
windows本地sparkstreaming開發環境搭建及簡單例項
windows本地spark開發環境搭建及簡單例項
1:開發環境IDEA選擇:
IntelliJ IDEA Community Edition 2017.1.1 (相比eclipse更方便,不用裝那麼多外掛,且提供免費版,官網直接下載安裝就可以)
2:環境配置:(開發語言scala)
由於公司網路原因,下載不方便,沒有用mavn,直接拖了本地的jar包
(1) spark core開發jar包:
(2) spark streaming開發jar包:

(3) spark 連線 hive jar包:

(4) jdk及sdk包:

(5) 由於我的開發場景最終資料要寫入hive,所以要引入

(6) 最終專案結構如圖:
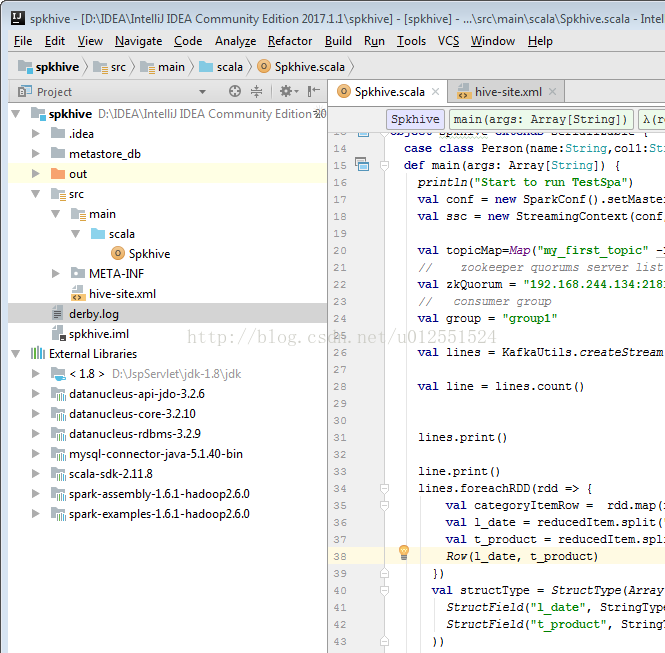
(7) 由於要連線hive,我們要把叢集的hive-site.xml拿出來,直接拖到專案裡就可以了:
這一步還是要有的,不然預設hive元資料管理metastore會去連線derby,hive-site.xml我們把metastore配置為mysql,這樣我們把hive-site.xml拖進來就會預設採用hive-site的配置了(上圖中的derby.log可以忽略,檔案是我測試時自動產生的)
Hive-site.xml部分配置截圖:

這裡的mysql我是連的hadoop環境的,也就是我虛擬機器環境的mysql,當然如果本地windows環境裝有
3:測試
Case資料流圖
Flume → kafka → spark streaming → hive
Flume具體配置請參考:
Kafka配置請參考:
Spark程式碼如下(只是測試,沒有對時間窗資料做處理,只是寫進寫出):
/** * Created by Tracy.Gao01 on 5/8/2017. */import org.apache.spark
import org.apache.spark.SparkConf
import org.apache.spark.sql.Row
import org.apache.spark.streaming._
import
import org.apache.spark.sql.hive._
import org.apache.spark.sql.types.{StringType, StructField, StructType}
object Spkhive extends
Serializable {
case class Person(name:String,col1:String)
def main(args: Array[String]) {
println("Start to run TestSpa")
val conf = new
SparkConf().setMaster("local[3]")setAppName("Spkhive")
val ssc = new
StreamingContext(conf, Seconds(30))
val topicMap=Map("my_first_topic"
-> 1)
// zookeeper quorums server listval
zkQuorum = "192.168.244.134:2181";
// consumer groupval
group = "group1"val
lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)
val line = lines.count()
lines.print()
line.print()
lines.foreachRDD(rdd => {
val categoryItemRow = rdd.map(reducedItem => {
val l_date = reducedItem.split(",")(0)
val t_product = reducedItem.split(",")(1)
Row(l_date, t_product)
})
val structType =
StructType(Array(
StructField("l_date", StringType,
true),
StructField("t_product", StringType,
true)
))
val hiveContext =
new HiveContext(rdd.context)
val categoryItemDF = hiveContext.createDataFrame(categoryItemRow,structType)
categoryItemDF.registerTempTable("categoryItemTable1")
hiveContext.sql("use default")
hiveContext.sql( """CREATE TABLE if not exists `table2`( `l_date` string, `t_product` string)""")
val reseltDataFram = hiveContext.sql("SELECT l_date,t_product FROM categoryItemTable1")
reseltDataFram.show()
hiveContext.sql("insert into table2 select l_date,t_product from categoryItemTable1")
hiveContext.sql("insert into table table2 select t.* from (select 1, 10) t")
val reseltDataFram1 = hiveContext.sql("SELECT l_date,t_product FROM table2")
val count = hiveContext.sql("SELECT count(*) FROM table2")
reseltDataFram1.show(1000)
count.show()
hiveContext.clearCache()
})
ssc.start() //Start the computationssc.awaitTermination() //Wait for the computation to termination}
}
4:測試結果
控制檯輸出如下:
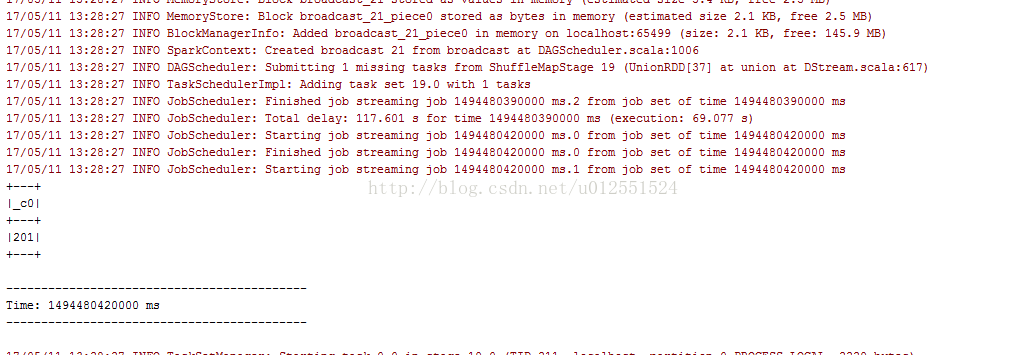
這樣的話簡單的開發環境就搭建成功了。
5:遇到問題解決
You have an error in your SQL syntax; check the manual that corresponds to your MySQLserver version for the right syntax to use near 'OPTION SQL_SELECT_LIMIT=DEFAULT' at line 1
如果遇到這樣的問題,適當切換以一下mysql驅動連線包的版本,一般是版本過低導致。
Specified key was too long; max key length is 767 bytes
解決方案:在mysql機器的上命令列中執行:alter database hive character set latin1;