
linux核心SMP負載均衡淺析
需求
在《linux程序排程淺析》一文中提到,在SMP(對稱多處理器)環境下,每個CPU對應一個run_queue(可執行佇列)。如果一個程序處於TASK_RUNNING狀態(可執行狀態),則它會被加入到其中一個run_queue(且同一時刻僅會被加入到一個run_queue),以便讓排程程式安排它在這個run_queue對應的CPU上面執行。
一個CPU對應一個run_queue這樣的設計,其好處是:
1、一個持續處於TASK_RUNNING狀態的程序總是趨於在同一個CPU上面執行(其間,這個程序可能被搶佔、然後又被排程),這有利於程序的資料被CPU所快取,提高執行效率;
2、各個CPU上的排程程式只訪問自己的run_queue,避免了競爭;
然而,這樣的設計也可能使得各個run_queue裡面的程序不均衡,造成“一些CPU閒著、一些CPU忙不過來”混亂局面。為了解決這個問題,load_balance(負載均衡)就登場了。
load_balance所需要做的事情就是,在一定的時機,通過將程序從一個run_queue遷移到另一個run_queue,來保持CPU之間的負載均衡。
這裡的“均衡”二字如何定義?load_balance又具體要做哪些事情呢?對於不同調度策略(實時程序 OR 普通程序),有著不同的邏輯,需要分開來看。
實時程序的負載均衡
實時程序的排程是嚴格按照優先順序來進行的。在單CPU環境下,CPU上執行著的總是優先順序最高的程序,直到這個程序離開TASK_RUNNING狀態,新任的“優先順序最高的程序”才開始得到執行。
推廣到SMP環境,假設有N個CPU,N個CPU上分別執行著的也必須是優先順序最高的top-N個程序。如果實時程序不足N個,那麼剩下的CPU才分給普通程序去使用。對於實時程序來說,這就是所謂的“均衡”。
實時程序的優先順序關係是很嚴格的,當優先順序最高的top-N個程序發生變化時,核心必須馬上響應:
1、如果這top-N個程序當中,有一個離開TASK_RUNNING狀態、或因為優先順序被調低而退出top-N集團,則原先處於(N+1)位的那個程序將進入top-N。核心需要遍歷所有的run_queue,把這個新任的top-N程序找出來,然後立馬讓它開始執行;
2、反之,如果一個top-N之外的實時程序的優先順序被調高,以至於擠佔了原先處於第N位的程序,則核心需要遍歷所有的run_queue,把這個被擠出top-N的程序找出來,將它正在佔用的CPU讓給新進top-N的那個程序去執行;
在這幾種情況下,新進入top-N的程序和退出top-N的程序可能原本並不在同一個CPU上,那麼在它得到執行之前,核心會先將其遷移到退出top-N的程序所在的CPU上。
具體來說,核心通過pull_rt_task和push_rt_task兩個函式來完成實時程序的遷移:
pull_rt_task - 把其他CPU的run_queue中的實時程序pull過來,放到當前CPU的run_queue中。被pull過來的實時程序要滿足以下條件:
1、程序是其所在的run_queue中優先順序第二高的(優先順序最高的程序必定正在執行,不需要移動);
2、程序的優先順序比當前run_queue中最高優先順序的程序還要高;
3、程序允許在當前CPU上執行(沒有親和性限制);
該函式會在以下時間點被呼叫:
1、發生排程之前,如果prev程序(將要被替換下去的程序)是實時程序,且優先順序高於當前run_queue中優先順序最高的實時程序(這說明prev程序已經離開TASK_RUNNING狀態了,否則它不會讓位於比它優先順序低的程序);
2、正在執行的實時程序優先順序被調低時(比如通過sched_setparam系統呼叫);
3、正在執行的實時程序變成普通程序時(比如通過sched_setscheduler系統呼叫);
push_rt_task - 把當前run_queue中多餘的實時程序推給其他run_queue。需要滿足以下條件:
1、每次push一個程序,這個程序的優先順序在當前run_queue中是第二高的(優先順序最高的程序必定正在執行,不需要移動);
2、目標run_queue上正在執行的不是實時程序(是普通程序),或者是top-N中優先順序最低的實時程序,且優先順序低於被push的程序;
3、被push的程序允許在目標CPU上執行(沒有親和性限制);
4、滿足條件的目標run_queue可能存在多個(可能多個CPU上都沒有實時程序在執行),應該選擇與當前CPU最具親緣性的一組CPU中的第一個CPU所對應的run_queue作為push的目標(順著sched_domain--排程域--逐步往上,找到第一個包含目標CPU的sched_domain。見後面關於sched_domain的描述);
該函式會在以下時間點被呼叫:
1、非正在執行的普通程序變成實時程序時(比如通過sched_setscheduler系統呼叫);
2、發生排程之後(這時候可能有一個實時程序被更高優先順序的實時程序搶佔了);
3、實時程序被喚醒之後,如果不能馬上在當前CPU上執行(它不是當前CPU上優先順序最高的程序);
看起來,實時程序的負載均衡對於每個CPU一個run_queue這種模式似乎有些彆扭,每次需要選擇一個實時程序,總是需要遍歷所有run_queue,在尚未能得到執行的實時程序之中找到優先順序最高的那一個。其實,如果所有CPU共用同一個run_queue,就沒有這麼多的煩惱了。為什麼不這樣做呢?
1、在CPU對run_queue的競爭方面,“每個CPU去競爭每一個run_queue”比“每個CPU去競爭一個總的run_queue”略微好一些,因為競爭的粒度更小了;
2、在程序的移動方面,每個CPU一個run_queue這種模式其實也不能很好的把程序留在同一個CPU上,因為嚴格的優先順序關係使得程序必須在出現不均衡時立刻被移動。不過,一些特殊情況下程序的遷移還是有一定選擇面的。比如優先順序相同的時候就可以儘量不做遷移、push_rt_task的時候可以選擇跟當前CPU最為親近的CPU去遷移。
普通程序的負載均衡
可以看出,實時程序的負載均衡效能是不會太好的。為了滿足嚴格的優先順序關係,絲毫的不均衡都是不能容忍的。所以一旦top-N的平衡關係發生變化,核心就必須即時完成負載均衡,形成新的top-N的平衡關係。這可能會使得每個CPU頻繁去競爭run_queue、程序頻繁被遷移。
而普通程序則並不要求嚴格的優先順序關係,可以容忍一定程度的不均衡。所以普通程序的負載均衡可以不必在程序發生變化時即時完成,而採用一些非同步調整的策略。
普通程序的負載均衡在以下情況下會被觸發:
1、當前程序離開TASK_RUNNING狀態(進入睡眠或退出),而對應的run_queue中已無程序可用時。這時觸發負載均衡,試圖從別的run_queue中pull一個程序過來執行;
2、每隔一定的時間,啟動負載均衡過程,試圖發現並解決系統中不均衡;
另外,對於呼叫exec的程序,它的地址空間已經完全重建了,當前CPU上已經不會再快取對它有用的資訊。這時核心也會考慮負載均衡,為它們找一個合適的CPU。
那麼,對於普通程序來說,“均衡”到底意味著什麼呢?
在單CPU環境下,處於TASK_RUNNING狀態的程序會以其優先順序為權重,瓜分CPU時間。優先順序越高的程序,權重越高,分得的CPU時間也就越多。在CFS排程(完全公平排程,針對普通程序的排程程式)中,這裡的權重被稱作load。假設某個程序的load為m,所有處於TASK_RUNNING狀態的程序的load之和為M,那麼這個程序所能分到的CPU時間是m/M。比如系統中有兩個TASK_RUNNING狀態的程序,一個load為1、一個load為2,總的load是1+2=3。則它們分到的CPU時間分別是1/3和2/3。
推廣到SMP環境,假設有N個CPU,那麼一個load為m的程序所能分到的CPU時間應該是N*m/M(如果不是,則要麼這個程序擠佔了別的程序的CPU時間、要麼是被別的程序擠佔)。對於普通程序來說,這就是所謂的“均衡”。
那麼,如何讓程序能夠分到N*m/M的CPU時間呢?其實,只需要把所有程序的load平分到每一個run_queue上,使得每個run_queue的load(它上面的程序的load之和)都等於M/N,這樣就好了。於是,每個run_queue的load就成了是否“均衡”的判斷依據。
下面看看load_balance裡面做些什麼。注意,不管load_balance是怎樣被觸發的,它總是在某個CPU上被執行。而load_balance過程被實現得非常簡單,只需要從最繁忙(load最高)的run_queue中pull幾個程序到當前run_queue中(只pull,不push),使得當前run_queue與最繁忙的run_queue得到均衡(使它們的load接近於所有run_queue的平均load),僅此而已。load_balance並不需要考慮所有run_queue全域性的均衡,但是當load_balance在各個CPU上分別得到執行之後,全域性的均衡也就實現了。這樣的實現極大程度減小了負載均衡的開銷。
load_balance的過程大致如下:
1、找出最繁忙的一個run_queue;
2、如果找到的run_queue比本地run_queue繁忙,且本地run_queue的繁忙程度低於平均水平,那麼遷移幾個程序過來,使兩個run_queue的load接近平均水平。反之則什麼都不做;
在比較兩個run_queue繁忙程度的問題上,其實是很有講究的。這個地方很容易想當然地理解為:把run_queue中所有程序的load加起來,比較一下就OK了。而實際上,需要比較的往往並不是實時的load。
這就好比我們用top命令檢視CPU佔用率一樣,top命令預設1秒重新整理一次,每次重新整理你將看到這1秒內所有程序各自對CPU的佔用情況。這裡的佔用率是個統計值,假設有一個程序在這1秒內持續運行了100毫秒,那麼我們認為它佔用了10%的CPU。如果把1秒重新整理一次改成1毫秒重新整理一次呢?那麼我們將有90%的機率看到這個程序佔用0%的CPU、10%的機率佔用100%的CPU。而無論是0%、還是100%,都不是這個程序真實的CPU佔用率的體現。必須把一段時間以內的CPU佔用率綜合起來看,才能得到我們需要的那個值。
run_queue的load值也是這樣。有些程序可能頻繁地在TASK_RUNNING和非TASK_RUNNING狀態之間變換,導致run_queue的load值不斷抖動。光看某一時刻的load值,我們是體會不到run_queue的負載情況的,必須將一段時間內的load值綜合起來看才行。於是,run_queue結構中維護了一個儲存load值的陣列:
unsigned long cpu_load[CPU_LOAD_IDX_MAX] (目前CPU_LOAD_IDX_MAX值為5)
每個CPU上,每個tick的時鐘中斷會呼叫到update_cpu_load函式,來更新該CPU所對應的run_queue的cpu_load值。這個函式值得羅列一下:
/* this_load就是run_queue實時的load值 */
unsigned long this_load = this_rq->load.weight;
for (i = 0, scale = 1; i < CPU_LOAD_IDX_MAX; i++, scale += scale) {
unsigned long old_load = this_rq->cpu_load[i];
unsigned long new_load = this_load;
/* 因為最終結果是要除以scale的,這裡相當於上取整 */
if (new_load > old_load)
new_load += scale-1;
/* cpu_load[i] = old_load + (new_load - old_load) / 2^i */
this_rq->cpu_load[i] = (old_load*(scale-1) + new_load) >> i;
}
cpu_load[i] = old_load + (new_load - old_load) / 2^i。i值越大,cpu_load[i]受load的實時值的影響越小,代表著越長時間內的平均負載情況。而cpu_load[0]就是實時的load。
儘管我們需要的是一段時間內的綜合的負載情況,但是,為什麼不是儲存一個最合適的統計值,而要儲存這麼多的值呢?這是為了便於在不同場景下選擇不同的load。如果希望進行程序遷移,那麼應該選擇較小的i值,因為此時的cpu_load[i]抖動比較大,容易發現不均衡;反之,如果希望保持穩定,那麼應該選擇較大的i值。
那麼,什麼時候傾向於進行遷移、什麼時候又傾向於保持穩定呢?這要從兩個維度來看:
第一個維度,是當前CPU的狀態。這裡會考慮三種CPU狀態:
1、CPU剛進入IDLE(比如說CPU上唯一的TASK_RUNNING狀態的程序睡眠去了),這時候是很渴望馬上弄一個程序過來執行的,應該選擇較小的i值;
2、CPU處於IDLE,這時候還是很渴望弄一個程序過來執行的,但是可能已經嘗試過幾次都無果了,故選擇略大一點的i值;
3、CPU非IDLE,有程序正在執行,這時候就不太希望程序遷移了,會選擇較大的i值;
第二個維度,是CPU的親緣性。離得越近的CPU,程序遷移所造成的快取失效的影響越小,應該選擇較小的i值。比如兩個CPU是同一物理CPU的同一核心通過SMT(超執行緒技術)虛擬出來的,那麼它們的快取大部分是共享的。程序在它們之間遷移代價較小。反之則應該選擇較大的i值。(後面將會看到linux通過排程域來管理CPU的親緣性。)
至於具體的i的取值,就是具體策略的問題了,應該是根據經驗或實驗結果得出來的,這裡就不贅述了。
排程域
前面已經多次提到了排程域(sched_domain)。在複雜的SMP系統中,為了描述CPU與CPU之間的親緣關係,引入了排程域。
兩個CPU之間的親緣關係主要有以下幾種:
1、超執行緒。超執行緒CPU是一個可以“同時”執行幾個執行緒的CPU。就像作業系統通過程序排程能夠讓多個程序“同時”在一個CPU上執行一樣,超執行緒CPU也是通過這樣的分時複用技術來實現幾個執行緒的“同時”執行的。這樣做之所以能夠提高執行效率,是因為CPU的速度比記憶體速度快很多(一個數量級以上)。如果cache不能命中,CPU在等待記憶體的時間內將無事可做,可以切換到其他執行緒去執行。這樣的多個執行緒對於作業系統來說就相當於多個CPU,它們共享著大部分的cache,非常之親近;
2、同一物理CPU上的不同核心。現在的多核CPU大多屬於這種情況,每個CPU核心都有獨立執行程式的能力,而它們之間也會共享著一些cache;
3、同一NUMA結點上的CPU;
4、不同NUMA結點上的CPU;
在NUMA(非一致性記憶體體系)中,CPU和RAM以“結點”為單位分組。當CPU訪問與它同在一個結點的“本地”RAM晶片時,幾乎不會有競爭,訪問速度通常很快。相反的,CPU訪問它所屬結點之外的“遠端”RAM晶片就會非常慢。
(排程域可以支援非常複雜的硬體系統,但是我們通常遇到的SMP一般是:一個物理CPU包含N個核心。這種情況下,所有CPU之間的親緣性都是相同的,引入排程域的意義其實並不大。)
程序在兩個很親近的CPU之間遷移,代價較小,因為還有一部分cache可以繼續使用;在屬於同一NUMA結點上的兩個CPU之間遷移,雖然cache會全部丟失,但是好歹記憶體訪問的速度是相同的;如果程序在屬於不同NUMA結點的兩個CPU之間遷移,那麼這個程序將在新NUMA結點的CPU上被執行,卻還是要訪問舊NUMA結點的記憶體(程序可以遷移,記憶體卻沒法遷移),速度就要慢很多了。
通過排程域的描述,核心就可以知道CPU與CPU的親緣關係。對於關係遠的CPU,儘量少在它們之間遷移程序;而對於關係近的CPU,則可以容忍較多一些的程序遷移。
對於實時程序的負載均衡,排程域的作用比較小,主要是在push_rt_task將當前run_queue中的實時程序推到其他run_queue時,如果有多個run_queue可以接收實時程序,則按照排程域的描述,選擇親緣性最高的那個CPU對應的run_queue(如果這樣的CPU有多個,那麼約定選擇編號最小那一個)。所以,下面著重討論普通程序的負載均衡。
首先,排程域具體是如何描述CPU之間的親緣關係的呢?假設系統中有兩個物理CPU、每個物理CPU有兩個核心、每個核心又通過超執行緒技術虛擬出兩個CPU,則排程域的結構如下:
1、一個排程域是若干CPU的集合,這些CPU都是滿足一定的親緣關係的(比如至少是屬於同一NUMA結點的);
2、排程域之間存在層次關係,一個排程域可能包括多個子排程域,每個子排程域包含了父排程域的一個CPU子集,並且子排程域中的CPU滿足比父排程域更嚴格的親緣關係(比如父排程域中的CPU至少是屬於同一NUMA結點的,子排程域中的CPU至少是屬於同一物理CPU的);
3、每個CPU分別具有其對應的一組sched_domain結構,這些排程域處於不同層次,但是都包含了這個CPU;
4、每個排程域被依次劃分成多個組,每個組代表排程域的一個CPU子集;
5、最低層次的排程域包含了親緣性最近的幾個CPU、而最低層次的排程組則只包含一個CPU;
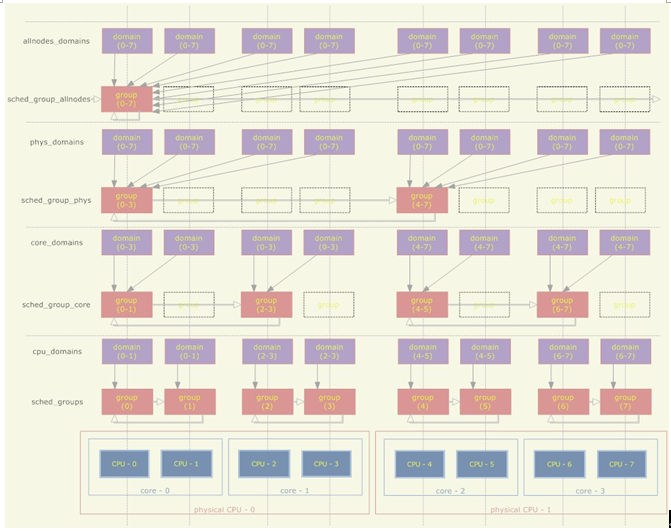
對於普通程序的負載均衡來說,在一個CPU上,每次觸發load_balance總是在某個sched_domain上進行的。低層次的sched_domain包含的CPU有著較高的親緣性,將以較高的頻率被觸發load_balance;而高層次的sched_domain包含的CPU有著較低的親緣性,將以較低的頻率被觸發load_balance。為了實現這個,sched_domain裡面記錄著每次load_balance的時間間隔,以及下次觸發load_balance的時間。
前面討論過,普通程序的load_balance第一步是需要找出一個最繁忙的CPU,實際上這是通過兩個步驟來實現的:
1、找出sched_domain下最繁忙的一個sched_group(組內的CPU對應的run_queue的load之和最高);
2、從該sched_group下找出最繁忙的CPU;
可見,load_balance實際上是實現了對應sched_domain下的sched_group之間的平衡。較高層次的sched_domain包含了很多CPU,但是在這個sched_domain上的load_balance並不直接解決這些CPU之間的負載均衡,而只是解決sched_group之間的平衡(這又是load_balance的一大簡化)。而最底層的sched_group是跟CPU一一對應的,所以最終還是實現了CPU之間的平衡。
其他問題
CPU親和力
linux下的程序可以通過sched_setaffinity系統呼叫設定程序親和力,限定程序只能在某些特定的CPU上執行。負載均衡必須考慮遵守這個限制(前面也多次提到)。
遷移執行緒
前面說到,在普通程序的load_balance過程中,如果負載不均衡,當前CPU會試圖從最繁忙的run_queue中pull幾個程序到自己的run_queue來。
但是如果程序遷移失敗呢?當失敗達到一定次數的時候,核心會試圖讓目標CPU主動push幾個程序過來,這個過程叫做active_load_balance。這裡的“一定次數”也是跟排程域的層次有關的,越低層次,則“一定次數”的值越小,越容易觸發active_load_balance。
這裡需要先解釋一下,為什麼load_balance的過程中遷移程序會失敗呢?最繁忙run_queue中的程序,如果符合以下限制,則不能遷移:
1、程序的CPU親和力限制了它不能在當前CPU上執行;
2、程序正在目標CPU上執行(正在執行的程序顯然是不能直接遷移的);
(此外,如果程序在目標CPU上前一次執行的時間距離當前時間很小,那麼該程序被cache的資料可能還有很多未被淘汰,則稱該程序的cache還是熱的。對於cache熱的程序,也儘量不要遷移它們。但是在滿足觸發active_load_balance的條件之前,還是會先試圖遷移它們。)
對於CPU親和力有限制的程序(限制1),即使active_load_balance被觸發,目標CPU也不能把它push過來。所以,實際上,觸發active_load_balance的目的是要嘗試把當時正在目標CPU上執行的那個程序弄過來(針對限制2)。
在每個CPU上都會執行一個遷移執行緒,active_load_balance要做的事情就是喚醒目標CPU上的遷移執行緒,讓它執行active_load_balance的回撥函式。在這個回撥函式中嘗試把原先因為正在執行而未能遷移的那個程序push過來。為什麼load_balance的時候不能遷移,active_load_balance的回撥函式中就可以了呢?因為這個回撥函式是執行在目標CPU的遷移執行緒上的。一個CPU在同一時刻只能執行一個程序,既然這個遷移執行緒正在執行,那麼期望被遷移的那個程序肯定不是正在被執行的,限制2被打破。
當然,在active_load_balance被觸發,到回撥函式在目標CPU上被執行之間,目標CPU上的TASK_RUNNING狀態的程序可能發生一些變化,所以回撥函式發起遷移的程序未必就只有之前因為限制2而未能被遷移的那一個,可能更多,也可能一個沒有。