
自己開發網站全文檢索系統
1. 概述
1.1. 問題提出
假如你擁有一個龐大的網站,內容又多,那麼來訪者往往很難找到自己所需要的東東,這時候你就需要一個站內搜尋來幫助來訪者更快的找到索要的資料了!
1.2. 解決的辦法
搭建自己的全文檢索系統。
1.2.1 什麼是全文檢索
全文檢索是一種將檔案中所有文字與檢索項匹配的文字資料檢索方法。全文檢索系統是按照全文檢索理論建立起來的用於提供全文檢索服務的軟體系統。
目前最大的搜尋引擎Google和Baidu使用的就是全文檢索技術。當然Google基於Google三寶(GFS、MapReduce、BigTable)構建了龐大的大資料處理平臺。全文檢索是搜尋引擎技術的一個重要部分。
1.2.2. 資料分類
結構化資料:指具有固定格式或有限長度的資料,如資料庫,元資料等。
非結構化資料:指沒有固定格式或不定長的資料,如郵件,word文件等。
非結構化資料還有一種叫法:全文資料。
1.2.3. 按資料的分類,搜尋也分為兩種
- 對結構化資料的搜尋:
如對資料庫的搜尋:SQL語句。再如windows的搜尋:檔名,型別,修改時間。
- 對非結構化資料的搜尋:
如windows對檔案內容的搜尋。Linux下得grep命令。再如Google和百度可以搜素大量內容資料。
對於非結構化的資料搜尋也叫做對全文資料的搜尋。要獲得良好的搜尋體驗,全文檢索技術可以達到這一點。對全文資料的搜尋還可以分為兩種:
1、順序掃描:如要找內容包含某個字串的檔案,會一個文件一個文件的從頭到尾的找,如 Like查詢 。
2、索引掃描:把非結構化的資料中的內容提取出來一部分重新組織,讓它變的有結構化,這部分我們提取出來的資料就叫做索引.
單純的使用資料庫提供的全文搜尋已經不能滿足站點對於搜尋功能的要求,目前大資料時代想要從海量資料中獲取必要資料,建立強大的全文檢索系統十分必要。
2. 全文檢索系統設計與實現策略
2.1. 系統的架構
這裡用一張圖說明:

2.2. 模組設計
全文檢索大體分兩個過程:
索引建立(Indexer)和 搜尋索引(Search)。
搜尋索引:就是得到使用者的查詢請求,搜尋建立的索引,然後返回結果的過程。
2.2.1. 資訊處理
資訊處理模組的核心就是索引的建立。
索引裡面究竟存些什麼?(Index)
索引所儲存的資訊一般如下:
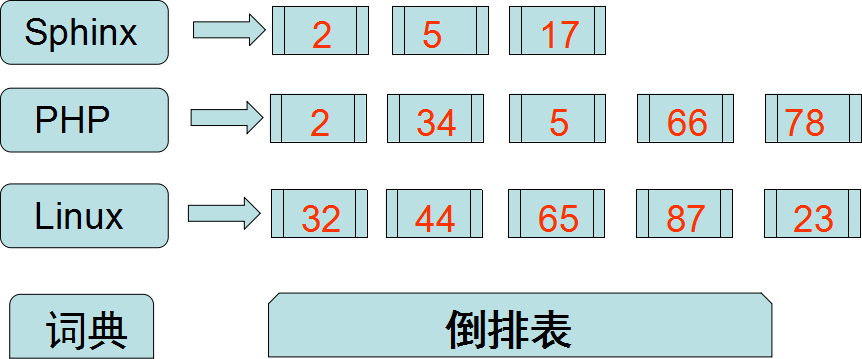
假設我現在有100篇文件,從1到100表示。
詞典: 儲存的是一系列的字串。
倒排表: 指向包含字串的文件連結串列。
如何建立索引?
全文檢索的索引建立過程一般有以下幾步:
一些需要建立索引的文件(Documents)。
將原文件傳給分片語件(Tokenizer) 。
將得到的詞元(Token)傳給語言處理元件(Linguistic Processor)。
將得到的詞(Term)傳給索引元件(Indexer)。
合併相同的詞(Term)成為文件倒排(Posting List)連結串列

Document Frequenc :即文件頻次,表示總共有多少檔案包含此詞(Term)
Frequency :即詞頻率,表示此檔案中包含了幾個此詞(Term)
補充:建立索引是系統的核心任務,需對主題詞典處理、資訊消重、文件建模、文件分析和過濾以及建立倒排索引。還需要要處理停詞(如一些意義不大的虛詞)。
2.2.2. 查詢服務
查詢服務的重點是搜尋索引。
如何對索引進行搜尋
搜尋主要分為以下幾步:
第一步:使用者輸入查詢語句.
第二步:對查詢語句進行詞法分析,語法分析,及語言處理
第三步:搜尋索引,得到符合語法樹的文件.
第四步:根據得到的文件和查詢語句的相關性,對結果進行排序.
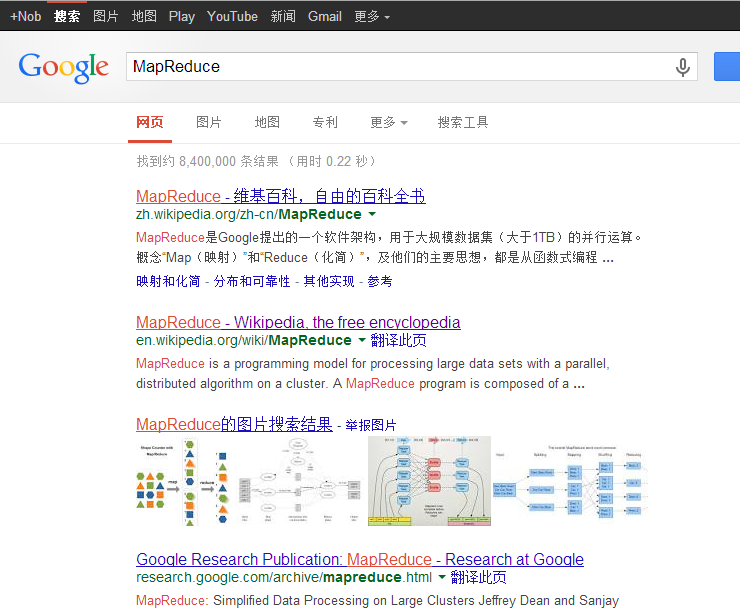
檢視Google搜尋:
2.3. 系統整體運作流程
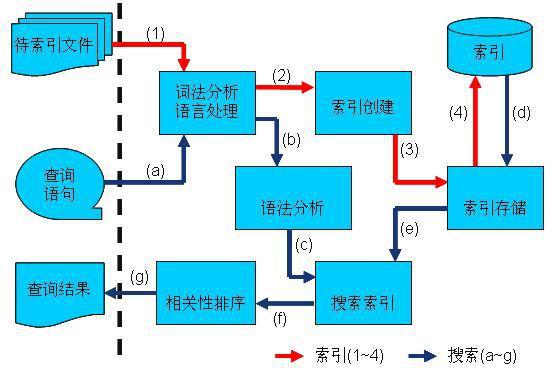
2.3.1. 索引過程:
(1)、有一系列被索引檔案
(2)、被索引檔案經過語法分析和語言處理形成一系列詞(Term)。
(3)、經過索引建立形成詞典和反向索引表。
(4)、通過索引儲存將索引寫入硬碟。
2.3.2. 搜尋過程:
(a) 使用者輸入查詢語句。
(b) 對查詢語句經過語法分析和語言分析得到一系列詞(Term)。
(c) 通過語法分析得到一個查詢樹。
(d) 通過索引儲存將索引讀入到記憶體。
(e) 利用查詢樹搜尋索引,從而得到每個詞(Term)的文件連結串列,對文件連結串列進行交,差,並得到結果文件。
(f) 將搜尋到的結果文件對查詢的相關性進行排序。
(g) 返回查詢結果給使用者。
3. 實驗/系統執行(Experiment)
3.1. 實驗的目標
實驗的搜尋引擎能夠正常執行,索引和檢索兩個階段的工作。通過本次實驗,將驗證筆者設計設計思路的可行性。
基於開源的搜尋引擎coreseek來搭建本次實驗系統。Coreseek是基於Sphinx的中文全文檢索系統,良好的支援了中文分詞。但是基本原理是配置方法和Sphinx類似。
Sphinx是一個基於SQL的全文檢索引擎,可以結合MySQL,PostgreSQL做全文搜尋,它可以提供比資料庫本身更專業的搜尋功能,使得應用程式更容易實現專業化的全文檢索。
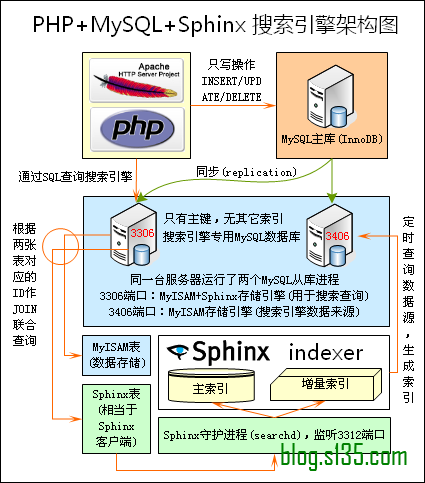
3.2. 實驗步驟
(1)、準備工作(略)
(2)、建立資料來源(略)
(3)、安裝測試coreseek(請參考我的另一篇博文)
(4)、搭建php WEB全文檢索
#search.php
SetServer ( '127.0.0.1', 9312);
$cl->SetConnectTimeout ( 3 );
$cl->SetArrayResult ( true );
$cl->SetMatchMode ( SPH_MATCH_ANY);
$res = $cl->Query ( $keyword, "*" );
$info = array();
if ($res != null) {
$info['id'] = $res ['id'];
$info['total'] = $res ['total'];
$info['time'] = $res ['time'];
$idarr = array();
foreach ( $res ['matches'] as $doc ) {
$idarr[] = $doc['id'];
}
//從mysql中檢索結果id
$ids = join ( ',', $idarr );
mysql_connect ( "localhost", "root", "" );
mysql_select_db ( "fulltext" );
$sql = "select * from documents where id in({$ids})";
mysql_query ( "set names utf8" );
$resdb = mysql_query ($sql);
//設定高亮屬性
$opts = array(
'before_match'=>"",
'after_match'=>""
);
$htmlres = array();
while ($row = mysql_fetch_assoc($resdb)) {
$res2 = $cl->BuildExcerpts($row, "mysql",$keyword, $opts);
$id = $res2[0];
echo $title = $res2[1];
echo $content = $res2[2];
$htmlres[] = array('id'=>$id,'title'=>$title,'content'=>$content);
}
}
$_SESSION['info'] = $info;
$_SESSION['htmlres'] = $htmlres;
header("Location: index.php"); 其餘內容請參見原文