
通過不斷重置學習率來逃離區域性極值點
/*.*/
黃通文 張俊林( 2016年12月)
注:這篇文章的思路以及本文是我們在2016年底左右做自動發現探索網路結構過程中做的,當時做完發現ICLR 2017有類似論文提出相似的方法,所以沒有做更多實驗並就把這篇東西擱置了。今天偶然翻到,感覺還是有一定價值,所以現在發出來。
對於神經網路目標函式優化來說,在引數尋優過程中最常用的演算法是梯度下降,目前也出現了很多基於SGD基礎上的改進演算法,比如帶動量的SGD,Adadelta,Adagrad,Adam,RMSProp等梯度下降改進方法,這些演算法大多都是針對基礎更新公式進行改進:
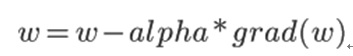
其中,w是訓練過程中的當前引數值,alpha是學習率,grad(w)是此刻的梯度方向。目前的改進演算法要麼修正學習率alpha要麼修正梯度計算方法grad(w),要麼兩者都修正,比如Adagrad/Adam動態調整學習率,Adam動態調整梯度的更新量或者有些演算法加入動量部分。
一般深度神經網路由於很深的深度以及非線性函式這兩個主要因素,導致目標的損失函式是非凸函式,該損失函式曲面中包含許多的駐點,駐點可能是以下三類關鍵點中的一種:鞍點,區域性極小值,全域性極小值,其中全域性極小值是我們期望訓練演算法能夠找到的,而其它兩類是期望能夠避免的。一個示意性的損失函式曲面如下圖所示:
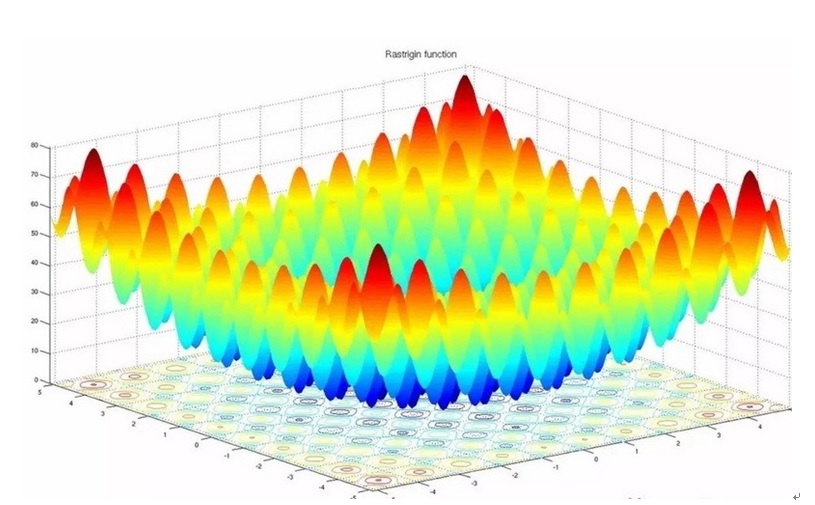
不少學習演算法在訓練過程中,隨著誤差的減少,迭代次數的增加,步長變化越來越小,訓練誤差越來越小直到變為零,區域性探索到一個駐點,如果這個點是誤差曲面的鞍點,即不是最大值也不是最小值的平滑曲面,那麼一般結果表現為效能比較差;如果這個駐點是區域性極小值,那麼表現為效能較好,但不是全域性最優值。目前大多數訓練演算法在碰到無論是鞍點還是區域性極值點的時候,因為此刻學習率已經變得非常小,所以會陷入非全域性最優值不能自拔。這其實就是目前採用SGD類似的一階導數方法訓練機器學習系統面臨的一個很重要的問題。
目前來看,沒有方法能夠保證找到非凸函式優化過程中的全域性最小值,也就是說,不論你怎麼調參將效能調到你能做到的最好,仍然大概率獲得了優化過程中的一個鞍點或者區域性極小值,那麼一個很自然的想法就是:能否在優化過程的末尾,就是已經大概率陷入某個區域性極小值或者鞍點的時候,放大學習率,強行讓訓練演算法跳出當前的區域性最小值或者鞍點,所謂“世界這麼大,我想去看看”,繼續尋找可能效果會更好的極值點,這樣多次跳出優化過程中的區域性最小值,然後比較其中效能最好的極小值,並以那個時刻的引數作為模型引數。當然,這仍然沒有辦法保證找到全域性最小值,只是說多比較一些極值點,矮子裡面拔將軍的意思。這個思路是去年我們在利用人工生命和遺傳演算法探索自動生成神經網路結構的不斷優化網路效能過程中產生的,當時是看到了SNAPSHOT ENSEMBLES : TRAIN 1,GET M FOR FREE這篇論文受到啟發動了這個念頭,於是單獨測試了一下這個思路,結果表明一般情況下,這種方法是能夠有效提升優化效果的,不過提升幅度不算太大(後來看到了這篇論文:SGDR: STOCHASTIC GRADIENT DESCENT RESTARTS 發現基本思路是有點類似的)。
一.兩種跳出駐點的方法
上面說了基本思路,其實思路很樸實也很簡單:常見的訓練方法在剛開始的時候學習率設定的比較大,這樣可以大幅度快步向極值點邁進,加快收斂速度,隨著越來越接近極值點,逐步將學習率調小,這樣避免步子太大跳過極值點或者造成優化過程震盪結果不穩定。當優化到效能無法再提升的時候,此時大概率陷入了鞍點或者區域性極小值,表現為梯度接近於0而且一般此時學習率已經調整到非常小的程度了。跳出駐點的思路就是說:此時可以重新把已經調整的很小的學習率數值放大,強行逼迫優化演算法跳出此刻找到的鞍點或者極值點,在上述示意的損失函式曲面上等於當前在某個山谷的谷底(或者某個平臺上,即鞍點),此時邁出一大步跳到比較遠的地方,然後繼續常規的優化過程,就是不斷調小學習率,期望找到附近的另外一個山谷谷底,如此往復若干次,然後找出這些谷底哪個谷底更深,然後採取這個最深的谷底對應的引數作為模型引數。
所以這裡的關鍵是在優化進行不下去的時候重新調大學習率跳出當前的山谷,根據起跳點的不同,可以有兩種不同的方法:
方法1:隨機漫步起跳法
這個方法比較簡單,就是說當前優化走到哪個山谷谷底,就從當前位置起跳,直接調大學習率即可,因為這樣類似於走到哪裡走不下去就從哪裡開始跳到附近的遠處,走到哪算哪,所以稱之為“隨機漫步起跳法”。
方法2:歷史最優起跳法
上面說過,在這種優化方法過程中,會不斷進入某個谷底,那麼假設在訓練集上優化歷史上已經經過K個谷底,在驗證集上其對應引數的模型效能是可以知道的,分別為P1,P2……Pk。隨機漫步起跳法就是從Pk作為起跳點進行起跳。而歷史最優起跳法則從P1,P2……Pk中效能最優的那個山谷谷底開始起跳,假設Pi=Max(P1,P2……Pk),那麼從第i個山谷開始起跳,如果跳出後發現第j個山谷的效能Pj要優於Pi,則後面從Pj的位置開始起跳,當從Pi跳過K次都沒有發現比Pi效能更好的山谷,此時可以終止優化演算法。這個有點像是Pi效能的“一山望著一山高”,然後不斷從歷史最高峰跳到更高的高山上,可以保證效能應該越來越好。從道理上講感覺這種歷史最優起跳法要好於隨機漫步起跳法,但是實驗結果表明兩種不同的起跳方法效能是差不多的,有時候這個稍好點,有時候那個稍好點,沒有哪個方法確定性的比另外一個好。
二.相關的實驗及其結果
為了檢驗上述跳出駐點的思路是否有效,我們選擇了若干深層CNN模型來測試,這裡列出其中某個模型的結果,這個模型結構可能看上去有點奇怪,前面說過這個思路是我們去年在做網路最優結構自動探索任務中產生的,所以這兩個比較奇怪的結構是從自動生成的網路結構裡面隨機選出的,效能比較好。分類資料是cifar10圖片分類資料,選擇帶動量的SGD演算法作為基準方法來進行相關實驗的驗證。
2.1模型結構及引數配置
CNN模型結構如下圖所示: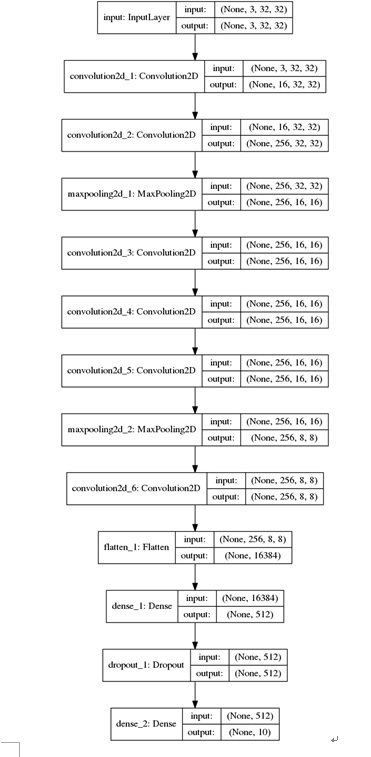
其模型結構為:model structure:('init-29', [('conv', [('nb_filter', 16)]), ('conv',[('nb_filter', 256)]), ('maxp', [('pool_size', 2)]), ('conv', [('nb_filter',256)]), ('conv', [('nb_filter', 256)]), ('conv', [('nb_filter', 256)]),('maxp', [('pool_size', 2)]), ('conv', [('nb_filter', 256)])])")
後面部分接上fc(512,relu)+dropout(0.2)+fc(10,softmax)的分類層;
學習演算法設定的引數為: 選擇使用Nesterov的帶動量的隨機梯度下降法,初始學習率為0.01,衰減因子為1e-6,momentum因子為0.9。
2.2 Nesterov+動量SGD(固定學習率)實驗效果
在上節所述的模型設定下,從結果看,最好的測試精度是0.9060,模型的誤差和精度都變化地比較平滑
2.3學習率自適應減少進行訓練的實驗結果
其它配置類似於2.1.2所述,唯一的不同在於:使用常規策略對學習率進行縮小的改變。改變學習率的策略是如果誤差10次不變化,那麼學習率縮小為原來的0.1倍。 總迭代次數設定為100次。 訓練誤差、訓練準確率、測試誤差、測試準確率的變化曲線為:
從訓練結果看,第47次學習率變化,效能上有一次大幅度的提高:
從訓練和測試的結果看,測試精度最高的是在第80輪,達到了0.9144。此時的訓練誤差0.3921,訓練準確率0.9926,測試誤差0.3957,測試準確率0.9144。
由此可見,增加學習率的動態改變,在學習速度和質量上要比原始的學習率恆定的訓練方法要好,這裡效能上增加近一個百分點。
2.4隨機漫步起跳法實驗結果
從上面的兩組實驗結果過程的最後階段可以看出,誤差和準確率變化較小,很可能優化過程陷入一個區域性最優值,可能是一個極值,也可能是一個鞍點,不管怎樣稱呼它,它就是一個駐點。(從結果看,應該是一個區域性最優值)。在其它實驗條件與2.1.3節所述相同情況下,採取上文所述的隨機漫步起跳法強迫優化演算法跳出當前區域性最優,即在學習率比較低的時候,進行擴大學習率的方式(直接設定為0.1,後面再常規的逐步減少),讓其在誤差曲面的區域中去尋找更多的駐點。 具體做法是:如果當前發現經過三次學習率變小沒有帶來準確率的提升,那麼在當前訓練的點,將學習率恢復到初始的學習率即0.01。 迭代的效果如下訓練誤差、訓練準確率、測試誤差、測試準確率的變化曲線如下圖為: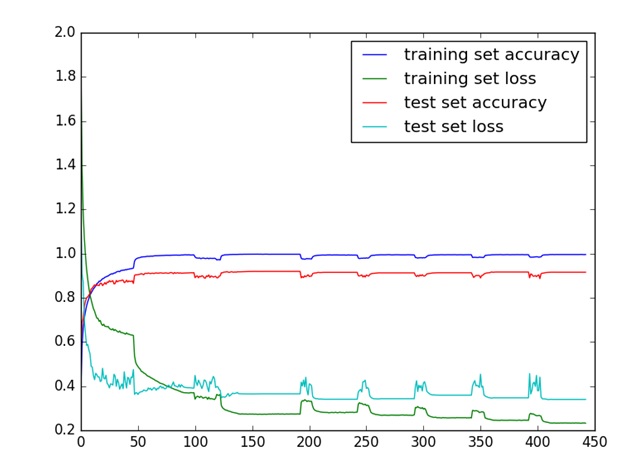
從訓練過程看,從當前迭代的當前位置出發,採用學習率縮小和擴大相結合的方式,目前最高能在第153輪的準確率提高到0.9236,比之前最好的0.9144有一點提升,說明這樣的學習率變大策略也是一種可行的思路。
另外,從圖中看,由於我們變大學習率許多次,每次學習率變大都會呈現一個波動形式,故結果表現出鋸齒狀的波動趨勢。
2.5歷史最優起跳法實驗結果
我們做了類似的實驗,發現歷史最優起跳法與隨機漫步起跳法效能相當,有時這個好點有時那個好點,沒有發現效能明顯差異。
我們隨機抽了其它幾個最優網路結構自動探索出的深度神經網路結構,表現與上述網路結構類似,而如果基礎網路結構本身效能越差,這個差別越大。
所以可以得出的結論是:優化過程中採用常規動態學習率調整效果要優於固定學習率的方法,而隨機漫步起跳法效果略優於常規的動態學習率調整方法,但是歷史最優起跳法相對常規動態學習率方法沒有發現改善。
相關文獻
- SGDR: STOCHASTIC GRADIENT DESCENT RESTARTS .ICLR-2017
- SNAPSHOT ENSEMBLES : TRAIN 1,GET M FOR FREE