
一篇關於java爬蟲實現的技術分享
最近由於工作的需要,獨自開始研究爬蟲爬取網際網路資料;經過兩週左右的探究,踩過許多坑,也學習到了許多以往不知道的知識。
一直都在做伸手黨,很是慚愧_(:_」∠)_感覺都要臉紅了☺,在這裡總結一下經驗,順便分享給大家,希望可以幫助到有需要的朋友。爬蟲技術不是很成熟,如果能有大佬能夠不吝賜教那就更好啦~

在網上找了許多資料,爬蟲工具大多是用python實現的;因為本身是學java出身,雖說python比java容易,但也沒更多時間去學習新的語言了。最終還是選擇了用java來實現,廢話不多說⁄(⁄ ⁄•⁄ω⁄•⁄ ⁄)⁄下面進入正題。
本篇爬蟲技術分享是用java+selenium+phantomjs在windows
首先借用網路上的資料來介紹下兩個小工具:
selenium
Selenium是一個用於Web應用程式測試的工具。Selenium測試直接執行在瀏覽器中,就像真正的使用者在操作一樣。支援的瀏覽器包括IE、Mozilla Firefox、Mozilla Suite等。這個工具的主要功能包括:測試與瀏覽器的相容性——測試你的應用程式看是否能夠很好得工作在不同瀏覽器和作業系統之上。測試系統功能——建立衰退測試檢驗軟體功能和使用者需求。支援自動錄製動作和自動生成。Net、Java、Perl等不同語言的測試指令碼。Selenium 是ThoughtWorks專門為Web應用程式編寫的一個驗收測試工具。
selenium的使用:
maven配置好就可以自動下載,配置如下
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>2.48.0</version>
</dependency>
自動下載了以下jar包,只用到部分
selenium-java-2.48.0.jar
selenium-chrome-driver-2.48.0.jar
selenium-remote-driver-2.48.0.jar
selenium-edge-driver-2.48.0.jar
selenium-htmlunit-driver-2.48.0.jar
selenium-firefox-driver-2.48.0.jar
selenium-ie-driver-2.48.0.jar
selenium-safari-driver-2.48.0.jar
selenium-support-2.48.0.jar
selenium-leg-rc-2.48.0.jar
selenium使用中可能會遇到的呼叫報錯的問題,很大的原因是瀏覽器驅動與瀏覽器不相容,以下是chrome瀏覽器驅動與瀏覽器相容的版本對應關係表,根據本地的chrome瀏覽器下載對應版本的chromedriver
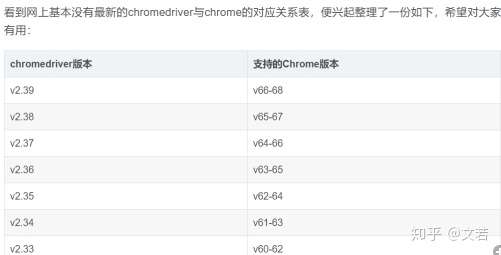
下載完後把壓縮包中的chromedriver.exe放入正常的谷歌瀏覽器安裝目錄,與chrome.exe同目錄中就可以了
phantomjs
(1)一個基於webkit核心的無頭瀏覽器,即沒有UI介面,即它就是一個瀏覽器,只是其內的點選、翻頁等人為相關操作需要程式設計實現。
(2)提供JavaScript API介面,即通過編寫js程式可以直接與webkit核心互動,在此之上可以結合Java語言等,通過java呼叫js等相關操作,從而解決了以前c/c++才能比較好的基於webkit開發優質採集器的限制。
(3)提供windows、Linux、mac等不同os的安裝使用包,也就是說可以在不同平臺上二次開發採集專案或是自動專案測試等工作。
phantomjs的使用:
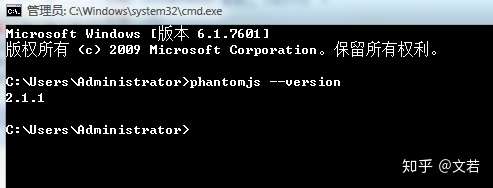
下載完後是一個壓縮包,直接解壓即可,解壓完後把phantomjs的bin路徑配置到系統環境變數path中,配置完後cmd測試出現以下資訊則已經可以使用
本篇中的爬蟲,整體流程比較簡單,細節部分需要多多注意,原始碼中都有註釋,大致如下:
類中導包資訊:
import java.io.File;
import java.io.FileInputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import org.apache.commons.io.FileUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.openqa.selenium.By;
import org.openqa.selenium.OutputType;
import org.openqa.selenium.TakesScreenshot;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import jxl.Cell;
import jxl.Sheet;
import jxl.Workbook;
流程開始
1.首先讀取excel檔案,讀取excel中的搜尋條件
貼出原始碼:
public static List<String> readExcel(String excelFilePath){
List<String> contents = new ArrayList<String>();
InputStream in = null;
try {
// 1、構造excel檔案輸入流物件
in = new FileInputStream(excelFilePath);
// 2、宣告工作簿物件
Workbook rwb = Workbook.getWorkbook(in);
// 3、獲得工作簿的個數,對應於一個excel中的工作表個數
rwb.getNumberOfSheets();
// 使用索引形式獲取第一個工作表,也可以使用rwb.getSheet(sheetName);其中sheetName表示的是工作表的名稱
Sheet oFirstSheet = rwb.getSheet(0);
int rows = oFirstSheet.getRows();//獲取工作表中的總行數,排除第一行
int columns = oFirstSheet.getColumns();//獲取工作表中的總列數
for (int i = 1; i < rows; i++) {
for (int j = 0; j < columns; j++) {
Cell oCell = oFirstSheet.getCell(j,i);//需要注意的是這裡的getCell方法的引數,第一個是指定第幾列,第二個引數才是指定第幾行
String companyName = oCell.getContents();
//判斷當前資料夾是否已存在(已經完成爬取),如存在則不加入爬取列表中
String txtUrl = ThirdPartyProperties.FILEPROFIX + companyName + "/result";//檔案路徑
File file = new File(txtUrl);
File fileParent = file.getParentFile();
//檔案路徑存在則跳過
if(fileParent.exists()){
log.info(companyName+"-已經爬取完成,不再加入爬取列表中");
}else{
contents.add(companyName);
}
}
}
} catch (Exception e) {
log.error(e.getMessage(),e);
} finally {
if(null != in){
try {
in.close();
} catch (Exception e2) {
log.error(e2.getMessage(),e2);
}
}
}
return contents;
}
2.使用selenium呼叫chrome瀏覽器訪問百度,獲取到頁面元素後模擬輸入搜尋條件並且百度一下進入搜尋結果頁,並且獲取前count條查詢結果的url
貼出原始碼:
public static String[] getLinkBySelenium(String keyWord, int count){
WebDriver driver = null;
String[] url = new String[count];
try {
// 設定 ie 的路徑
// System.setProperty("webdriver.ie.driver", "C:\\Program Files\\Internet Explorer\\IEDriverServer.exe");
// 設定 chrome 的路徑
System.setProperty("webdriver.chrome.driver", "你瀏覽器驅動的全路徑");
// 建立一個 ie 的瀏覽器例項
// driver = new InternetExplorerDriver();
// 建立一個 chrome 的瀏覽器例項
driver = new ChromeDriver();
//最大化
driver.manage().window().maximize();
//訪問百度
driver.get("http://www.baidu.com");
//根據頁面元素 xpath ,右鍵元素可獲取//*[@id="kw"],這是百度的輸入框
WebElement element = driver.findElement(By.xpath("//*[@id=\"kw\"]"));
element.sendKeys(keyWord);
//根據id獲取元素 su ,百度一下的按鈕
element = driver.findElement(By.id("su"));
//點選
element.click();
//等待5秒,等第count條查詢結果載入完
WebDriverWait wait = new WebDriverWait(driver, 5);
//等待搜尋結果載入完畢,如果報錯,說明等待時間過長或者沒有搜尋結果(百度搜索結果div主鍵為1,2,3...)
try {
wait.until(ExpectedConditions.presenceOfElementLocated(By.id(count+"")));
} catch (Exception e) {
log.error(keyWord+",該公司百度超時或沒有"+count+"條搜尋結果---");
}
/**截圖儲存*/
//截圖路徑
String imageUrl = "你要儲存截圖的路徑" + keyWord + "/screenshot.png";//截圖路徑
//指定了OutputType.FILE做為引數傳遞給getScreenshotAs()方法,其含義是將擷取的螢幕以檔案形式返回。
File srcFile = ((TakesScreenshot)driver).getScreenshotAs(OutputType.FILE);
//利用FileUtils工具類的copyFile()方法儲存getScreenshotAs()返回的檔案物件。
FileUtils.copyFile(srcFile, new File(imageUrl));
for (int i = 1; i <= count; i++) {
//獲取頁面載入的第一條搜尋結果
WebElement div = driver.findElement(By.id(i+"")).findElement(By.tagName("h3")).findElement(By.tagName("a"));
//部分公司百度沒有搜尋結果,在此跳出處理
if(null == div){
continue;
}
url[i-1] = div.getAttribute("href");
}
} catch (Exception e) {
log.error(e.getMessage(),e);
} finally {
//關閉瀏覽器(這個包括驅動完全退出,會清除記憶體),close 是隻關閉瀏覽器
driver.quit();
}
return url;
}
3.呼叫phantomjs訪問獲取到的url,截圖,並通過輸入流拿回需要的資料,寫入檔案儲存本地。
貼出原始碼:
public static void getParseredHtml2(String companyName, String[] url) throws IOException {
//獲取本地專案路徑並處理(windows環境下)
String projectPath = ReptilianWork.class.getClassLoader().getResource("/").getPath();
projectPath = projectPath.substring(1, projectPath.length()).replace("classes/", "");
// String projectPath = "D:/Work/workSpace——eclipse/.metadata/.plugins/org.eclipse.wst.server.core/tmp0/wtpwebapps/JavaReptilian/WEB-INF/";
//js路徑
String jsPath = projectPath + "js/huicong.js";
Date date = new Date();
SimpleDateFormat formatter = new SimpleDateFormat("yyyyMMddHHmmss");
String dateName = formatter.format(date);//名稱
String imageSuffix = ".png";
String txtSuffix = ".txt";
for (int i = 1; i <= url.length; i++) {
InputStream in = null;
FileWriter writer = null;
String content = "";
try {
String imageUrl = "你的儲存路徑" + companyName + "/result"+i + "/image/";//截圖路徑
String txtUrl = "你的儲存路徑" + companyName + "/result"+i + "/txt/";//檔案路徑
File file = new File(txtUrl+dateName+txtSuffix);
File fileParent = file.getParentFile();
//檔案路徑存在則跳過
// if(fileParent.exists()){
// log.info(companyName+"-已經爬取完成,不再爬取");
// break;
// }
Runtime rt = Runtime.getRuntime();
log.info("phantomjs訪問url="+url[i-1]);
Process p = rt.exec("phantomjs的安裝路徑(phantomjs.exe的全路徑)" + " " + jsPath + " " + url[i-1] + " " + imageUrl + " " + dateName+imageSuffix);
in = p.getInputStream();
Document doc = Jsoup.parse(in, "UTF-8", url[i-1]);
content = doc.body().text();
//檔案路徑不存在則建立
if(!fileParent.exists()){
fileParent.mkdirs();
}
//建立檔案
file.createNewFile();
writer = new FileWriter(file);
if(content!=null && !"".equals(content)){
writer.write(content);
log.info("檔案寫入成功,路徑:"+txtUrl+dateName+txtSuffix);
}
in.close();
writer.flush();
writer.close();
} catch (Exception e) {
log.error(e.getMessage(),e);
} finally{
if(in!=null){
in.close();
}
if(writer!=null){
writer.close();
}
}
}
}
以上方法使用了Jsoup來解析java呼叫phantomjs後拿到的輸入流並轉成了document物件來操作獲取所有文字資訊。有關於Jsoup的介紹如下:
jsoup 是一款Java 的HTML解析器,可直接解析某個URL地址、HTML文字內容。它提供了一套非常省力的API,可通過DOM,CSS以及類似於jQuery的操作方法來取出和操作資料。
要使用的話,maven配置如下:
<!-- jsoup 一款Java的HTML解析器 -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.8.3</version>
</dependency>
步驟3方法中使用到的huicong.js檔案。注意(一定要設定超時時間,否則遇到一些訪問連線有問題或者網路問題等,會導致phantomjs卡住,程式會一直等待響應)
system = require('system')
address = system.args[1];
imageUrl = system.args[2];
imageName = system.args[3];
var page = require('webpage').create();
var url = address;
var fs = require('fs');
fs.makeDirectory(imageUrl);
//設定超時時間
page.settings.resourceTimeout = 5000; // 5 seconds
page.onResourceTimeout = function(e) {
console.log(e.errorCode); // it'll probably be 408
console.log(e.errorString); // it'll probably be 'Network timeout on resource'
console.log(e.url); // the url whose request timed out
phantom.exit(1);
};
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('請求失敗!url='+url);
phantom.exit();
} else {
window.setTimeout(function () {
page.render(imageUrl+imageName); //截圖
console.log(page.content);
phantom.exit();
}, 5000);
}
});
原始碼的縮排由於這邊編輯器的問題亂了╮(╯▽╰)╭強迫症將就看吧哈哈
呼叫以上方法的程式碼就不貼了
大概就是讀取到excel中所有的搜尋條件後
迴圈呼叫getLinkBySelenium,獲取到需要爬取的多個url後,呼叫getParseredHtml2方法
----------------------割一下-----------------------------
以上,就爬取到了百度的部分資料,謝謝大家的閱讀
如有問題可以直接提問,本人看到會回答的
這也是第一次分享自己的學習經驗~
如果有人關注考慮貼出後面的多執行緒呼叫方法,因為phantomjs的訪問速度對於需要爬取大量資料來講實在太慢了(;´д`)ゞ

如果沒人關注,就當自己的學習筆記了

如果對你有用,別忘了點贊_( ̄0 ̄)_[哦~] 告辭~~