
Java併發容器ConcurrentHashMap原理及HashMap死迴圈原因的分析
HashMap是我們最常用的資料結構之一,它方便高效,但遺憾的是,HashMap是執行緒不安全的,在併發環境下,在HashMap的擴容過程中,可能造成散列表的迴圈鎖死。而執行緒安全的HashTable使用了大量Synchronized鎖,導致了效率非常低下。幸運的是,併發程式設計大師Doug Lea為我們提供了ConcurrentHashMap,它是執行緒安全版的HashMap。這篇文章將為大家簡單分析一下HashMap死迴圈的原因和ConcurrentHashMap的實現原理。在此之前,想要熟悉HashMap實現原理的朋友可以參考我的文章《 》。
1 HashMap鎖死問題的分析
HashMap在併發執行put操作時會引起死迴圈,這是因為併發會導致HashMap的Entry連結串列形成環形資料結構,這樣,Entry的next節點永不為null,在散列表擴容的時候,形成迴圈的桶就永遠不會走到盡頭null,產生死迴圈。
單執行緒時的正確擴容
首先我們檢視一下HashMap中擴容的原始碼:可以知道,如果table中某一列的entry順序是A-B-C,那麼,如果擴容後,這三個entry還在一個桶中,那麼順序會反置,變成C-B-A。// 擴容操作,從一個數組轉移到另一個數組 void transfer(Entry[] newTable) { Entry[] src = table; int newCapacity = newTable.length; for (int j = 0; j < src.length; j++) { Entry<K,V> e = src[j]; if (e != null) { src[j] = null; do { Entry<K,V> next = e.next; //假設第一個執行緒執行到這裡 int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } while (e != null); // 可能導致死迴圈 } } }
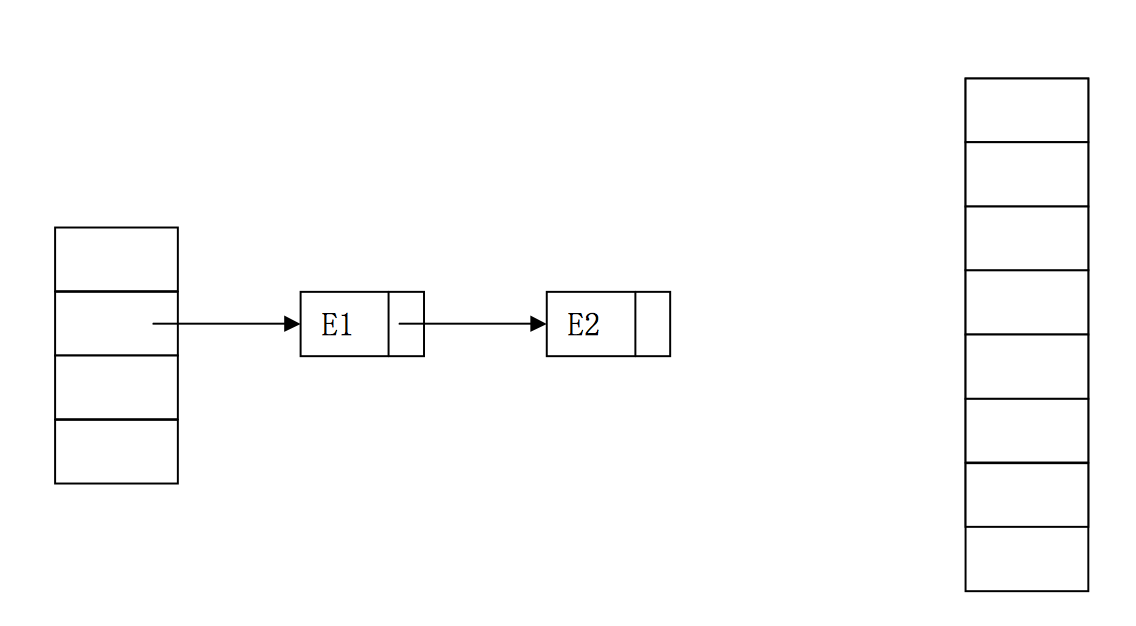
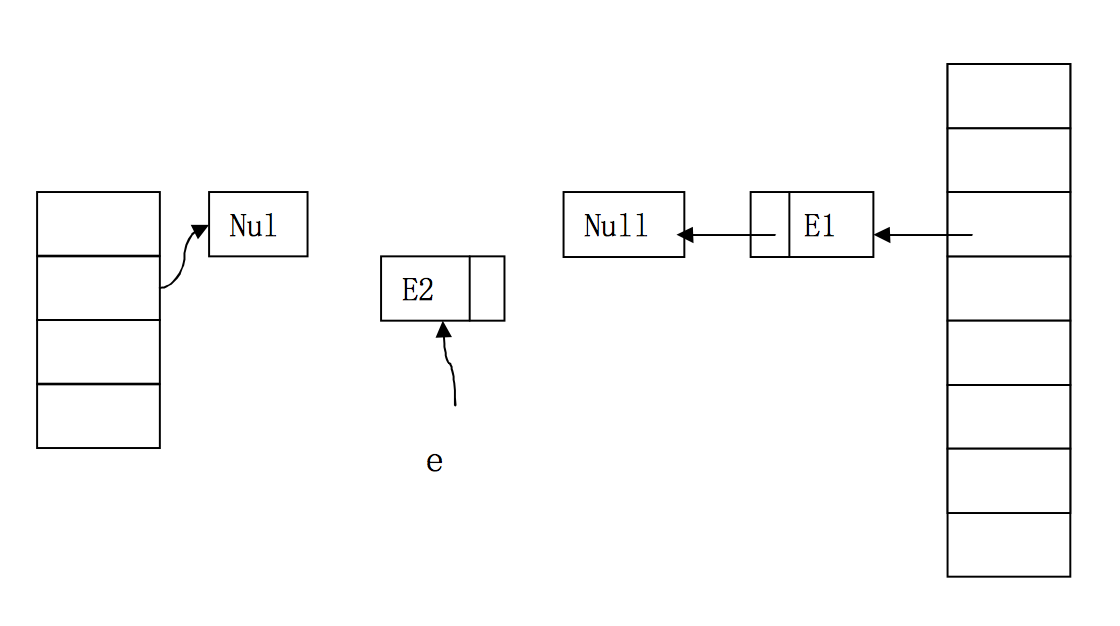
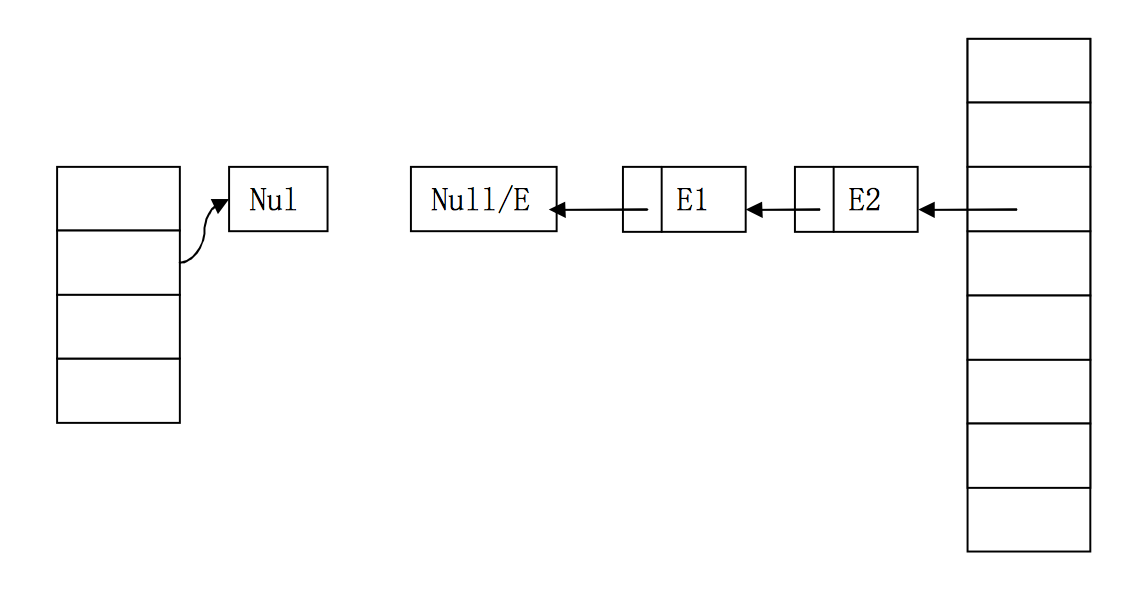
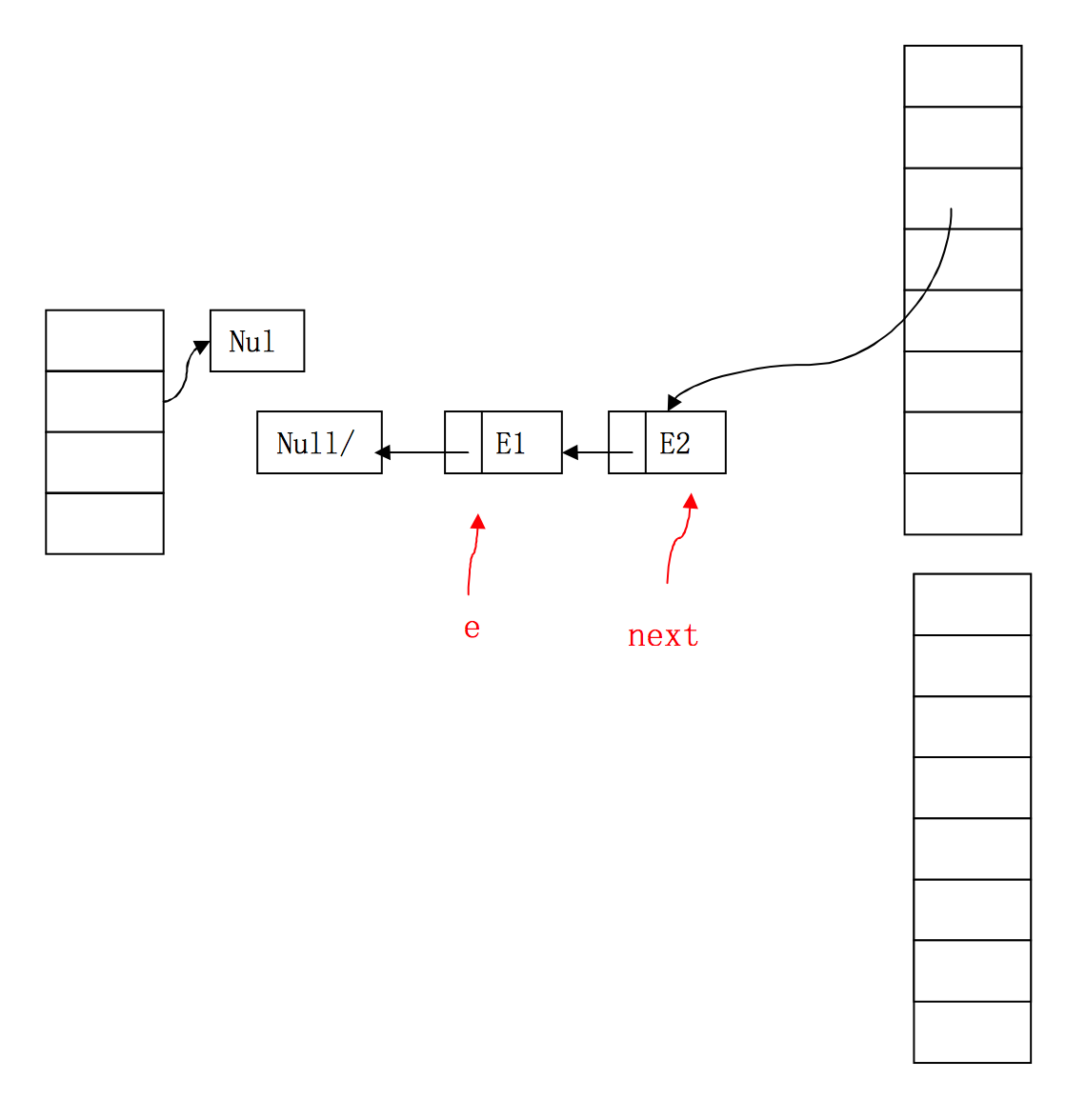
雙執行緒併發下的錯誤擴容
右邊兩個桶分別屬於執行緒1和執行緒2,他們併發執行了擴容。此時,執行緒1已經將E1和E2順利轉移到了新桶中。接著,執行緒2執行到了程式碼的第9行,已經獲得了E1和E1.next。
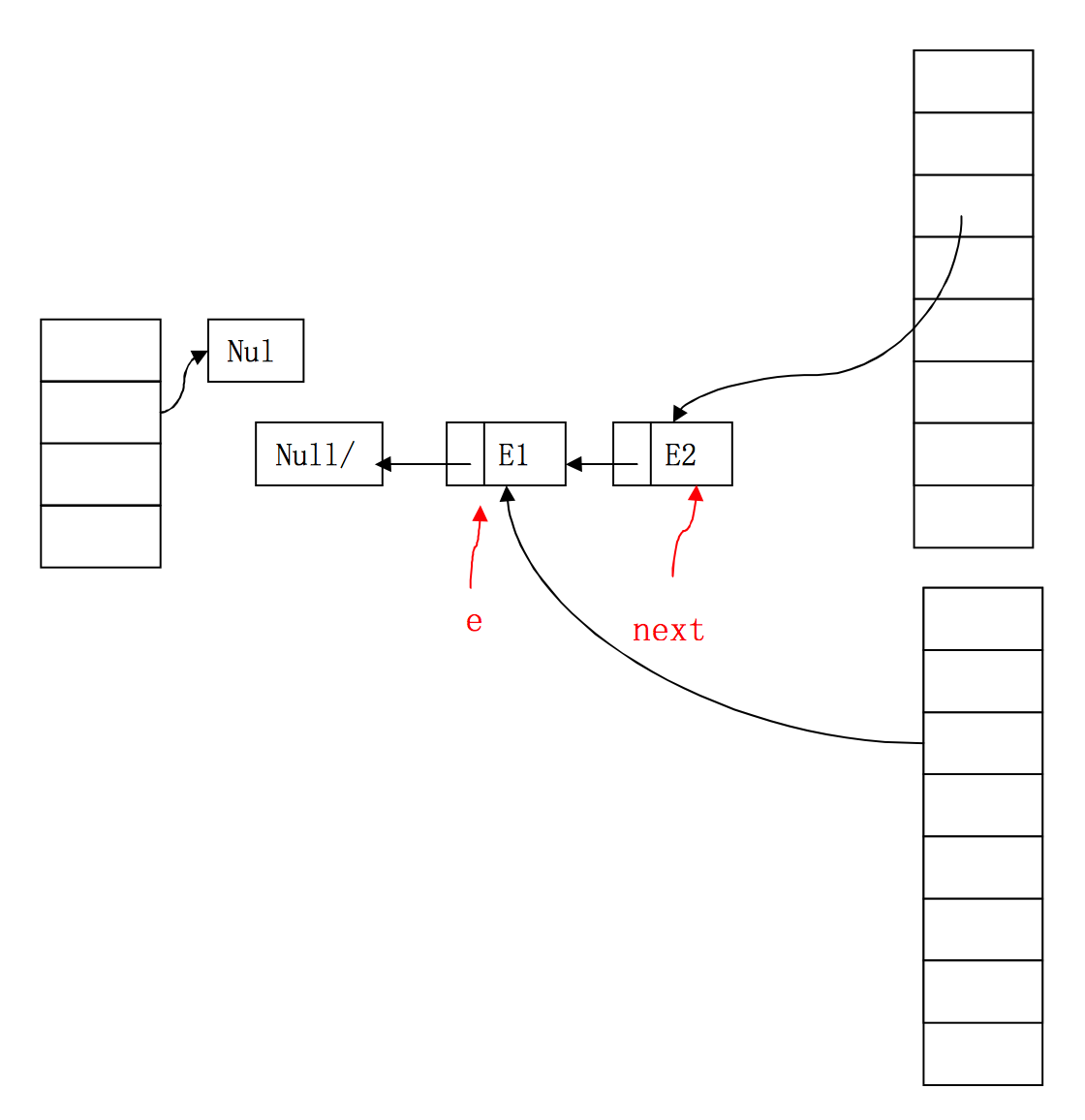
執行緒2將E1取到自己的桶中,而且雖然E1.next已經被執行緒1設為null,但在此之前,執行緒2已經獲得了E1.next即E2。

因此,執行緒2成功取到E2,並檢視下一個Entry,本來,E2.next為null,但執行緒1已經反置了順序,E2.next變成了E1!因此,執行緒2會繼續執行新增元素的操作!
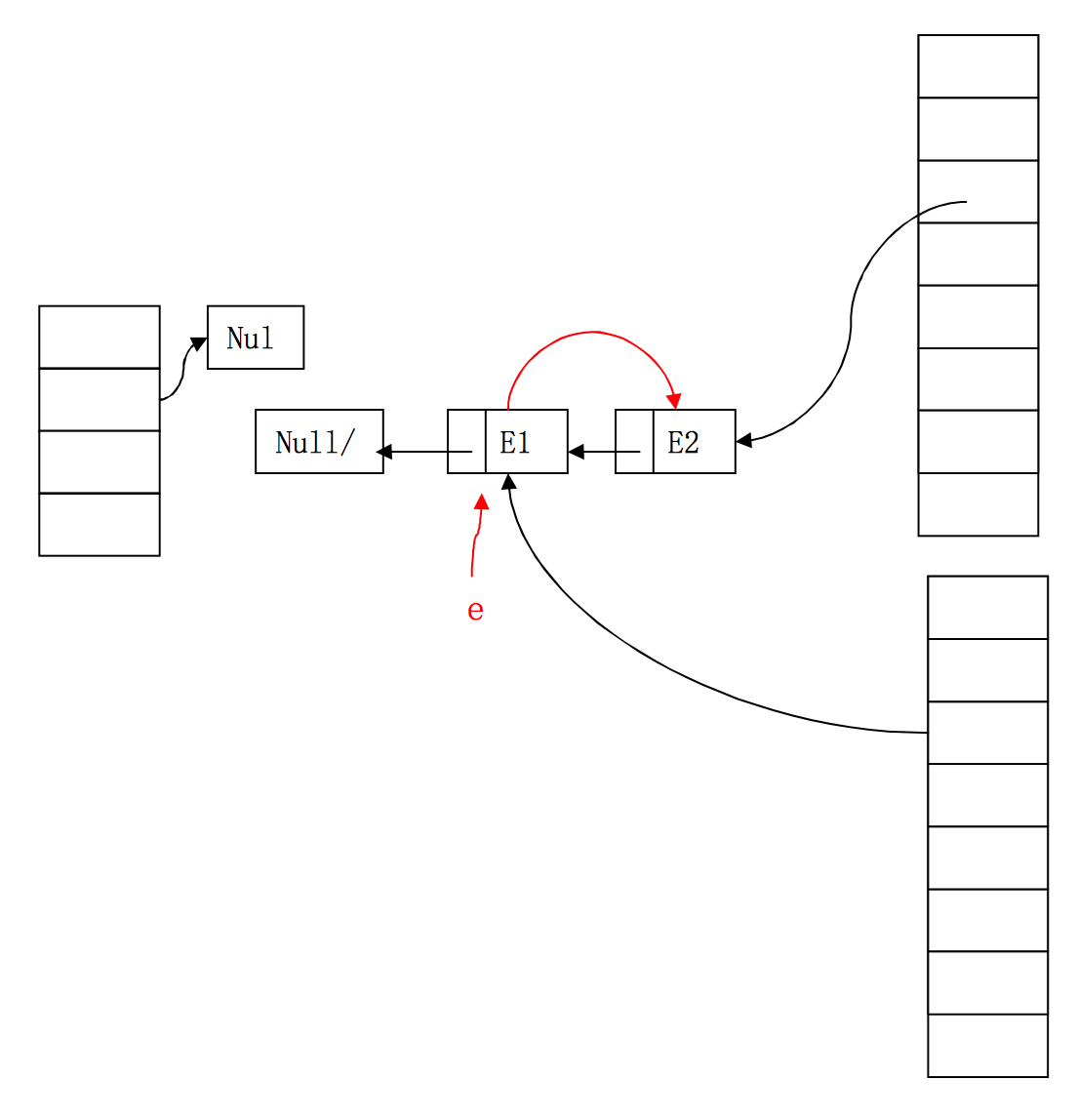
此時可以很清楚的看到,E2執行緒中的Entry已經形成了一個環形結構,擴容中對entry的遍歷永遠不會結束,造成了HashMap的死迴圈,put操作也不會停止了。
2 ConcurrentHashMap的實現
HashTable容器在競爭激烈的併發環境下表現出效率低下的原因是所有訪問HashTable的執行緒都需要競爭同一把鎖。假如容器裡有多把鎖,每一把鎖用於鎖容器中的一部分資料,那麼當多執行緒訪問容器中不同段的資料時,執行緒間將不存在鎖競爭,從而有效提高訪問效率,這就是ConcurrentHashMap的分段鎖技術。首先將資料分成一段一段地儲存,再給每段資料配一把鎖,當執行緒佔用其中一段資料的時候,其他段的資料也能被其他執行緒訪問。
結構解析
ConcurrentHashMap和Hashtable主要區別就是圍繞著鎖的粒度以及如何鎖,可以簡單理解成把一個大的HashTable分解成多個,形成了鎖分離。如圖:
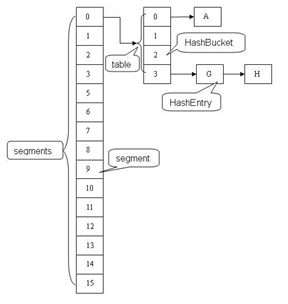
而HashTable則是鎖住了整張hash表。
原始碼解析
get操作
Segment的get操作實現非常簡單和高效。先經過一次再雜湊,然後使用這個雜湊值通過雜湊運算定位到segment,再通過雜湊演算法定位到元素,程式碼如下:public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}
put操作
由於put方法裡需要對共享變數進行寫入操作,所以為了執行緒安全,在操作共享變數時必須得加鎖。Put方法首先定位到Segment,然後在Segment裡進行插入操作。插入操作需要經歷兩個步驟,第一步判斷是否需要對Segment裡的HashEntry陣列進行擴容,第二步定位新增元素的位置然後放在HashEntry數組裡。
是否需要擴容。在插入元素前會先判斷Segment裡的HashEntry陣列是否超過容量(threshold),如果超過閥值,陣列進行擴容。值得一提的是,Segment的擴容判斷比HashMap更恰當,因為HashMap是在插入元素後判斷元素是否已經到達容量的,如果到達了就進行擴容,但是很有可能擴容之後沒有新元素插入,這時HashMap就進行了一次無效的擴容。
如何擴容。擴容的時候首先會建立一個兩倍於原容量的陣列,然後將原數組裡的元素進行再hash後插入到新的數組裡。為了高效ConcurrentHashMap不會對整個容器進行擴容,而只對某個segment進行擴容。
size操作
如果我們要統計整個ConcurrentHashMap裡元素的大小,就必須統計所有Segment裡元素的大小後求和。Segment裡的全域性變數count是一個volatile變數,那麼在多執行緒場景下,我們是不是直接把所有Segment的count相加就可以得到整個ConcurrentHashMap大小了呢?不是的,雖然相加時可以獲取每個Segment的count的最新值,但是拿到之後可能累加前使用的count發生了變化,那麼統計結果就不準了。所以最安全的做法,是在統計size的時候把所有Segment的put,remove和clean方法全部鎖住,但是這種做法顯然非常低效。
因為在累加count操作過程中,之前累加過的count發生變化的機率非常小,所以ConcurrentHashMap的做法是先嚐試2次通過不鎖住Segment的方式來統計各個Segment大小,如果統計的過程中,容器的count發生了變化,則再採用加鎖的方式來統計所有Segment的大小。
那麼ConcurrentHashMap是如何判斷在統計的時候容器是否發生了變化呢?使用modCount變數,在put , remove和clean方法裡操作元素前都會將變數modCount進行加1,那麼在統計size前後比較modCount是否發生變化,從而得知容器的大小是否發生變化。