可能的方案有:Impala、Presto、SparkSQL、Kylin。如果你的資料模型比較規模,那麼Kylin是最好的選擇。
即席查詢:即席查詢的資料比較隨意,一般很難建立通用的資料模型,因此可能的方案有:Impala、Presto、SparkSQL。
這麼多比較成熟的框架和方案,需要結合自己的業務需求及資料平臺技術架構,選擇合適的。原則只有一個:越簡單越穩定的,就是最好的。
如果你已經掌握瞭如何很好的對外(業務)提供資料,那麼你的“大資料平臺”應該是這樣的:
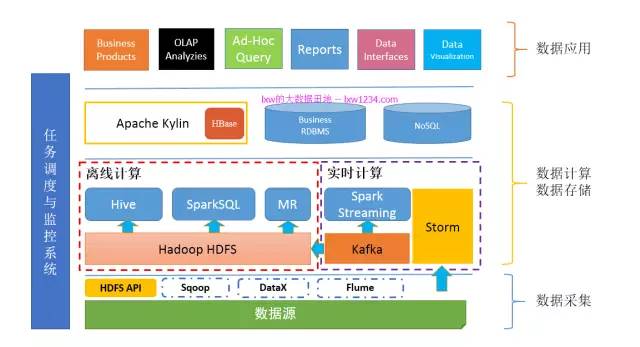
第十章:牛逼高大上的機器學習
關於這塊,我這個門外漢也只能是簡單介紹一下了。數學專業畢業的我非常慚愧,很後悔當時沒有好好學數學。在我們的業務中,遇到的能用機器學習解決的問題大概這麼三類:
分類問題:包括二分類和多分類,二分類就是解決了預測的問題,就像預測一封郵件是否垃圾郵件;多分類解決的是文字的分類;
聚類問題:從使用者搜尋過的關鍵詞,對使用者進行大概的歸類。
推薦問題:根據使用者的歷史瀏覽和點選行為進行相關推薦。
大多數行業,使用機器學習解決的,也就是這幾類問題。入門學習線路,數學基礎;機器學習實戰,懂Python最好;SparkMlLib提供了一些封裝好的演算法,以及特徵處理、特徵選擇的方法。
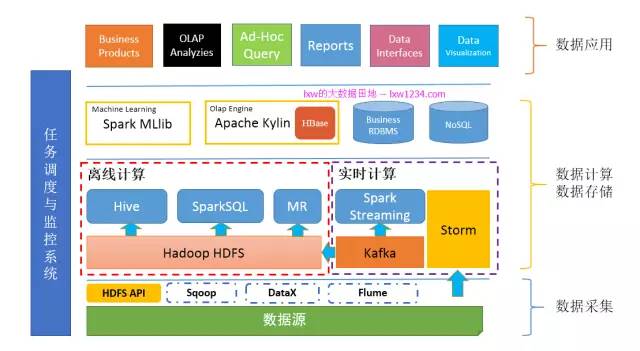
機器學習確實牛逼高大上,也是我學習的目標。那麼,可以把機器學習部分也加進你的“大資料平臺”了。