
推薦系統3種主要演算法學習筆記與總結
以下均為個人總結,“我認為”居多,歡迎指正,給菜鳥一個學習的機會。
音樂推薦與普通商品推薦的區別
1、消費歌代價小; 免費
2、物品重用率高;喜歡的歌會重複聽,褲子未必會重複買
3、上下文相關性更大;和使用者當前心情、工作環境相關更大
推薦系統的指標
precision
recall
新穎度
驚喜度
轉化率
覆蓋率
各自的關注點分別是:
precision: 推薦的100件商品中有多少是使用者確實喜歡的?
recall:使用者所有喜歡的商品(假設:100件)中你推薦了出來了多少件?
新穎度:你推薦的是熱門的還是長尾的?
驚喜度:使用者有多喜歡你推薦的?
轉化率:你推薦給使用者的,有多少轉化為了購買(商品)或者收藏(音樂)?
覆蓋率:倉庫裡的那100件商品你全都推薦過麼?能否保證將每個商品至少推薦給了一個使用者?
協同過濾 Collaborative Filtering:
1、常用的有
User-based Collaborative Filtering:
從跟目標使用者相似的其他使用者中找幾個最相似的,把它們喜歡的商品推薦給目標使用者
Item-based Collaborative Filtering:
把跟目標使用者喜歡的商品相似的商品中找幾個最相似的,把它們推薦給目標使用者
2、如何衡量相似?
對User-based來說,使用者A和使用者B喜歡的東西如果經常重疊,認為他們相似;
對Item-based來說,物品1和物品2經常被同一個使用者喜歡,認為它們相似;
3、如何表徵相似?
算距離。
1)怎麼算?
(歐式距離、pearson距離、古本系數、餘弦距離等)。
2)怎麼存?
用一個相似矩陣W儲存,其中 wi,j 表示i和j的相似度。因而,在User-based中,wi,j 表示的是使用者i和使用者j的相似程度;
Item-based中,存的是物品相似程度。
4、如何處理熱門商品(哈利波特問題)
為啥要處理:否則的話,會給每個買書的人推薦新華字典,因為夠熱門,上過小學都買過。
通常在計算相似度時,會考慮熱門商品的問題
1)在User-based中,
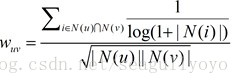
其實主要是求了個倒數,喜歡i的人越多,得分越低。也即,i越熱門,越不能表徵使用者是否相似。反之,越不熱門,越能表徵。
例如:兩個人同時喜歡《資治通鑑》,或者同時喜歡一套6K多的珍藏版《指環王》,基本定性了~
2)在Item-based中(哈利波特問題),
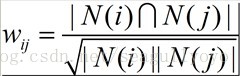
假設j是熱門商品,分母很大,從而降低了熱門對相似判斷的影響。闊是如果有些物品如果實在太熱門了,即便這樣懲罰了還是顯得不夠。
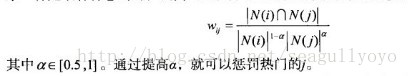
這樣居然往往就顯著提升了覆蓋率和新穎性(降低流行度一般即能提高新穎度)。
5、如何計算使用者 u 喜歡物品 i 的程度
1、User-based:
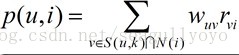
其中,S(u,k):與u興趣相近的使用者們 N(i):喜歡商品i的使用者們W (u,v):u,v相似度r (v, i):v喜歡i的程度
2、Item-based:
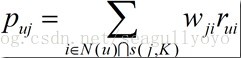
其中,N(u):使用者u喜歡的商品們s(j, k):與商品j相似的商品們W(j, j):j,i相似度 r(u, i):u喜歡i的程度
例子:

6、為何現實應用中用Item-based的多:
1)通常user數遠大於item數,維護一個龐大的使用者相似度矩陣,不論計算或儲存都是問題;
2)物品之間的相似度相對穩定,隨時間變化的程度小;
3)Item-based可以對推薦的商品提供推薦理由:比如借上面那個例子,給你推薦《演算法導論》,是因為你喜歡過《C++ Primer》和《程式設計之美》。
下邊是一些更加細碎零散的東西,更多是志記和加深記憶的作用。
1、使用者活躍度對物品相似度的影響
有paper提出一個成為IUF的觀點,該觀點認為:活躍的使用者對物品相似度的貢獻應該小於不活躍的使用者。why呢? 因為如果你是一個來亞馬遜進貨的商人,你買了4000雙鞋,闊能你會稍微挑一挑,但大概率意義上來說,你買它們並非完全出於喜歡。因此你的這次購買記錄理論上來說,不應該用來衡量商品相似度。至少,weight應該調低一點。
很有道理的樣子,如何做呢。類似上邊對user-based熱門商品的處理,調低一點的做法如下
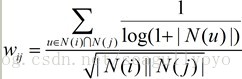
簡單解釋:如果使用者u同時買了或者說喜歡了i、j,但是u買了海量的商品(商人),或者喜歡了海量的商品(濫情),那麼他對物品i、j是否相似的觀點,我們儘量忽略。
2、物品相似度的歸一化
有人(KARYPIS)發現,如果將item-based的相似度矩陣按最大值(列)歸一化,可以提高推薦的準確率。項亮老師表示,不僅如此,還能提高推薦的覆蓋率和多樣性。
簡單解釋:如果A類商品之間計算出來的相似度普遍在0.6左右,而B類商品之間的相似度普遍在0.5左右。那麼此時如果一個使用者喜歡了5個A類商品,5個B類商品,用ItemCF給他推薦,全部都是A類,因為0.6 > 0.5,如果各自歸一化一下,相似度都是1,再推薦的話可能A、B類摻雜。從而提高了多樣性。項老師又定性地表示 - -!:熱門商品類之間的相似性比較大,不歸一化的話推薦熱門的可能性比較大,所以歸一化也提高了覆蓋率。
3、UserCF和ItemCF的比較
簡而言之,UserCF的推薦結果著重於反映和使用者興趣相似的小群體的熱點,而ItemCF的推薦結果著重於維繫使用者的歷史興趣。
換句話說,UserCF更偏向社會化,ItemCF更偏向個性化。
因此,如果是新聞網站,社會化色彩比較濃,UserCF更靠譜;其他的大部分,如電商、音樂、電影、圖書,更具象的說Amazone、豆瓣、Netflix中,ItemCF更靠譜。
如果從技術角度考量,新聞每天更新,維護一個不停更新的相似度矩陣。。 ORZ;而對商品更新相對沒有那麼迅速的其他網站,ItemCF就比較OK了。附一張優缺點對比圖:

隱語義模型:
對商品進行分類,給一個使用者推薦前,首先得到他的興趣分類,再從他的興趣分類裡邊挑選他可能喜歡的商品推薦給他。
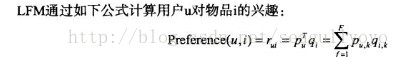
其中,p(u, k)度量了使用者u的興趣和第k個隱類的關係,q(i, k)度量了第k個隱類和物品i之間的關係。這兩個引數都可以通過機器學習的方法訓練得到。
隱語義模型 LFM 和 基於鄰域的方法(UserCF、ItemCF)的區別:
1、理論基礎
LFM有比較好的理論基礎,它是一種學習方法,通過優化一個設定的指標建立最優的模型;基於鄰域的方法是基於統計的方法,沒有學習過程。
2、空間複雜度
UserCF的空間複雜度是 O(M ^ 2), ItemCF的空間複雜度是O(N ^ 2),而LFM的空間複雜度為O(K * (M + N))。
當M、N 很大的時候,LFM能節省不少空間。
3、時間複雜度
假設M個使用者、N個物品、K條使用者對物品的行為記錄。UserCF計算使用者相似性矩陣需要 O(N * (K / N) ^ 2);
ItemCF計算物品相似性矩陣需要O(M * (K / M) ^ 2);
LFM 如果用F個隱類,迭代S次, 時間複雜度為O(K * F *S)。一般略高於前兩者,也相差不大。
4、線上實時推薦
LFM的缺點。不能線上實時推薦,ItemCF維護一個Item相似矩陣,來一個新物品就實時更新一下。而LFM在給使用者生成推薦列表時,需要計算使用者對所有物品的興趣權重,然後排名,返回權重最大的N個物品。那麼如果物品較多,時間複雜度O(M * N * F)。
5、推薦解釋
ItemCF是3者中唯一能夠提供合理性解釋的。
基於圖的模型
將使用者行為表示成二分圖模型後,推薦的任務即建模為:度量與使用者u沒有路徑直連的物品i,推薦相關性最大的物品。
因而轉化為圖論的問題。
度量圖中任意兩點間相關性,主要看3個點:
1、兩點間有多少條路徑?
2、路徑有多長?
3、途徑過 出度很大的點麼?
於此對應的,一對相關性很大的點,具備3個特徵
1、很多路相連;
2、路徑都很短;
3、沒有途徑過出度很大的點。
在此基礎上,有paper提出了一種“基於隨機遊走的PersonalRank”演算法:
假設要給使用者u進行個性化推薦,就以V(u)為起點開始走,到達一個點就停下來以概率p決定是否繼續走
1)繼續走,看V(cur) 點的出度,均勻分佈地決定走哪條路離開;
2)不走,退回到V(u)重新開始走。
這樣,經過多次隨機遊走後,每個點被訪問到的概率會收斂到一個數。這個數就是最終該節點被推薦的權重。
這個過程寫成公式如下:
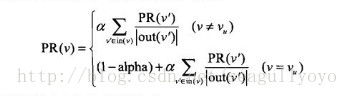
缺點:迭代,慢。
轉化為矩陣的形式,令M為使用者物品二分圖的轉移概率矩陣,即
M(v, v') = 1 / |out(v)|, 迭代公式因此可以轉化為:
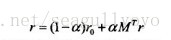
解得:
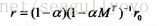
從稀疏矩陣的快速求逆入手,提速。