
從輸入URL到頁面展示的詳細過程
其實從輸入URL到頁面展示在我們眼前所經歷的過程其實還是非常複雜的,牽扯到的知識點也是非常的龐雜。其中很多知識都會有專門的學科去研究,所以這裡只是簡單地概括一下大致流程:
- 1、輸入網址
- 2、DNS解析
- 3、建立tcp連線
- 4、客戶端傳送HTPP請求
- 5、伺服器處理請求
- 6、伺服器響應請求
- 7、瀏覽器展示HTML
- 8、瀏覽器傳送請求獲取其他在HTML中的資源。
下面是轉載自https://www.cnblogs.com/xianyulaodi/p/6547807.html的一篇博文,講解的感覺還不錯。
1、輸入地址
當我們開始在瀏覽器中輸入網址的時候,瀏覽器其實就已經在智慧的匹配可能得 url 了,他會從歷史記錄,書籤等地方,找到已經輸入的字串可能對應的 url,然後給出智慧提示,讓你可以補全url地址。對於 google的chrome 的瀏覽器,他甚至會直接從快取中把網頁展示出來,就是說,你還沒有按下 enter,頁面就出來了。
2、瀏覽器查詢域名的 IP 地址
1、請求一旦發起,瀏覽器首先要做的事情就是解析這個域名,一般來說,瀏覽器會首先檢視本地硬碟的 hosts 檔案,看看其中有沒有和這個域名對應的規則,如果有的話就直接使用 hosts 檔案裡面的 ip 地址。
2、如果在本地的 hosts 檔案沒有能夠找到對應的 ip 地址,瀏覽器會發出一個 DNS請求到本地DNS伺服器 。本地DNS伺服器一般都是你的網路接入伺服器商提供,比如中國電信,中國移動。
3、查詢你輸入的網址的DNS請求到達本地DNS伺服器之後,本地DNS伺服器會首先查詢它的快取記錄,如果快取中有此條記錄,就可以直接返回結果,此過程是遞迴的方式進行查詢。如果沒有,本地DNS伺服器還要向DNS根伺服器進行查詢。
4、根DNS伺服器沒有記錄具體的域名和IP地址的對應關係,而是告訴本地DNS伺服器,你可以到域伺服器上去繼續查詢,並給出域伺服器的地址。這種過程是迭代的過程。
5、本地DNS伺服器繼續向域伺服器發出請求,在這個例子中,請求的物件是.com域伺服器。.com域伺服器收到請求之後,也不會直接返回域名和IP地址的對應關係,而是告訴本地DNS伺服器,你的域名的解析伺服器的地址。
6、最後,本地DNS伺服器向域名的解析伺服器發出請求,這時就能收到一個域名和IP地址對應關係,本地DNS伺服器不僅要把IP地址返回給使用者電腦,還要把這個對應關係儲存在快取中,以備下次別的使用者查詢時,可以直接返回結果,加快網路訪問。
下面這張圖很完美的解釋了這一過程:

知識擴充套件:
1)什麼是DNS?
DNS(Domain Name System,域名系統),因特網上作為域名和IP地址相互對映的一個分散式資料庫,能夠使使用者更方便的訪問網際網路,而不用去記住能夠被機器直接讀取的IP數串。通過主機名,最終得到該主機名對應的IP地址的過程叫做域名解析(或主機名解析)。
通俗的講,我們更習慣於記住一個網站的名字,比如www.baidu.com,而不是記住它的ip地址,比如:167.23.10.2。而計算機更擅長記住網站的ip地址,而不是像www.baidu.com等連結。因為,DNS就相當於一個電話本,比如你要找www.baidu.com這個域名,那我翻一翻我的電話本,我就知道,哦,它的電話(ip)是167.23.10.2。
2)DNS查詢的兩種方式:遞迴查詢和迭代查詢
1、遞迴解析
當局部DNS伺服器自己不能回答客戶機的DNS查詢時,它就需要向其他DNS伺服器進行查詢。此時有兩種方式,如圖所示的是遞迴方式。區域性DNS伺服器自己負責向其他DNS伺服器進行查詢,一般是先向該域名的根域伺服器查詢,再由根域名伺服器一級級向下查詢。最後得到的查詢結果返回給區域性DNS伺服器,再由區域性DNS伺服器返回給客戶端。
2、迭代解析
當局部DNS伺服器自己不能回答客戶機的DNS查詢時,也可以通過迭代查詢的方式進行解析,如圖所示。區域性DNS伺服器不是自己向其他DNS伺服器進行查詢,而是把能解析該域名的其他DNS伺服器的IP地址返回給客戶端DNS程式,客戶端DNS程式再繼續向這些DNS伺服器進行查詢,直到得到查詢結果為止。也就是說,迭代解析只是幫你找到相關的伺服器而已,而不會幫你去查。比如說:baidu.com的伺服器ip地址在192.168.4.5這裡,你自己去查吧,本人比較忙,只能幫你到這裡了。
3)DNS域名稱空間的組織方式
我們在前面有說到根DNS伺服器,域DNS伺服器,這些都是DNS域名稱空間的組織方式。按其功能名稱空間中用來描述 DNS 域名稱的五個類別的介紹詳見下表中,以及與每個名稱型別的示例
 (盜圖)
(盜圖)
4)DNS負載均衡
當一個網站有足夠多的使用者的時候,假如每次請求的資源都位於同一臺機器上面,那麼這臺機器隨時可能會蹦掉。處理辦法就是用DNS負載均衡技術,它的原理是在DNS伺服器中為同一個主機名配置多個IP地址,在應答DNS查詢時,DNS伺服器對每個查詢將以DNS檔案中主機記錄的IP地址按順序返回不同的解析結果,將客戶端的訪問引導到不同的機器上去,使得不同的客戶端訪問不同的伺服器,從而達到負載均衡的目的。例如可以根據每臺機器的負載量,該機器離使用者地理位置的距離等等。
3、瀏覽器向 web 伺服器傳送一個 HTTP 請求
拿到域名對應的IP地址之後,瀏覽器會以一個隨機埠(1024<埠<65535)向伺服器的WEB程式(常用的有httpd,nginx等)80埠發起TCP的連線請求。這個連線請求到達伺服器端後(這中間通過各種路由裝置,區域網內除外),進入到網絡卡,然後是進入到核心的TCP/IP協議棧(用於識別該連線請求,解封包,一層一層的剝開),還有可能要經過Netfilter防火牆(屬於核心的模組)的過濾,最終到達WEB程式,最終建立了TCP/IP的連線。
TCP連線如圖所示:

建立了TCP連線之後,發起一個http請求。一個典型的 http request header 一般需要包括請求的方法,例如 GET 或者 POST 等,不常用的還有 PUT 和 DELETE 、HEAD、OPTION以及 TRACE 方法,一般的瀏覽器只能發起 GET 或者 POST 請求。
客戶端向伺服器發起http請求的時候,會有一些請求資訊,請求資訊包含三個部分:
| 請求方法URI協議/版本
| 請求頭(Request Header)
| 請求正文:
下面是一個完整的HTTP請求例子:

GET/sample.jspHTTP/1.1 Accept:image/gif.image/jpeg,*/* Accept-Language:zh-cn Connection:Keep-Alive Host:localhost User-Agent:Mozila/4.0(compatible;MSIE5.01;Window NT5.0) Accept-Encoding:gzip,deflate
username=jinqiao&password=1234
注意:最後一個請求頭之後是一個空行,傳送回車符和換行符,通知伺服器以下不再有請求頭。
(1)請求的第一行是“方法URL議/版本”:GET/sample.jsp HTTP/1.1
(2)請求頭(Request Header)
請求頭包含許多有關的客戶端環境和請求正文的有用資訊。例如,請求頭可以宣告瀏覽器所用的語言,請求正文的長度等。
Accept:image/gif.image/jpeg.*/* Accept-Language:zh-cn Connection:Keep-Alive Host:localhost User-Agent:Mozila/4.0(compatible:MSIE5.01:Windows NT5.0) Accept-Encoding:gzip,deflate.
(3)請求正文
請求頭和請求正文之間是一個空行,這個行非常重要,它表示請求頭已經結束,接下來的是請求正文。請求正文中可以包含客戶提交的查詢字串資訊:
username=jinqiao&password=1234
知識擴充套件:
1)TCP三次握手
第一次握手:客戶端A將標誌位SYN置為1,隨機產生一個值為seq=J(J的取值範圍為=1234567)的資料包到伺服器,客戶端A進入SYN_SENT狀態,等待服務端B確認;
第二次握手:服務端B收到資料包後由標誌位SYN=1知道客戶端A請求建立連線,服務端B將標誌位SYN和ACK都置為1,ack=J+1,隨機產生一個值seq=K,並將該資料包傳送給客戶端A以確認連線請求,服務端B進入SYN_RCVD狀態。
第三次握手:客戶端A收到確認後,檢查ack是否為J+1,ACK是否為1,如果正確則將標誌位ACK置為1,ack=K+1,並將該資料包傳送給服務端B,服務端B檢查ack是否為K+1,ACK是否為1,如果正確則連線建立成功,客戶端A和服務端B進入ESTABLISHED狀態,完成三次握手,隨後客戶端A與服務端B之間可以開始傳輸資料了。
如圖所示:

2)為什需要三次握手?
《計算機網路》第四版中講“三次握手”的目的是“為了防止已失效的連線請求報文段突然又傳送到了服務端,因而產生錯誤”
書中的例子是這樣的,“已失效的連線請求報文段”的產生在這樣一種情況下:client發出的第一個連線請求報文段並沒有丟失,而是在某個網路結點長時間的滯留了,以致延誤到連線釋放以後的某個時間才到達server。本來這是一個早已失效的報文段。但server收到此失效的連線請求報文段後,就誤認為是client再次發出的一個新的連線請求。於是就向client發出確認報文段,同意建立連線。
假設不採用“三次握手”,那麼只要server發出確認,新的連線就建立了。由於現在client並沒有發出建立連線的請求,因此不會理睬server的確認,也不會向server傳送資料。但server卻以為新的運輸連線已經建立,並一直等待client發來資料。這樣,server的很多資源就白白浪費掉了。採用“三次握手”的辦法可以防止上述現象發生。例如剛才那種情況,client不會向server的確認發出確認。server由於收不到確認,就知道client並沒有要求建立連線。”。主要目的防止server端一直等待,浪費資源。
3)TCP四次揮手
第一次揮手:Client傳送一個FIN,用來關閉Client到Server的資料傳送,Client進入FIN_WAIT_1狀態。
第二次揮手:Server收到FIN後,傳送一個ACK給Client,確認序號為收到序號+1(與SYN相同,一個FIN佔用一個序號),Server進入CLOSE_WAIT狀態。
第三次揮手:Server傳送一個FIN,用來關閉Server到Client的資料傳送,Server進入LAST_ACK狀態。
第四次揮手:Client收到FIN後,Client進入TIME_WAIT狀態,接著傳送一個ACK給Server,確認序號為收到序號+1,Server進入CLOSED狀態,完成四次揮手。

4)為什麼建立連線是三次握手,而關閉連線卻是四次揮手呢?
這是因為服務端在LISTEN狀態下,收到建立連線請求的SYN報文後,把ACK和SYN放在一個報文裡傳送給客戶端。而關閉連線時,當收到對方的FIN報文時,僅僅表示對方不再發送資料了但是還能接收資料,己方也未必全部資料都發送給對方了,所以己方可以立即close,也可以傳送一些資料給對方後,再發送FIN報文給對方來表示同意現在關閉連線,因此,己方ACK和FIN一般都會分開發送。
4、伺服器的永久重定向響應
伺服器給瀏覽器響應一個301永久重定向響應,這樣瀏覽器就會訪問“http://www.google.com/” 而非“http://google.com/”。
為什麼伺服器一定要重定向而不是直接傳送使用者想看的網頁內容呢?其中一個原因跟搜尋引擎排名有關。如果一個頁面有兩個地址,就像http://www.yy.com/和http://yy.com/,搜尋引擎會認為它們是兩個網站,結果造成每個搜尋連結都減少從而降低排名。而搜尋引擎知道301永久重定向是什麼意思,這樣就會把訪問帶www的和不帶www的地址歸到同一個網站排名下。還有就是用不同的地址會造成快取友好性變差,當一個頁面有好幾個名字時,它可能會在快取裡出現好幾次。
擴充套件知識
1)301和302的區別。
301和302狀態碼都表示重定向,就是說瀏覽器在拿到伺服器返回的這個狀態碼後會自動跳轉到一個新的URL地址,這個地址可以從響應的Location首部中獲取(使用者看到的效果就是他輸入的地址A瞬間變成了另一個地址B)——這是它們的共同點。
他們的不同在於。301表示舊地址A的資源已經被永久地移除了(這個資源不可訪問了),搜尋引擎在抓取新內容的同時也將舊的網址交換為重定向之後的網址;
302表示舊地址A的資源還在(仍然可以訪問),這個重定向只是臨時地從舊地址A跳轉到地址B,搜尋引擎會抓取新的內容而儲存舊的網址。 SEO302好於301
2)重定向原因:
(1)網站調整(如改變網頁目錄結構);(2)網頁被移到一個新地址;(3)網頁副檔名改變(如應用需要把.php改成.Html或.shtml)。 這種情況下,如果不做重定向,則使用者收藏夾或搜尋引擎資料庫中舊地址只能讓訪問客戶得到一個404頁面錯誤資訊,訪問流量白白喪失;再者某些註冊了多個域名的網站,也需要通過重定向讓訪問這些域名的使用者自動跳轉到主站點等。3)什麼時候進行301或者302跳轉呢?
當一個網站或者網頁24—48小時內臨時移動到一個新的位置,這時候就要進行302跳轉,而使用301跳轉的場景就是之前的網站因為某種原因需要移除掉,然後要到新的地址訪問,是永久性的。清晰明確而言:使用301跳轉的大概場景如下:1、域名到期不想續費(或者發現了更適合網站的域名),想換個域名。2、在搜尋引擎的搜尋結果中出現了不帶www的域名,而帶www的域名卻沒有收錄,這個時候可以用301重定向來告訴搜尋引擎我們目標的域名是哪一個。3、空間伺服器不穩定,換空間的時候。5、瀏覽器跟蹤重定向地址
現在瀏覽器知道了 "http://www.google.com/"才是要訪問的正確地址,所以它會發送另一個http請求。這裡沒有啥好說的
6、伺服器處理請求
經過前面的重重步驟,我們終於將我們的http請求傳送到了伺服器這裡,其實前面的重定向已經是到達伺服器了,那麼,伺服器是如何處理我們的請求的呢?
後端從在固定的埠接收到TCP報文開始,它會對TCP連線進行處理,對HTTP協議進行解析,並按照報文格式進一步封裝成HTTP Request物件,供上層使用。
一些大一點的網站會將你的請求到反向代理伺服器中,因為當網站訪問量非常大,網站越來越慢,一臺伺服器已經不夠用了。於是將同一個應用部署在多臺伺服器上,將大量使用者的請求分配給多臺機器處理。此時,客戶端不是直接通過HTTP協議訪問某網站應用伺服器,而是先請求到Nginx,Nginx再請求應用伺服器,然後將結果返回給客戶端,這裡Nginx的作用是反向代理伺服器。同時也帶來了一個好處,其中一臺伺服器萬一掛了,只要還有其他伺服器正常執行,就不會影響使用者使用。
如圖所示:

通過Nginx的反向代理,我們到達了web伺服器,服務端指令碼處理我們的請求,訪問我們的資料庫,獲取需要獲取的內容等等,當然,這個過程涉及很多後端指令碼的複雜操作。由於對這一塊不熟,所以這一塊只能介紹這麼多了。
擴充套件閱讀:
1)什麼是反向代理?
客戶端本來可以直接通過HTTP協議訪問某網站應用伺服器,網站管理員可以在中間加上一個Nginx,客戶端請求Nginx,Nginx請求應用伺服器,然後將結果返回給客戶端,此時Nginx就是反向代理伺服器。

7、伺服器返回一個 HTTP 響應
經過前面的6個步驟,伺服器收到了我們的請求,也處理我們的請求,到這一步,它會把它的處理結果返回,也就是返回一個HTPP響應。
HTTP響應與HTTP請求相似,HTTP響應也由3個部分構成,分別是:
l 狀態行
l 響應頭(Response Header)
l 響應正文
HTTP/1.1 200 OK Date: Sat, 31 Dec 2005 23:59:59 GMT Content-Type: text/html;charset=ISO-8859-1 Content-Length: 122 <html> <head> <title>http</title> </head> <body> <!-- body goes here --> </body> </html>
狀態行:
狀態行由協議版本、數字形式的狀態程式碼、及相應的狀態描述,各元素之間以空格分隔。
格式: HTTP-Version Status-Code Reason-Phrase CRLF
例如: HTTP/1.1 200 OK \r\n
-- 協議版本:是用http1.0還是其他版本
-- 狀態描述:狀態描述給出了關於狀態程式碼的簡短的文字描述。比如狀態程式碼為200時的描述為 ok
-- 狀態程式碼:狀態程式碼由三位數字組成,第一個數字定義了響應的類別,且有五種可能取值。如下
1xx:資訊性狀態碼,表示伺服器已接收了客戶端請求,客戶端可繼續傳送請求。
100 Continue
101 Switching Protocols
2xx:成功狀態碼,表示伺服器已成功接收到請求並進行處理。
200 OK 表示客戶端請求成功
204 No Content 成功,但不返回任何實體的主體部分
206 Partial Content 成功執行了一個範圍(Range)請求
3xx:重定向狀態碼,表示伺服器要求客戶端重定向。
301 Moved Permanently 永久性重定向,響應報文的Location首部應該有該資源的新URL
302 Found 臨時性重定向,響應報文的Location首部給出的URL用來臨時定位資源
303 See Other 請求的資源存在著另一個URI,客戶端應使用GET方法定向獲取請求的資源
304 Not Modified 伺服器內容沒有更新,可以直接讀取瀏覽器快取
307 Temporary Redirect 臨時重定向。與302 Found含義一樣。302禁止POST變換為GET,但實際使用時並不一定,307則更多瀏覽器可能會遵循這一標準,但也依賴於瀏覽器具體實現
4xx:客戶端錯誤狀態碼,表示客戶端的請求有非法內容。
400 Bad Request 表示客戶端請求有語法錯誤,不能被伺服器所理解
401 Unauthonzed 表示請求未經授權,該狀態程式碼必須與 WWW-Authenticate 報頭域一起使用
403 Forbidden 表示伺服器收到請求,但是拒絕提供服務,通常會在響應正文中給出不提供服務的原因
404 Not Found 請求的資源不存在,例如,輸入了錯誤的URL
5xx:伺服器錯誤狀態碼,表示伺服器未能正常處理客戶端的請求而出現意外錯誤。
500 Internel Server Error 表示伺服器發生不可預期的錯誤,導致無法完成客戶端的請求
503 Service Unavailable 表示伺服器當前不能夠處理客戶端的請求,在一段時間之後,伺服器可能會恢復正常
響應頭:
響應頭部:由關鍵字/值對組成,每行一對,關鍵字和值用英文冒號":"分隔,典型的響應頭有:
響應正文
包含著我們需要的一些具體資訊,比如cookie,html,image,後端返回的請求資料等等。這裡需要注意,響應正文和響應頭之間有一行空格,表示響應頭的資訊到空格為止,下圖是fiddler抓到的請求正文,紅色框中的:響應正文:
8、瀏覽器顯示 HTML
在瀏覽器沒有完整接受全部HTML文件時,它就已經開始顯示這個頁面了,瀏覽器是如何把頁面呈現在螢幕上的呢?不同瀏覽器可能解析的過程不太一樣,這裡我們只介紹webkit的渲染過程,下圖對應的就是WebKit渲染的過程,這個過程包括:
解析html以構建dom樹 -> 構建render樹 -> 佈局render樹 -> 繪製render樹
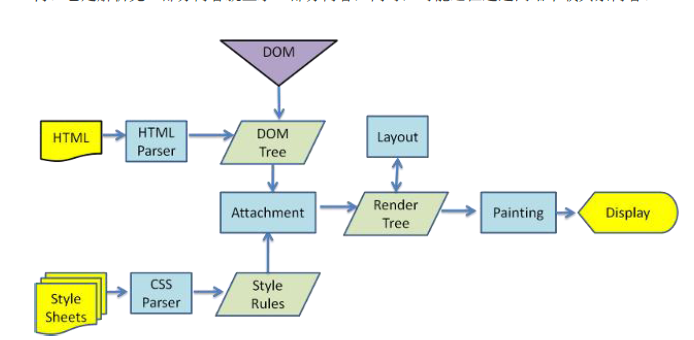
瀏覽器在解析html檔案時,會”自上而下“載入,並在載入過程中進行解析渲染。在解析過程中,如果遇到請求外部資源時,如圖片、外鏈的CSS、iconfont等,請求過程是非同步的,並不會影響html文件進行載入。
解析過程中,瀏覽器首先會解析HTML檔案構建DOM樹,然後解析CSS檔案構建渲染樹,等到渲染樹構建完成後,瀏覽器開始佈局渲染樹並將其繪製到螢幕上。這個過程比較複雜,涉及到兩個概念: reflow(迴流)和repain(重繪)。
DOM節點中的各個元素都是以盒模型的形式存在,這些都需要瀏覽器去計算其位置和大小等,這個過程稱為relow;當盒模型的位置,大小以及其他屬性,如顏色,字型,等確定下來之後,瀏覽器便開始繪製內容,這個過程稱為repain。
頁面在首次載入時必然會經歷reflow和repain。reflow和repain過程是非常消耗效能的,尤其是在移動裝置上,它會破壞使用者體驗,有時會造成頁面卡頓。所以我們應該儘可能少的減少reflow和repain。

當文件載入過程中遇到js檔案,html文件會掛起渲染(載入解析渲染同步)的執行緒,不僅要等待文件中js檔案載入完畢,還要等待解析執行完畢,才可以恢復html文件的渲染執行緒。因為JS有可能會修改DOM,最為經典的document.write,這意味著,在JS執行完成前,後續所有資源的下載可能是沒有必要的,這是js阻塞後續資源下載的根本原因。所以我明平時的程式碼中,js是放在html文件末尾的。
JS的解析是由瀏覽器中的JS解析引擎完成的,比如谷歌的是V8。JS是單執行緒執行,也就是說,在同一個時間內只能做一件事,所有的任務都需要排隊,前一個任務結束,後一個任務才能開始。但是又存在某些任務比較耗時,如IO讀寫等,所以需要一種機制可以先執行排在後面的任務,這就是:同步任務(synchronous)和非同步任務(asynchronous)。
JS的執行機制就可以看做是一個主執行緒加上一個任務佇列(task queue)。同步任務就是放在主執行緒上執行的任務,非同步任務是放在任務佇列中的任務。所有的同步任務在主執行緒上執行,形成一個執行棧;非同步任務有了執行結果就會在任務佇列中放置一個事件;指令碼執行時先依次執行執行棧,然後會從任務佇列裡提取事件,執行任務佇列中的任務,這個過程是不斷重複的,所以又叫做事件迴圈(Event loop)。具體的過程可以看我這篇文章:點選這裡
9、瀏覽器傳送請求獲取嵌入在 HTML 中的資源(如圖片、音訊、視訊、CSS、JS等等)
其實這個步驟可以並列在步驟8中,在瀏覽器顯示HTML時,它會注意到需要獲取其他地址內容的標籤。這時,瀏覽器會發送一個獲取請求來重新獲得這些檔案。比如我要獲取外圖片,CSS,JS檔案等,類似於下面的連結:
圖片:http://static.ak.fbcdn.net/rsrc.php/z12E0/hash/8q2anwu7.gif
CSS式樣表:http://static.ak.fbcdn.net/rsrc.php/z448Z/hash/2plh8s4n.css
JavaScript 檔案:http://static.ak.fbcdn.net/rsrc.php/zEMOA/hash/c8yzb6ub.js
這些地址都要經歷一個和HTML讀取類似的過程。所以瀏覽器會在DNS中查詢這些域名,傳送請求,重定向等等...
不像動態頁面,靜態檔案會允許瀏覽器對其進行快取。有的檔案可能會不需要與伺服器通訊,而從快取中直接讀取,或者可以放到CDN中