
基於VGG19的識別中國人、韓國人、日本人分類器
這是本學期機器學習課程的專案。通過這個專案瞭解了不少東西,希望通過部落格記錄下整個專案過程。
國外有一個網站上有一個非常有趣的測試,他們在街頭收集了一共18名中國人、韓國人、日本人的照片,放在網站上,讓人去識別。博主自己嘗試過一次,18個對了7個,38%的正確率,跟猜的概率並沒有相差太多,恰好剛在學習深度學習一些模型,瞭解到可以通過深度的學習模型構建分類器去識別。在一時衝動之下,有了這個專案。廢話不多說,直接開始博主完成整個專案的過程。
- 資料集構造
網上沒有找到現成的資料集,甚至沒有找到單純包含中國人或者日本人或者韓國人的資料庫。遂決定自己構造資料集,能夠想到的辦法就只能從當地的官方網站(譬如政府、學校等等)收集圖片作為我們的訓練集。在一番折騰之後,得到具體資料集情況如下:
| 名稱 | 資料來源 | 樣本數目 |
|---|---|---|
| 中國人 | 政府網站、明星、老師、學生 | 483 |
| 日本人 | 政府網站、明星、老師、學生 | 407 |
| 韓國人 | 408 |
ps:這裡我們韓國人的資料存在問題,因為直接來源於Google,真實性不如收集到的中國人和日本人,很可能原始標記就存在問題。
- 人臉檢測
人臉檢測,我們主要使用的是Haar分類器,這個分類器原理在這篇博文中介紹的很仔細。主要的步驟包括:1)使用Haar-like特徵做檢測;2)使用積分圖(Integral Image)對Haar-like特徵求值進行加速;3)使用AdaBoost演算法訓練區分人臉和非人臉的強分類器;4)使用篩選式級聯把強分類器級聯到一起,提高準確率。本文直接在python使用opencv提供的介面,順利完成了人臉檢測。效果如下:
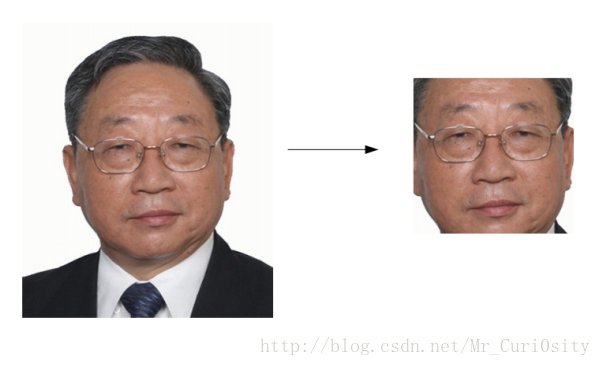
學長說這樣的人臉檢測會丟失很多有用的資訊,要在人臉檢測之後做一些人臉補全的工作,目前還不知道怎麼弄,先碼著,等期末結束之後有空了再來折騰一下。
具體做法的程式碼參照這篇博文,修改了一下。
- 資料集增強
因為收集到的資料非常有限,三種人種一起才1290張。考慮到深度學習在數量足夠多的時候才有更好的效果,我們這裡計劃改變資料的亮度、飽和度、對比度、銳度、旋轉一個小角度做一個數據增強。下面使我們做資料集增強的方法:
飽和度
im_1 = ImageEnhance.Color(img).enhance(random_factor)- 1
這裡直接呼叫了ImageEnhance模組的Color類,其中random_factor是一個隨機變數。random_factor=1的時候為原圖,random_factor越大飽和度越大。
亮度
im_2 = ImageEnhance.Brightness(img).enhance(random_factor)- 1
這裡直接呼叫了ImageEnhance模組的Brightness類,其中random_factor是一個隨機變數。random_factor=1的時候為原圖,random_factor越大飽和度越大。
對比度
im_3 = ImageEnhance.Contrast(img).enhance(random_factor)- 1
這裡直接呼叫了ImageEnhance模組的Contrast類,其中random_factor是一個隨機變數。random_factor=1 的時候為原圖,random_factor越大飽和度越大。
銳度
im_4 = ImageEnhance.Sharpness(img).enhance(random_factor)- 1
這裡直接呼叫了ImageEnhance模組的Sharpness類,其中random_factor是一個隨機變數。random_factor=1 的時候為原圖,random_factor越大飽和度越大。

這裡主要是參考了這邊博文。
旋轉角度
改變旋轉角度同樣也可以做資料增強。
下圖是博主兩次做數的兩次資料增強。左邊是沒有任何經驗,完全隨機的做出來的資料集增強,右邊是學長指導之後做出來的增強結果,把這兩個資料集在博主訓練得到最好的分類器上面跑,左邊只有86%左右的正確率,右邊卻達到了94%左右的正確率。 
左邊主要存在的問題是,資料增強的幅度過大,導致圖片有點失真(跟正常相機拍出來的相差太大);隨機調整的角度也過大;這兩種方式得到的照片跟實際相差太大,沒有很大的實際應用價值。Ps:學長還說,在實際工作中,新增隨機噪聲得到的資料集沒有價值。。。目前還沒有弄明白為啥,先碼著。
下面是我得到右邊資料集的程式碼:
def randomRotation(image):
"""
對影象進行隨機任意角度(0~360度)旋轉
:param mode 鄰近插值,雙線性插值,雙三次B樣條插值(default)
:param image PIL的影象image
:return: 旋轉轉之後的影象
"""
random_angle = np.random.randint(-15, 15)
return image.rotate(random_angle)
def randomColor(image):
"""
對影象進行顏色抖動
:param image: PIL的影象image
:return: 有顏色色差的影象image
"""
random_factor = np.random.randint(8, 12) / 10. # 隨機因子
color_image = ImageEnhance.Color(image).enhance(random_factor) # 調整影象的飽和度
random_factor = np.random.randint(8, 12) / 10. # 隨機因子
brightness_image = ImageEnhance.Brightness(color_image).enhance(random_factor) # 調整影象的亮度
random_factor = np.random.randint(8, 12) / 10. # 隨機因1子
contrast_image = ImageEnhance.Contrast(brightness_image).enhance(random_factor) # 調整影象對比度
random_factor = np.random.randint(8, 10) / 10. # 隨機因子
return ImageEnhance.Sharpness(contrast_image).enhance(random_factor) # 調整影象銳度- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
-
構造分類器
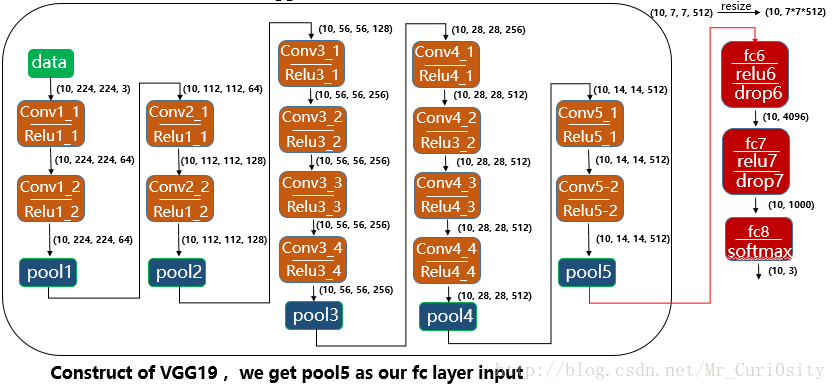
博主在深度學習課程中的老師講到:在我們想利用深度模型做圖片分類器的時候,可以考慮將圖片先在ImageNet上面訓練好的模型跑,擷取某一層的特徵圖構建全連線的神經網構建分類器。基於這個思想,博主使用VGG19,擷取最後一個pooling層,然後構造一個全連線的神經網路作為分類器。結構如下圖所示:
因為VGG對輸入圖片有要求,在放入VGG模型之前首先對圖片進行了如下處理:- 將RGB轉換成BGR
- 將圖片resize成為224*224*3
- 圖片中每一個pixel減去在ImageNet上訓練的平均值(出於改善模型結果的考慮)
在Batch size = 16、#training = 1082、#validation = 16、 #test = 200、 Dropout = 1時訓練上述分類器得到正確率隨著訓練步數的變化如下: 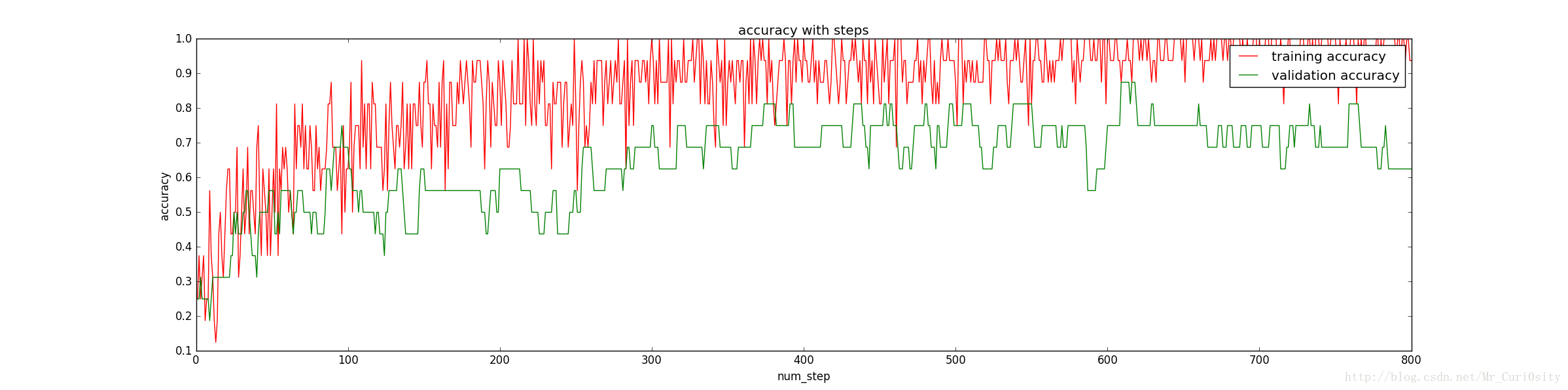
發現訓練集上面的正確率接近100%,然而驗證集上面的正確率卻58%,顯然出現了過擬合,為了避免過擬合,提高泛化能力,我們隊對引數進行調整。
這裡影象波動很大,因為我們的batch_size只有16,若batch_size大一些,影象會更加平滑一點,但是總體局勢還是能夠反映的。
- 引數調整
首先嚐試了不同的drop out,得到在drop_out = 0.5 的時候結果比較好,正確率為70%;然後做了,上述左邊的資料集增強,得到了79%的正確率,一次比較大的提升;在嘗試了權重衰減係數,得到在weight_decay = 0.0003的時候有81%的正確率。最後嘗試了Batch Normalization,在沒有drop out和weight decay情況下,得到了86%的正確率。隨後在學長的意見上改變了資料增強的方式,得到一個最終94%的正確率。 - 轉載:http://blog.csdn.net/mr_curi0sity/article/details/72927941