
ElasticSearch中如何進行排序
Elasticsearch中如何進行排序
背景
最近去兄弟部門的新自定義查詢專案組搬磚,專案使用ElasticSearch進行資料的檢索和查詢。每一個查詢頁面都需要根據選擇的欄位進行排序,以為是一個比較簡單的需求,其實實現起來還是比較複雜的。這裡進行一個總結,加深一下記憶。
前置知識
-
ElasticSearch是什麼?
ElasticSearch 簡稱ES,是一個全文搜尋引擎,可以實現類似百度搜索的功能。但她不僅僅能進行全文檢索,還可以實現PB級資料的近實時分析和精確檢索,還可以作GIS資料庫,進行AI機器學習,功能非常強大。 -
ES的資料模型
ES中常用巢狀文件和父子文件兩種方法進行資料建模,多層父子文件還可以形成祖孫文件。但是父子文件是一種不推薦的建模方式,這種方式有很多的侷限性。如果傳統關係型資料庫的建模方法是通過“三正規化”進行規範化,那麼ES的建模方法就是反正規化,進行反規範化。關係型資料庫的資料是表格模型,ES是JSON樹狀模型。
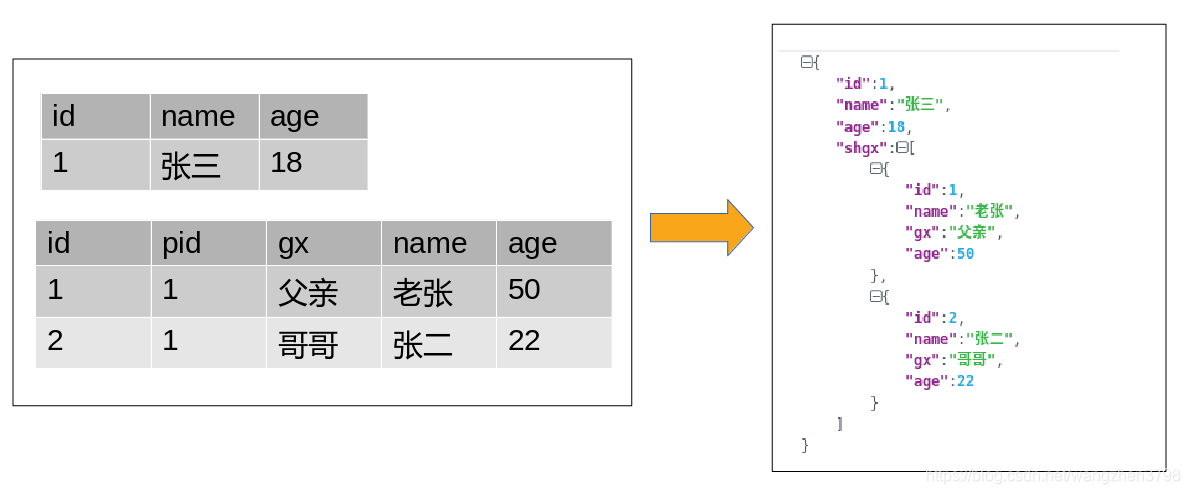
ES中排序的分類
根據建模方法的不同,ES中排序分為以下幾種,每種都有不同的排序寫法和侷限:
- 巢狀文件-根據主文件欄位排序
- 巢狀文件-根據內嵌文件欄位排序
- 父子文件-查父文件-根據子文件排序
- 父子文件-查子文件-根據父文件排序
- 更復雜的情況,父子文件裡又嵌套了文件,然後進行排序
- 更更復雜情況,父子文件裡又嵌套了文件,然後進行指令碼欄位排序
- 更更更復雜情況,父子文件裡又嵌套了文件,然後使用自定義指令碼進行評分排序
- 更更更更…
下面分別對幾種情況,進行測試說明。
測試資料準備
首先,設定索引型別欄位對映
PUT /test_sort
{
"mappings": {
"zf":{
"properties": {
"id":{"type": "keyword"},
"name":{"type": "keyword"},
"age":{"type": "integer"},
"shgx":{"type": "nested"}
}
}
}
}
然後新建測試資料
PUT /test_sort/zf/1 { "id":1, "name":"張三", "age":18, "shgx":[{ "id":1, "name":"老張", "age":50, "gx":"父親" },{ "id":2, "name":"張二", "age":22, "gx":"哥哥" }] } PUT /test_sort/zf/2 { "id":2, "name":"李四", "age":25, "shgx":[{ "id":3, "name":"李五", "age":23, "gx":"弟弟" }] }
- 巢狀文件-根據主文件欄位排序
根據zf主文件age欄位倒敘排列,直接加sort子語句就可以
POST /test_sort/zf/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"_source": {"include": ["id","name","age"]}
}
結果:
"hits": [
{
"_index": "test_sort",
"_type": "zf",
"_id": "2",
"_score": null,
"_source": {
"name": "李四",
"id": 2,
"age": 25
},
"sort": [
25
]
},
{
"_index": "test_sort",
"_type": "zf",
"_id": "1",
"_score": null,
"_source": {
"name": "張三",
"id": 1,
"age": 18
},
"sort": [
18
]
}
]
- 巢狀文件-根據內嵌文件欄位排序
根據age小於50歲的親屬排序,理論上李四應該排第一位,因為50歲以下的親屬,李五最大。,憑直覺先這樣寫
POST /test_sort/zf/_search
{
"query": {
"nested": {
"path": "shgx",
"query": {
"range": {
"shgx.age": {
"lt": 50
}
}
}
}
},
"sort": [
{
"shgx.age": {
"nested_path": "shgx",
"order": "desc"
}
}
]
}
看結果:
"hits": [
{
"_index": "test_sort",
"_type": "zf",
"_id": "1",
"_score": null,
"_source": {
"id": 1,
"name": "張三",
"age": 18,
"shgx": [
{
"id": 1,
"name": "老張",
"age": 50,
"gx": "父親"
},
{
"id": 2,
"name": "張二",
"age": 22,
"gx": "哥哥"
}
]
},
"sort": [
50
]
},
{
"_index": "test_sort",
"_type": "zf",
"_id": "2",
"_score": null,
"_source": {
"id": 2,
"name": "李四",
"age": 25,
"shgx": [
{
"id": 3,
"name": "李五",
"age": 23,
"gx": "弟弟"
}
]
},
"sort": [
23
]
}
]
非常重要 and 非常重要 這樣寫的結果是錯誤的,原因是巢狀文件是作為主文件的一部分返回的。在主查詢中的過濾條件並沒有把不符合條件的內部巢狀文件過濾調,以至於排序巢狀文件時,*還是按照全部的巢狀文件排序的。要想避免這種情況,要把主查詢中有關巢狀文件的查詢條件,在排序中再寫一遍。
正確的寫法:
POST /test_sort/zf/_search
{
"query": {
"nested": {
"path": "shgx",
"query": {
"range": {
"shgx.age": {
"lt": 50
}
}
}
}
},
"sort": [
{
"shgx.age": {
"nested_path": "shgx",
"order": "desc",
"nested_filter": {
"range": {
"shgx.age": {
"lt": 50
}
}
}
}
}
]
}
- 父子文件-查父文件-根據子文件排序
構造測試資料,首先設定父子文件的對映關係
PUT /test_sort_2
{
"mappings": {
"zf_parent":{
"properties": {
"id":{"type": "keyword"},
"name":{"type": "keyword"},
"age":{"type": "integer"}
}
},
"shgx":{
"_parent": {
"type": "zf_partent"
}
}
}
}
然後,新增資料。
PUT /test_sort_2/zf_parent/1
{
"id":1,
"name":"張三",
"age":18
}
PUT /test_sort_2/zf_parent/2
{
"id":2,
"name":"李四",
"age":25
}
PUT /test_sort_2/shgx/1?parent=1
{
"id":1,
"name":"老張",
"age":50,
"gx":"父親"
}
PUT /test_sort_2/shgx/2?parent=1
{
"id":2,
"name":"張二",
"age":22,
"gx":"哥哥"
}
PUT /test_sort_2/shgx/3?parent=2
{
"id":3,
"name":"李五",
"age":23,
"gx":"弟弟"
}
然後,再根據age小於50歲的親屬排序,正序排序的話張三應該是第一位,
POST /test_sort_3/zf_parent/_search
{
"query": {
"has_child": {
"type": "shgx",
"query": {
"range": {
"age": {
"lt": 50
}
}
},
"inner_hits": {
"name": "ZfShgx",
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
}
}
}
排查結果:
{
"_index": "test_sort_3",
"_type": "zf_parent",
"_id": "2",
"_score": 1,
"_source": {
"id": 2,
"name": "李四",
"age": 25
},
"inner_hits": {
"ZfShgx": {
"hits": {
"total": 1,
"max_score": null,
"hits": [
{
"_type": "shgx",
"_id": "3",
"_score": null,
"_routing": "2",
"_parent": "2",
"_source": {
"id": 3,
"name": "李五",
"age": 23,
"gx": "弟弟"
},
"sort": [
23
]
}
]
}
}
}
},
{
"_index": "test_sort_3",
"_type": "zf_parent",
"_id": "1",
"_score": 1,
"_source": {
"id": 1,
"name": "張三",
"age": 18
},
"inner_hits": {
"ZfShgx": {
"hits": {
"total": 1,
"max_score": null,
"hits": [
{
"_type": "shgx",
"_id": "2",
"_score": null,
"_routing": "1",
"_parent": "1",
"_source": {
"id": 2,
"name": "張二",
"age": 22,
"gx": "哥哥"
},
"sort": [
22
]
}
]
}
}
}
}
結果是錯誤的,李四在前,檢視官方文件的父子文件時不能直接用子文件排序父文件,或者用父文件排序子文件。那有沒有解決辦法呢?有一個曲線救國的方案,使用function_score通過子文件的評分來影響父文件的順序,但是評分演算法很難做到精準控制順序。
中文字元排序
在專案中發現,中文字元在ES中的順序和在關係型資料庫中的順序不一致。經查原因是因為ES是用的unicode的位元組碼做排序的。即先對字元(包括漢字)轉換成byte[]陣列,然後對陣列進行排序。這種排序規則對ASIC碼(英文)是有效的,但對於中文等亞洲國家的字元不適用,怎麼辦呢?有兩種辦法:
- 第一種,做拼音冗餘。即在向ES同步資料時候,同步程式將漢字欄位同時轉換成拼音,在ES裡專用用於漢字排序。如:
#插入資訊
POST /test/star/1
{
"xm": "劉德華",
"xm_pinyin": "liudehua"
}
POST /test/star/2
{
"xm": "張惠妹",
"xm_pinyin": "zhanghuimei"
}
# 查詢排序
POST /test/star/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"xm_pinyin": {
"order": "desc"
}
}
]
}
- 第二種,使用ICU分詞外掛。使用外掛提供的icu_collation_keyword 過濾器,實現中文排序。
PUT test2
{
"mappings": {
"user": {
"properties": {
"xm": {
"type": "text",
"fields": {
"sort": {
"type": "icu_collation_keyword",
"index": false,
"language": "zh",
"country": "CN"
}
}
}
}
}
}
}
POST /test/star/_search
{
"query": {
"match_all": { }
},
"sort": "xm.sort"
}
結論
- 巢狀文件-根據主文件欄位排序時,可以使用sort語句直接排序,無限制。
- 巢狀文件-根據巢狀文件欄位排序時,必須在sort子句裡把所有有關的查詢條件,重新寫一邊,排序才正確。
- 父子文件-查父文件-根據子文件排序不能根據子文件排序父文件,反之亦然。
- 資料模型的複雜程度決定了排序的複雜程度,排序的複雜程度隨著模型的複雜程度成指數級增加。
- 中文字元可以通過做拼音冗餘和使用ICU外掛來實現排序。