
網際網路公司校招Java面試題總結及答案——微店、去哪兒、蘑菇街
阿新 • • 發佈:2019-01-02
2.servlet和filter的區別。filter你在哪些地方用到過。
servlet是一種執行伺服器端的java應用程式,具有獨立於平臺和協議的特性,並且可以動態的生成web頁面,它工作在客戶端請求與伺服器響應的中間層。
1) 客戶端傳送請求至伺服器端;
2) 伺服器將請求資訊傳送至 Servlet;
3) Servlet 生成響應內容並將其傳給伺服器。響應內容動態生成,通常取決於客戶端的請求;
4) 伺服器將響應返回給客戶端。
在 Web 應用程式中,一個 Servlet 在一個時刻可能被多個使用者同時訪問。這時 Web 容器將為每個使用者建立一個執行緒來執行 Servlet。
filter是一個可以複用的代碼片段,可以用來轉換HTTP請求、響應和頭資訊。Filter不像Servlet,它不能產生一個請求或者響應,它只是修改對某一資源的請求,或者修改從某一的響應。只要你在web.xml檔案配置好要攔截的客戶端請求,它都會幫你攔截到請求,此時你就可以對請求或響應(Request、Response)統一設定編碼,簡化操作;同時還可進行邏輯判斷,如使用者是否已經登陸、有沒有許可權訪問該頁面等等工作。 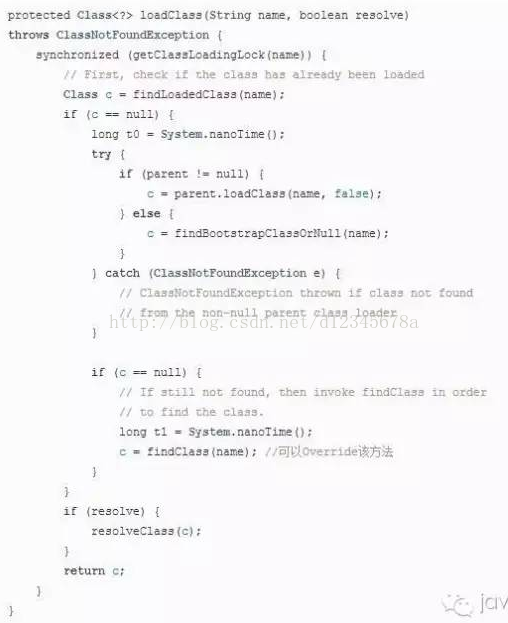
1.雙親委派模型 Java虛擬機器類載入過程是把Class類檔案載入到記憶體,並對Class檔案中的資料進行校驗、轉換解析和初始化,最終形成可以被虛擬機器直接使用的java型別的過程。 在載入階段,java虛擬機器需要完成以下3件事: a.通過一個類的全限定名來獲取定義此類的二進位制位元組流。 b.將定義類的二進位制位元組流所代表的靜態儲存結構轉換為方法區的執行時資料結構。 c.在java堆中生成一個代表該類的java.lang.Class物件,作為方法區資料的訪問入口。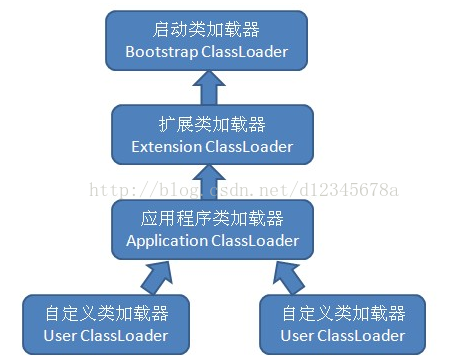
(1).BootStrap ClassLoader:啟動類載入器,負責載入存放在%JAVA_HOME%\lib目錄中的,或者通被-Xbootclasspath引數所指定的路 徑中的,並且被java虛擬機器識別的(僅按照檔名識別,如rt.jar,名字不符合的類庫,即使放在指定路徑中也不會被載入)類庫到虛擬機器的記憶體中,啟 動類載入器無法被java程式直接引用。 (2).Extension ClassLoader:擴充套件類載入器,由sun.misc.Launcher$ExtClassLoader實現,負責加 載%JAVA_HOME%\lib\ext目錄中的,或者被java.ext.dirs系統變數所指定的路徑中的所有類庫,開發者可以直接使用擴充套件類載入 器。 (3).Application ClassLoader:應用程式類載入器,由sun.misc.Launcher$AppClassLoader實現,負責載入使用者類路徑 classpath上所指定的類庫,是類載入器ClassLoader中的getSystemClassLoader()方法的返回值,開發者可以直接使 用應用程式類載入器,如果程式中沒有自定義過類載入器,該載入器就是程式中預設的類載入器。 java虛擬機器規範推薦開發者使用雙親委派模式(ParentsDelegation Model)進行類載入,其載入過程如下: (1).如果一個類載入器收到了類載入請求,它首先不會自己去嘗試載入這個類,而是把類載入請求委派給父類載入器去完成。 (2).每一層的類載入器都把類載入請求委派給父類載入器,直到所有的類載入請求都應該傳遞給頂層的啟動類載入器。 (3).如果頂層的啟動類載入器無法完成載入請求,子類載入器嘗試去載入,如果連最初發起類載入請求的類載入器也無法完成載入請求時,將會丟擲ClassNotFoundException,而不再呼叫其子類載入器去進行類載入。 具體參看《深入理解Java虛擬機器》第七章 虛擬機器類載入機制。 2.單源最短路演算法簡述 Dijkstra演算法是解單源最短路徑問題的貪心演算法。 演算法流程: (a) 初始化:用起點v到該頂點w的直接邊(弧)初始化最短路徑,否則設為∞; (b) 從未求得最短路徑的終點中選擇路徑長度最小的終點u:即求得v到u的最短路徑; (c) 修改最短路徑:計算u的鄰接點的最短路徑,若(v,…,u)+(u,w)<(v,…,w),則以(v,…,u,w)代替。 (d) 重複(b)-(c),直到求得v到其餘所有頂點的最短路徑。 演算法基於:如果存在一條從i到j的最短路徑(Vi.....Vk,Vj),Vk是Vj前面的一頂點。那麼(Vi...Vk)也必定是從i到k的最短路徑。 dist[j]=min{dist[j],dist[i]+matrix[i][j]} 單源最短路除了dijkstra演算法之外,還有一種常用的演算法叫做SPFA(shortest path faster algorithm)演算法,不同於dijkstra的複雜度為o(n^2),SPFA演算法的平均複雜度為o(kE),E為邊數,且k通常不超過2。用bfs實現。 SPFA的核心思想如下: 最開始起點入隊,然後考慮和起點相鄰的點,更新dis陣列,並將這些點入隊; 當佇列不為空時,每次取隊首一個點,對這個點相鄰的點進行鬆弛操作,即比較原先的dis和經過新加入的點的優化後的dis,如果鬆弛成功,且被鬆弛的點不在佇列中,則將其加入佇列,重複上述動作。 SPFA可以用來判斷負環,我們開一個cnt陣列記錄每個點入隊的次數,如果次數超過n說明出現負環。 3..有若干個點,給出哪些點是相連的,求第一個點到最後一個點是否聯通,並求出經過幾個點(實際還是最短路問題) 4.Mybatis和hibernate有什麼區別 Hibernate和Mybatis都是orm物件關係對映框架,都是用於將資料持久化的框架技術。 Hiberante較深度的封裝了jdbc,對開發者寫sql的能力要求的不是那麼的高,我們只要通過hql語句操作物件即可完成對資料持久化的操作了。 另外hibernate可移植性好,如一個專案開始使用的是mysql資料庫,但是隨著業務的發展,現mysql資料庫已經無法滿足當前的繡球了,現在決定使用Oracle資料庫,雖然sql標準定義的資料庫間的sql語句差距不大,但是不同的資料庫sql標準還是有差距的,那麼我們手動修改起來會存在很大的困難,使用hibernate只需改變一下資料庫方言即可搞定。用hibernate框架,資料庫的移植變的非常方便。 但是hibernate也存在著諸多的不足,比如在實際開發過程中會生成很多不必要的sql語句耗費程式資源,優化起來也不是很方便,且對儲存過程支援的也不夠強大。但是針對於hibernate它也提供了一些優化策略,比如說懶載入、快取、策略模式等都是針對於它的優化方案。 Mybatis 也是對jdbc的封裝,但是封裝的沒有hibernate那麼深,我們可以再配置檔案中寫sql語句,可以根據需求定製sql語句,資料優化起來較hibernate容易很多。 Mybatis要求程式設計師寫sql的能力要相對使用hibernate的開發人員要高的多,且可移植性也不是很好。 涉及到大資料的系統使用Mybatis比較好,因為優化較方便。涉及的資料量不是很大且對優化沒有那麼高,可以使用hibernate。 兩者相同點
- 建Filter處理類;
- web.xml檔案中配置Filter。
- 啟動類載入器( Bootstrap ClassLoader)啟動類載入器無法被 java 程式設計師直接引用, 這個類載入器負責把存放在<JAVA_HOME>\lib目錄中的, 或者被-Xbootclasspath引數指定路徑中的, 並且是被虛擬機器識別的類庫載入到虛擬機器記憶體中.
- 擴充套件類載入器(Extension ClassLoader)負責載入在<JAVA_HOME>\lib\ext目錄中的, 或者被java.ext.dirs系統變數所指定的路徑中的所有類庫。
- 應用程式類載入器( Application ClassLoader )這個類載入器是ClassLoader 中的 getSystemClassLoader()方法的返回值, 一般稱其為系統類載入器, 它負責載入使用者類路徑( ClassPath )上所指定的類庫
- 一個是啟動類載入器( Bootstrap ClassLoader ), 這個類載入使用 C++ 語言實現, 是虛擬機器自身的一部分;
- 另一種是其他所有的類載入器, 他們由 java 語言實現, 獨立於虛擬機器之外, 並且全部繼承自java.lang.ClassLoader
- 載入 把 class 檔案的二進位制位元組流載入到 jvm 裡面
- 驗證 確保 class 檔案的位元組流包含的資訊符合當前 jvm 的要求 有檔案格式驗證, 元資料驗證, 位元組碼驗證, 符號引用驗證等
- 準備 正式為類變數分配記憶體並設定類變數初始值的階段, 初始化為各資料型別的零值
- 解析 把常量值內的符號引用替換為直接引用的過程
- 初始化 執行類構造器<clinit>()方法
- 使用 根據相應的業務邏輯程式碼使用該類
- 解除安裝 類從方法區移除
1.雙親委派模型 Java虛擬機器類載入過程是把Class類檔案載入到記憶體,並對Class檔案中的資料進行校驗、轉換解析和初始化,最終形成可以被虛擬機器直接使用的java型別的過程。 在載入階段,java虛擬機器需要完成以下3件事: a.通過一個類的全限定名來獲取定義此類的二進位制位元組流。 b.將定義類的二進位制位元組流所代表的靜態儲存結構轉換為方法區的執行時資料結構。 c.在java堆中生成一個代表該類的java.lang.Class物件,作為方法區資料的訪問入口。
(1).BootStrap ClassLoader:啟動類載入器,負責載入存放在%JAVA_HOME%\lib目錄中的,或者通被-Xbootclasspath引數所指定的路 徑中的,並且被java虛擬機器識別的(僅按照檔名識別,如rt.jar,名字不符合的類庫,即使放在指定路徑中也不會被載入)類庫到虛擬機器的記憶體中,啟 動類載入器無法被java程式直接引用。 (2).Extension ClassLoader:擴充套件類載入器,由sun.misc.Launcher$ExtClassLoader實現,負責加 載%JAVA_HOME%\lib\ext目錄中的,或者被java.ext.dirs系統變數所指定的路徑中的所有類庫,開發者可以直接使用擴充套件類載入 器。 (3).Application ClassLoader:應用程式類載入器,由sun.misc.Launcher$AppClassLoader實現,負責載入使用者類路徑 classpath上所指定的類庫,是類載入器ClassLoader中的getSystemClassLoader()方法的返回值,開發者可以直接使 用應用程式類載入器,如果程式中沒有自定義過類載入器,該載入器就是程式中預設的類載入器。 java虛擬機器規範推薦開發者使用雙親委派模式(ParentsDelegation Model)進行類載入,其載入過程如下: (1).如果一個類載入器收到了類載入請求,它首先不會自己去嘗試載入這個類,而是把類載入請求委派給父類載入器去完成。 (2).每一層的類載入器都把類載入請求委派給父類載入器,直到所有的類載入請求都應該傳遞給頂層的啟動類載入器。 (3).如果頂層的啟動類載入器無法完成載入請求,子類載入器嘗試去載入,如果連最初發起類載入請求的類載入器也無法完成載入請求時,將會丟擲ClassNotFoundException,而不再呼叫其子類載入器去進行類載入。 具體參看《深入理解Java虛擬機器》第七章 虛擬機器類載入機制。 2.單源最短路演算法簡述 Dijkstra演算法是解單源最短路徑問題的貪心演算法。 演算法流程: (a) 初始化:用起點v到該頂點w的直接邊(弧)初始化最短路徑,否則設為∞; (b) 從未求得最短路徑的終點中選擇路徑長度最小的終點u:即求得v到u的最短路徑; (c) 修改最短路徑:計算u的鄰接點的最短路徑,若(v,…,u)+(u,w)<(v,…,w),則以(v,…,u,w)代替。 (d) 重複(b)-(c),直到求得v到其餘所有頂點的最短路徑。 演算法基於:如果存在一條從i到j的最短路徑(Vi.....Vk,Vj),Vk是Vj前面的一頂點。那麼(Vi...Vk)也必定是從i到k的最短路徑。 dist[j]=min{dist[j],dist[i]+matrix[i][j]} 單源最短路除了dijkstra演算法之外,還有一種常用的演算法叫做SPFA(shortest path faster algorithm)演算法,不同於dijkstra的複雜度為o(n^2),SPFA演算法的平均複雜度為o(kE),E為邊數,且k通常不超過2。用bfs實現。 SPFA的核心思想如下: 最開始起點入隊,然後考慮和起點相鄰的點,更新dis陣列,並將這些點入隊; 當佇列不為空時,每次取隊首一個點,對這個點相鄰的點進行鬆弛操作,即比較原先的dis和經過新加入的點的優化後的dis,如果鬆弛成功,且被鬆弛的點不在佇列中,則將其加入佇列,重複上述動作。 SPFA可以用來判斷負環,我們開一個cnt陣列記錄每個點入隊的次數,如果次數超過n說明出現負環。 3..有若干個點,給出哪些點是相連的,求第一個點到最後一個點是否聯通,並求出經過幾個點(實際還是最短路問題) 4.Mybatis和hibernate有什麼區別 Hibernate和Mybatis都是orm物件關係對映框架,都是用於將資料持久化的框架技術。 Hiberante較深度的封裝了jdbc,對開發者寫sql的能力要求的不是那麼的高,我們只要通過hql語句操作物件即可完成對資料持久化的操作了。 另外hibernate可移植性好,如一個專案開始使用的是mysql資料庫,但是隨著業務的發展,現mysql資料庫已經無法滿足當前的繡球了,現在決定使用Oracle資料庫,雖然sql標準定義的資料庫間的sql語句差距不大,但是不同的資料庫sql標準還是有差距的,那麼我們手動修改起來會存在很大的困難,使用hibernate只需改變一下資料庫方言即可搞定。用hibernate框架,資料庫的移植變的非常方便。 但是hibernate也存在著諸多的不足,比如在實際開發過程中會生成很多不必要的sql語句耗費程式資源,優化起來也不是很方便,且對儲存過程支援的也不夠強大。但是針對於hibernate它也提供了一些優化策略,比如說懶載入、快取、策略模式等都是針對於它的優化方案。 Mybatis 也是對jdbc的封裝,但是封裝的沒有hibernate那麼深,我們可以再配置檔案中寫sql語句,可以根據需求定製sql語句,資料優化起來較hibernate容易很多。 Mybatis要求程式設計師寫sql的能力要相對使用hibernate的開發人員要高的多,且可移植性也不是很好。 涉及到大資料的系統使用Mybatis比較好,因為優化較方便。涉及的資料量不是很大且對優化沒有那麼高,可以使用hibernate。 兩者相同點
- Hibernate與MyBatis都可以是通過SessionFactoryBuider由XML配置檔案生成SessionFactory,然後由SessionFactory 生成Session,最後由Session來開啟執行事務和SQL語句。其中SessionFactoryBuider,SessionFactory,Session的生命週期都是差不多的。
- Hibernate和MyBatis都支援JDBC和JTA事務處理。
- MyBatis可以進行更為細緻的SQL優化,可以減少查詢欄位。
- MyBatis容易掌握,而Hibernate門檻較高。
- Hibernate的DAO層開發比MyBatis簡單,Mybatis需要維護SQL和結果對映。
- Hibernate對物件的維護和快取要比MyBatis好,對增刪改查的物件的維護要方便。
- Hibernate資料庫移植性很好,MyBatis的資料庫移植性不好,不同的資料庫需要寫不同SQL。
- Hibernate有更好的二級快取機制,可以使用第三方快取。MyBatis本身提供的快取機制不佳。
- Hibernate功能強大,資料庫無關性好,O/R對映能力強,如果你對Hibernate相當精通,而且對Hibernate進行了適當的封裝,那麼你的專案整個持久層程式碼會相當簡單,需要寫的程式碼很少,開發速度很快,非常爽。
- Hibernate的缺點就是學習門檻不低,要精通門檻更高,而且怎麼設計O/R對映,在效能和物件模型之間如何權衡取得平衡,以及怎樣用好Hibernate方面需要你的經驗和能力都很強才行。
- iBATIS入門簡單,即學即用,提供了資料庫查詢的自動物件繫結功能,而且延續了很好的SQL使用經驗,對於沒有那麼高的物件模型要求的專案來說,相當完美。
- iBATIS的缺點就是框架還是比較簡陋,功能尚有缺失,雖然簡化了資料繫結程式碼,但是整個底層資料庫查詢實際還是要自己寫的,工作量也比較大,而且不太容易適應快速資料庫修改。