
基於spark SQL之上的檢索與排序對比效能測試
關於spark的效能,基於YDB的對比,做了一個測試,保留備用。
一、YDB與spark sql在排序上的效能對比測試
在排序上,YDB具有絕對優勢,無論是全表,還是基於任意條件組合過濾,基本秒殺spark任何格式。
測試結果(時間單位為秒)
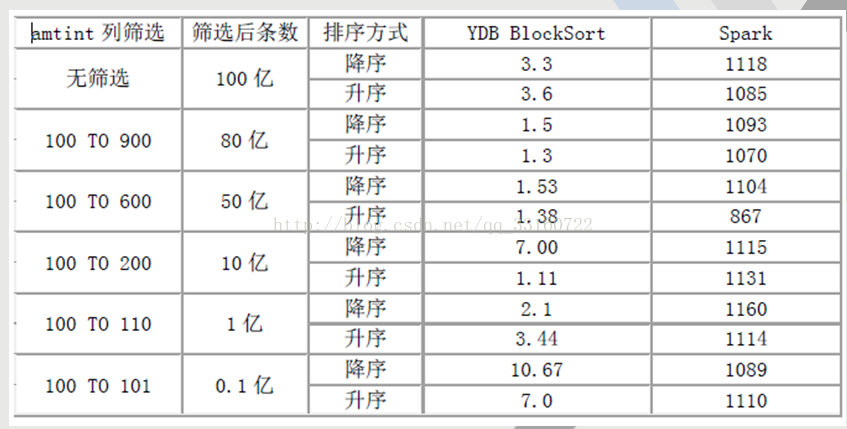
詳細測試地址:http://blog.csdn.NET/qq_33160722/article/details/54447022
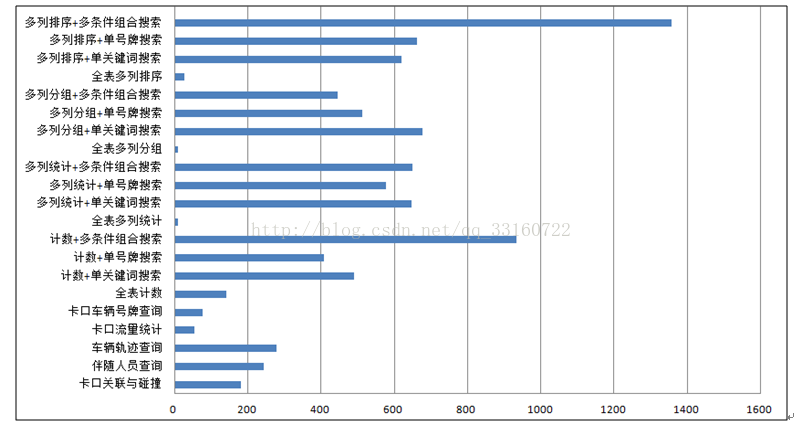
300億條資料的排序 演示視訊http://blog.csdn.Net/qq_33160722/article/details/54834896二、與Spark txt在檢索上的效能對比測試。
註釋:備忘。下圖的這塊,其實沒什麼特別的,只不過由於YDB本身索引的特性,不想spark那樣暴力,才會導致在掃描上的效能遠高於spark,效能高百倍不足為奇。
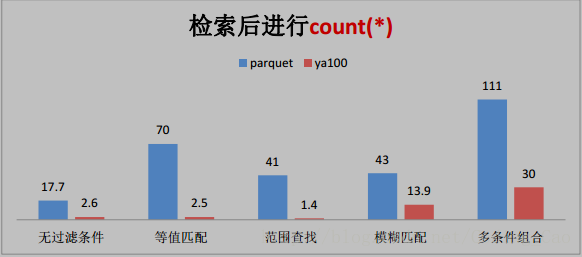
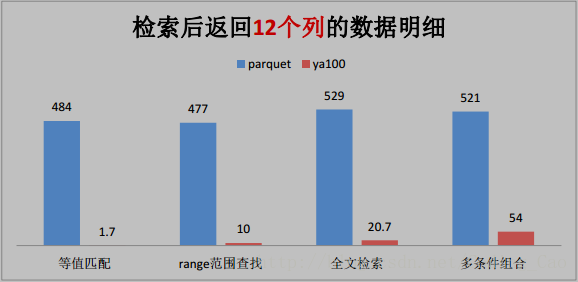
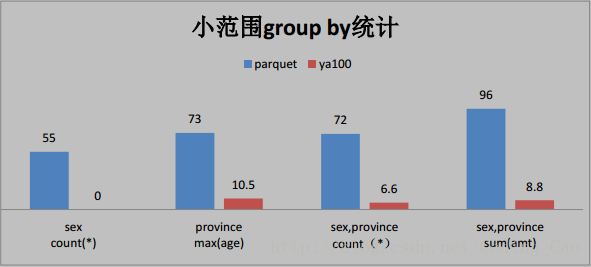
三、這些是與 Parquet 格式對比(單位為秒)
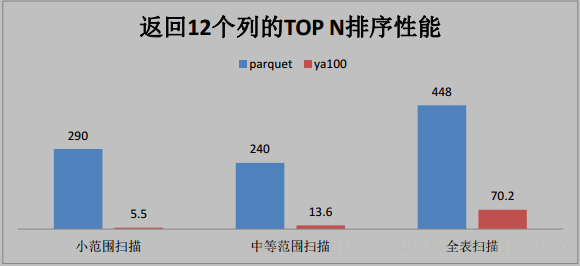
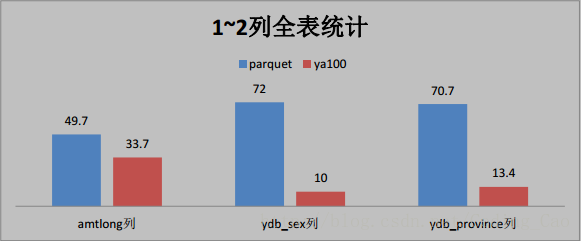
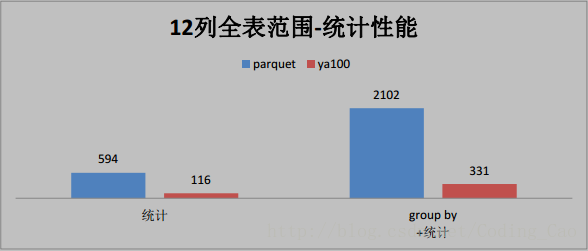
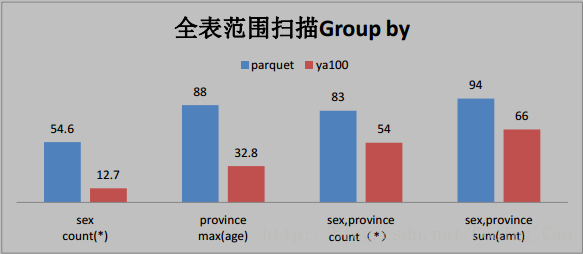
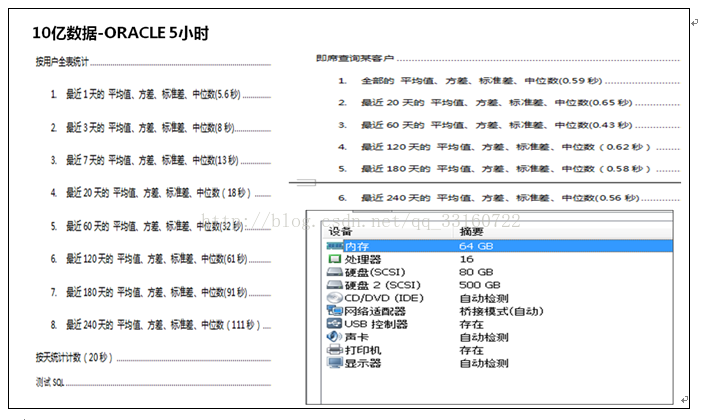
四、與ORACLE效能對比
跟傳統資料庫的對比,已經沒啥意義,oracle不適合大資料,任意一個大資料工具都遠超oracle 效能。
|
|
五、稽查布控場景效能測試

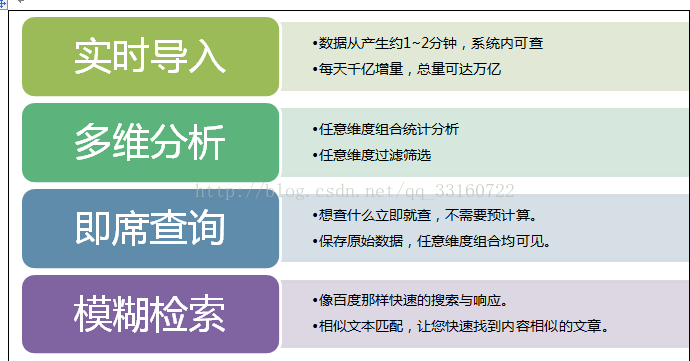
六、YDB是怎麼樣讓spark加速的?
基於Hadoop分散式架構下的實時的、多維的、互動式的查詢、統計、分析引擎,具有萬億資料規模下的秒級效能表現,並具備企業級的穩定可靠表現。
YDB是一個細粒度的索引,精確粒度的索引。資料即時匯入,索引即時生成,通過索引高效定位到相關資料。YDB與Spark
哪些使用者適合使用YDB?
1.傳統關係型資料,已經無法容納更多的資料,查詢效率嚴重受到影響的使用者。
2.目前在使用SOLR、ES做全文檢索,覺得solr與ES提供的分析功能太少,無法完成複雜的業務邏輯,或者資料量變多後SOLR與ES變得不穩定,在掉片與均衡中不斷惡性迴圈,不能自動恢復服務,運維人員需經常半夜起來重啟叢集的情況。
3.基於對海量資料的分析,但是苦於現有的離線計算平臺的速度和響應時間無滿足業務要求的使用者。
4.需要對使用者畫像行為類資料做多維定向分析的使用者。
5.
6.當你需要在大資料集上面進行快速的,互動式的查詢時。
7.當你需要進行資料分析,而不只是簡單的鍵值對儲存時。
8.當你想要分析實時產生的資料時。