
Python3 爬蟲編寫報錯及解決方法整理
將爬蟲執行過程中遇到的錯誤進行整理,方便後來查詢
執行環境:Python3.6+Pydev
編碼錯誤
執行時候報錯:UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\u2022’ in position 16707: illegal multibyte
分析:看描述是編碼方面的問題;
解決方法:專案—>屬性
將編碼改成utf-8
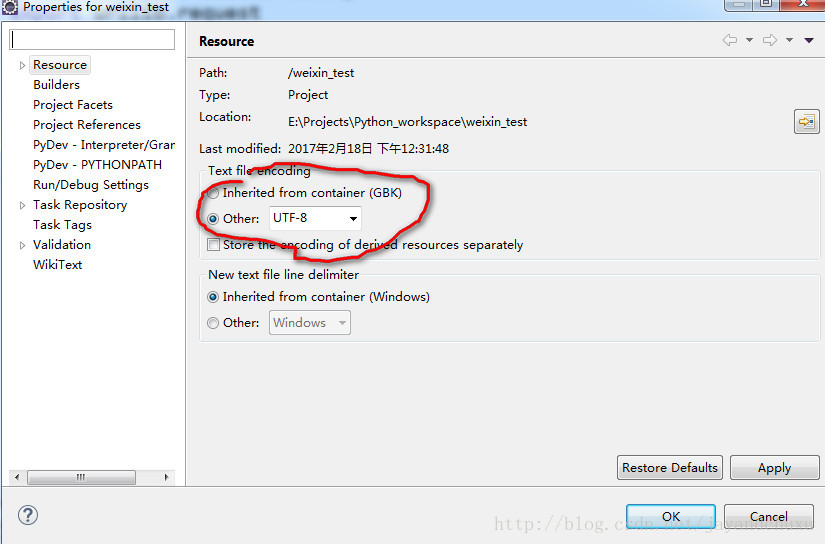
執行程式,問題解決。
再爬小說網站的時候,報錯:UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xc1 in position 183: invalid start byte
分析:還是編碼方面的問題,這次和上一個不同的是utf-8看來不行;
解決方法:改成GBK試一試
html = urllib.request.urlopen(req).read().decode('GBK')剛看到一篇文章,對這些編碼問題分析解決進行了歸納,很多方法值得借鑑
UnicodeEncodeError: ‘gbk’
其中講了一個比較好的方法
將原先的utf-8的字元轉換為Unicode的時候,其實更加安全的做法,也可以將:
titleUni = titleHtml.decode(“UTF-8”);替換為:
titleUni = titleHtml.decode(“UTF-8”, ‘ignore’); 這樣可以實現,即使對於那些,相對來說是無關緊要的一些特殊字元,也可以成功編碼,避免編碼出錯,提高程式的健壯性。
unicode中的‘\xa0’字元在轉換成gbk編碼時會出現問題,gbk無法轉換’\xa0’字元。
所以,在轉換的時候必需進行一些前置動作:
string.replace(u'\xa0', u' ') 將’\xa0‘替換成u’ ‘空格。
關於urllib
1、在獲取網易公開課_視訊連結 的爬蟲程式碼裡,看到這樣的寫法
key = urllib.parse.quote(keyword) 知乎上的解釋是:
urllib 庫中的 quote? 在 Python2.x 中的用法是:
urllib.quote(text)Python3.x 中是
urllib.parse.quote(text)按照標準, URL 只允許一部分 ASCII 字元(數字字母和部分符號),其他的字元(如漢字)是不符合 URL 標準的。所以 URL 中使用其他字元就需要進行 URL 編碼。URL 中傳引數的部分(query String),格式是:name1=value1&name2=value2&name3=value3
假如你的 name 或者 value 值中有『&』或者『=』等符號,就當然會有問題。所以URL中的引數字串也需要把『&=』等符號進行編碼。URL編碼的方式是把需要編碼的字元轉化為 %xx 的形式。通常 URL 編碼是基於 UTF-8 的(當然這和瀏覽器平臺有關)。例子:比如『我』,unicode 為 0x6211, UTF-8 編碼為 0xE6 0x88 0x91,URL 編碼就是 %E6%88%91
在 JavaScript 中,提供了 encodeURI 和 encodeURIComponent 兩種方法對 URL 進行編碼;Python 的 urllib 庫中提供了 quote 和 quote_plus 兩種方法。因為是針對不同場景設計,以上四種方法編碼的範圍均不相同,比如 quote 除了 -._/09AZaz ,都會進行編碼。quote_plus 比 quote 『更進』一些,它還會編碼 /urllib.quote
使用參考:21.8.1. URL Parsing