
Nio buffer詳解
轉自:http://zachary-guo.iteye.com/blog/1457542
Buffer 類是 java.nio 的構造基礎。一個 Buffer 物件是固定數量的資料的容器,其作用是一個儲存器,或者分段運輸區,在這裡,資料可被儲存並在之後用於檢索。緩衝區可以被寫滿或釋放。對於每個非布林原始資料型別都有一個緩衝區類,即 Buffer 的子類有:ByteBuffer、CharBuffer、DoubleBuffer、FloatBuffer、IntBuffer、LongBuffer 和 ShortBuffer,是沒有 BooleanBuffer 之說的。儘管緩衝區作用於它們儲存的原始資料型別,但緩衝區十分傾向於處理位元組。非位元組緩衝區可以在後臺執行從位元組或到位元組的轉換,這取決於緩衝區是如何建立的。
◇ 緩衝區的四個屬性
所有的緩衝區都具有四個屬性來提供關於其所包含的資料元素的資訊,這四個屬性儘管簡單,但其至關重要,需熟記於心:
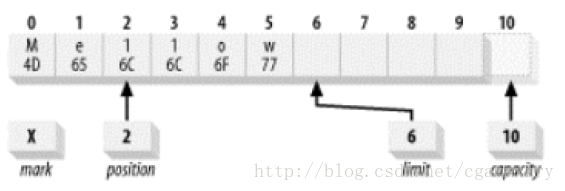
容量(Capacity):緩衝區能夠容納的資料元素的最大數量。這一容量在緩衝區建立時被設定,並且永遠不能被改變。 上界(Limit):緩衝區的第一個不能被讀或寫的元素。緩衝建立時,limit 的值等於 capacity 的值。假設 capacity = 1024,我們在程式中設定了 limit = 512,說明,Buffer 的容量為 1024,但是從 512 之後既不能讀也不能寫,因此可以理解成,Buffer 的實際可用大小為 512。 位置(Position):下一個要被讀或寫的元素的索引。位置會自動由相應的 get() 和 put() 函式更新。 這裡需要注意的是positon的位置是從0開始的。 標記(Mark):一個備忘位置。標記在設定前是未定義的(undefined)。使用場景是,假設緩衝區中有 10 個元素,position 目前的位置為 2(也就是如果get的話是第三個元素),現在只想傳送 6 - 10 之間的緩衝資料,此時我們可以 buffer.mark(buffer.position()),即把當前的 position 記入 mark 中,然後 buffer.postion(6),此時傳送給 channel 的資料就是 6 - 10 的資料。傳送完後,我們可以呼叫 buffer.reset() 使得 position = mark,因此這裡的 mark 只是用於臨時記錄一下位置用的。
請切記,在使用 Buffer 時,我們實際操作的就是這四個屬性的值。我們發現,Buffer 類並沒有包括 get() 或 put() 函式。但是,每一個Buffer 的子類都有這兩個函式,但它們所採用的引數型別,以及它們返回的資料型別,對每個子類來說都是唯一的,所以它們不能在頂層 Buffer 類中被抽象地宣告。它們的定義必須被特定型別的子類所遵從。若不加特殊說明,我們在下面討論的一些內容,都是以 ByteBuffer 為例,當然,它當然有 get() 和 put() 方法了。
◇ 相對存取和絕對存取
Java程式碼
public abstract class ByteBuffer extends Buffer implements Comparable { // This is a partial API listing public abstract byte get( ); public abstract byte get (int index); public abstract ByteBuffer put (byte b); public abstract ByteBuffer put (int index, byte b); } 來看看上面的程式碼,有不帶索引引數的方法和帶索引引數的方法。不帶索引的 get 和 put,這些呼叫執行完後,position 的值會自動前進。當然,對於 put,如果呼叫多次導致位置超出上界(注意,是 limit 而不是 capacity),則會丟擲 BufferOverflowException 異常;對於 get,如果位置不小於上界(同樣是 limit 而不是 capacity),則會丟擲 BufferUnderflowException 異常。這種不帶索引引數的方法,稱為相對存取,相對存取會自動影響緩衝區的位置屬性。帶索引引數的方法,稱為絕對存取,絕對儲存不會影響緩衝區的位置屬性,但如果你提供的索引值超出範圍(負數或不小於上界),也將丟擲 IndexOutOfBoundsException 異常。
◇ 翻轉
我們把 hello 這個串通過 put 存入一 ByteBuffer 中,如下所示:將 hello 存入 ByteBuffer 中
Java程式碼
ByteBuffer buffer = ByteBuffer.allocate(1024);
buffer.put((byte)'H').put((byte)'e').put((byte)'l').put((byte)'l').put((byte)'o');
此時,position = 5,limit = capacity = 1024。現在我們要從正確的位置從 buffer 讀資料,我們可以把 position 置為 0,那麼字串的結束位置在哪呢?這裡上界該出場了。如果把上界設定成當前 position 的位置,即 5,那麼 limit 就是結束的位置。上界屬性指明瞭緩衝區有效內容的末端。人工實現翻轉:
Java程式碼
buffer.limit(buffer.position()).position(0);
但這種從填充到釋放狀態的緩衝區翻轉是API設計者預先設計好的,他們為我們提供了一個非常便利的函式:buffer.flip()。另外,rewind() 函式與 flip() 相似,但不影響上界屬性,它只是將位置值設回 0。在進行buffer讀操作的時候,一般都會使用buffer.flip()函式。
◇ 釋放(Drain)
這裡的釋放,指的是緩衝區通過 put 填充資料後,然後被讀出的過程。上面講了,要讀資料,首先得翻轉。那麼怎麼讀呢?hasRemaining() 會在釋放緩衝區時告訴你是否已經達到緩衝區的上界:hasRemaining()函式和Remaining()函式有密切的功能,
Java程式碼
for (int i = 0; buffer.hasRemaining(); i++) {
myByteArray[i] = buffer.get();
}
很明顯,上面的程式碼,每次都要判斷元素是否到達上界。我們可以做:改變後的釋放過程
Java程式碼
int count = buffer.hasRemaining();
for (int i = 0; i < count; i++) {
myByteArray[i] = buffer.get();
}
第二段程式碼看起來很高效,但請注意,緩衝區並不是多執行緒安全的。如果你想以多執行緒同時存取特定的緩衝區,你需要在存取緩衝區之前進行同步。因此,使用第二段程式碼的前提是,你對緩衝區有專門的控制。
◇ buffer.clear()
clear() 函式將緩衝區重置為空狀態。它並不改變緩衝區中的任何資料元素,而是僅僅將 limit 設為容量的值,並把 position 設回 0。
◇ Compact(不知咋翻譯,壓縮?緊湊?)
有時候,我們只想釋放出一部分資料,即只讀取部分資料。當然,你可以把 postion 指向你要讀取的第一個資料的位置,將 limit 設定成最後一個元素的位置 + 1。但是,一旦緩衝區物件完成填充並釋放,它就可以被重新使用了。所以,緩衝區一旦被讀取出來,已經沒有使用價值了。
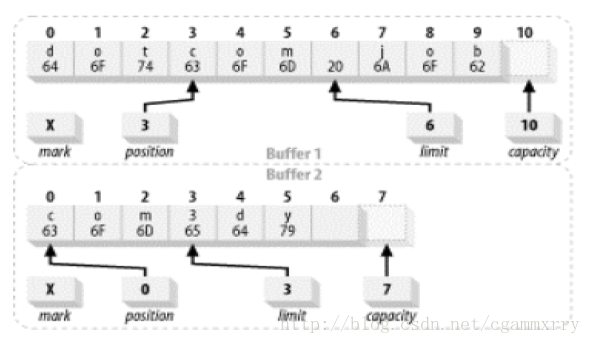
以 Mellow 為例,填充後為 Mellow,但如果我們僅僅想讀取 llow。讀取完後,緩衝區就可以重新使用了。Me 這兩個位置對於我們而言是沒用的。我們可以將 llow 複製至 0 - 3 上,Me 則被沖掉。但是 4 和 5 仍然為 o 和 w。這個事我們當然可以自行通過 get 和 put 來完成,但 api 給我們提供了一個 compact() 的函式,此函式比我們自己使用 get 和 put 要高效的多。
Compact 之前的緩衝區
buffer.compact() 會使緩衝區的狀態圖如下圖所示:

Compact 之後的緩衝區
這裡發生了幾件事:
資料元素 2 - 5 被複制到 0 - 3 位置,位置 4 和 5 不受影響,但現在正在或已經超出了當前位置,因此是“死的”。它們可以被之後的 put() 呼叫重寫。
Position 已經被設為被複制的資料元素的數目,也就是說,緩衝區現在被定位在緩衝區中最後一個“存活”元素的後一個位置。
上界屬性被設定為容量的值,因此緩衝區可以被再次填滿。
呼叫 compact() 的作用是丟棄已經釋放的資料,保留未釋放的資料,並使緩衝區對重新填充容量準備就緒。該例子中,你當然可以將 Me 之前已經讀過,即已經被釋放過。
◇ 緩衝區的比較
有時候比較兩個緩衝區所包含的資料是很有必要的。所有的緩衝區都提供了一個常規的 equals() 函式用以測試兩個緩衝區的是否相等,以及一個 compareTo() 函式用以比較緩衝區。
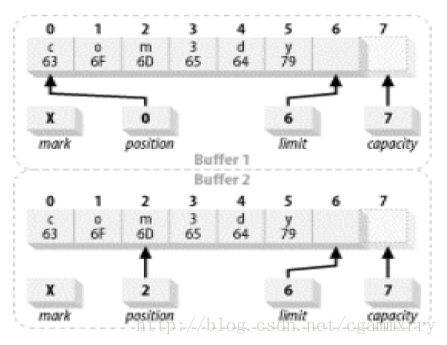
兩個緩衝區被認為相等的充要條件是:
兩個物件型別相同。包含不同資料型別的 buffer 永遠不會相等,而且buffer 絕不會等於非 buffer物件。
兩個物件都剩餘同樣數量(limit - position)的元素。Buffer 的容量不需要相同,而且緩衝區中剩餘資料的索引也不必相同。
在每個緩衝區中應被 get() 函式返回的剩餘資料元素序列([position, limit - 1] 位置對應的元素序列)必須一致。
兩個被認為是相等的緩衝區
兩個被認為是不相等的緩衝區
緩衝區也支援用 compareTo() 函式以詞典順序進行比較,當然,這是所有的緩衝區實現了 java.lang.Comparable 語義化的介面。這也意味著緩衝區陣列可以通過呼叫 java.util.Arrays.sort() 函式按照它們的內容進行排序。
與 equals() 相似,compareTo() 不允許不同物件間進行比較。但 compareTo()更為嚴格:如果你傳遞一個型別錯誤的物件,它會丟擲 ClassCastException 異常,但 equals() 只會返回 false。
比較是針對每個緩衝區你剩餘資料(從 position 到 limit)進行的,與它們在 equals() 中的方式相同,直到不相等的元素被發現或者到達緩衝區的上界。如果一個緩衝區在不相等元素髮現前已經被耗盡,較短的緩衝區被認為是小於較長的緩衝區。這裡有個順序問題:下面小於零的結果(表示式的值為 true)的含義是 buffer2 < buffer1。切記,這代表的並不是 buffer1 < buffer2。
Java程式碼
if (buffer1.compareTo(buffer2) < 0) {
// do sth, it means buffer2 < buffer1,not buffer1 < buffer2
doSth();
}
◇ 批量移動
緩衝區的設計目的就是為了能夠高效傳輸資料,一次移動一個數據元素並不高效。如你在下面的程式清單中所看到的那樣,buffer API 提供了向緩衝區你外批量移動資料元素的函式:
Java程式碼
public abstract class ByteBuffer extends Buffer implements Comparable {
public ByteBuffer get(byte[] dst);
public ByteBuffer get(byte[] dst, int offset, int length);
public final ByteBuffer put(byte[] src);
public ByteBuffer put(byte[] src, int offset, int length);
}
如你在上面的程式清單中所看到的那樣,buffer API 提供了向緩衝區內外批量移動資料元素的函式。以 get 為例,它將緩衝區中的內容複製到指定的陣列中,當然是從 position 開始咯。第二種形式使用 offset 和 length 引數來指定複製到目標陣列的子區間。這些批量移動的合成效果與前文所討論的迴圈是相同的,但是這些方法可能高效得多,因為這種緩衝區實現能夠利用原生代碼或其他的優化來移動資料。
批量移動總是具有指定的長度。也就是說,你總是要求移動固定數量的資料元素。因此,get(dist) 和 get(dist, 0, dist.length) 是等價的。
對於以下幾種情況的資料複製會發生異常:
如果你所要求的數量的資料不能被傳送,那麼不會有資料被傳遞,緩衝區的狀態保持不變,同時丟擲BufferUnderflowException異常。
如果緩衝區中的資料不夠完全填滿陣列,你會得到一個異常。這意味著如果你想將一個小型緩衝區傳入一個大型陣列,你需要明確地指定緩衝區中剩餘的資料長度。
如果緩衝區存有比陣列能容納的數量更多的資料,你可以重複利用如下程式碼進行讀取:
Java程式碼
byte[] smallArray = new Byte[10];
while (buffer.hasRemaining()) {
int length = Math.min(buffer.remaining(), smallArray.length);
buffer.get(smallArray, 0, length);
// 每取出一部分資料後,即呼叫 processData 方法,length 表示實際上取到了多少位元組的資料
processData(smallArray, length);
}
put() 的批量版本工作方式相似,只不過它是將數組裡的元素寫入 buffer 中而已,這裡不再贅述。
◇ 建立緩衝區
Buffer 的七種子類,沒有一種能夠直接例項化,它們都是抽象類,但是都包含靜態工廠方法來建立相應類的新例項。這部分討論中,將以 CharBuffer 類為例,對於其它六種主要的緩衝區類也是適用的。下面是建立一個緩衝區的關鍵函式,對所有的緩衝區類通用(要按照需要替換類名):
Java程式碼
public abstract class CharBuffer extends Buffer implements CharSequence, Comparable {
// This is a partial API listing
public static CharBuffer allocate (int capacity);
public static CharBuffer wrap (char [] array);
public static CharBuffer wrap (char [] array, int offset, int length);
public final boolean hasArray();
public final char [] array();
public final int arrayOffset();
}
新的緩衝區是由分配(allocate)或包裝(wrap)操作建立的。分配(allocate)操作建立一個緩衝區物件並分配一個私有的空間來儲存容量大小的資料元素。包裝(wrap)操作建立一個緩衝區物件但是不分配任何空間來儲存資料元素。它使用你所提供的陣列作為儲存空間來儲存緩衝區中的資料元素。demos:
Java程式碼
// 這段程式碼隱含地從堆空間中分配了一個 char 型陣列作為備份儲存器來儲存 100 個 char 變數。
CharBuffer charBuffer = CharBuffer.allocate (100);
/**
* 這段程式碼構造了一個新的緩衝區物件,但資料元素會存在於陣列中。這意味著通過呼叫 put() 函式造成的對緩
* 衝區的改動會直接影響這個陣列,而且對這個陣列的任何改動也會對這個緩衝區物件可見。
*/
char [] myArray = new char [100];
CharBuffer charbuffer = CharBuffer.wrap (myArray);
/**
* 帶有 offset 和 length 作為引數的 wrap() 函式版本則會構造一個按照你提供的 offset 和 length 參
* 數值初始化 position 和 limit 的緩衝區。
*
* 這個函式並不像你可能認為的那樣,建立了一個只佔用了一個數組子集的緩衝區。這個緩衝區可以存取這個陣列
* 的全部範圍;offset 和 length 引數只是設定了初始的狀態。呼叫 clear() 函式,然後對其進行填充,
* 直到超過 limit,這將會重寫陣列中的所有元素。
*
* slice() 函式可以提供一個只佔用備份陣列一部分的緩衝區。
*
* 下面的程式碼建立了一個 position 值為 12,limit 值為 54,容量為 myArray.length 的緩衝區。
*/
CharBuffer charbuffer = CharBuffer.wrap (myArray, 12, 42);
通過 allocate() 或者 wrap() 函式建立的緩衝區通常都是間接的。間接的緩衝區使用備份陣列,你可以通過上面列出的 api 函式獲得對這些陣列的存取權。
boolean 型函式 hasArray() 告訴你這個緩衝區是否有一個可存取的備份陣列。如果這個函式的返回 true,array() 函式會返回這個緩衝區物件所使用的陣列儲存空間的引用。如果 hasArray() 函式返回 false,不要呼叫 array() 函式或者 arrayOffset() 函式。如果你這樣做了你會得到一個 UnsupportedOperationException 異常。
如果一個緩衝區是隻讀的,它的備份陣列將會是超出 limit 的,即使一個數組物件被提供給 wrap() 函式。呼叫 array() 函式或 arrayOffset() 會丟擲一個 ReadOnlyBufferException 異常以阻止你得到存取權來修改只讀緩衝區的內容。如果你通過其它的方式獲得了對備份陣列的存取許可權,對這個陣列的修改也會直接影響到這個只讀緩衝區。
arrayOffset(),返回緩衝區資料在陣列中儲存的開始位置的偏移量(從陣列頭 0 開始計算)。如果你使用了帶有三個引數的版本的 wrap() 函式來建立一個緩衝區,對於這個緩衝區,arrayOffset() 會一直返回 0。不理解嗎?offset 和 length 只是指示了當前的 position 和 limit,是一個瞬間值,可以通過 clear() 來從 0 重新存資料,所以 arrayOffset() 返回的是 0。當然,如果你切分(slice() 函式)了由一個數組提供儲存的緩衝區,得到的緩衝區可能會有一個非 0 的陣列偏移量。
◇ 複製緩衝區
緩衝區不限於管理陣列中的外部資料,它們也能管理其他緩衝區中的外部資料。當一個管理其他緩衝器所包含的資料元素的緩衝器被建立時,這個緩衝器被稱為檢視緩衝器。
檢視儲存器總是通過呼叫已存在的儲存器例項中的函式來建立。使用已存在的儲存器例項中的工廠方法意味著檢視物件為原始儲存器的你部實現細節私有。資料元素可以直接存取,無論它們是儲存在陣列中還是以一些其他的方式,而不需經過原始緩衝區物件的 get()/put() API。如果原始緩衝區是直接緩衝區,該緩衝區(檢視緩衝區)的檢視會具有同樣的效率優勢。
繼續以 CharBuffer 為例,但同樣的操作可被用於任何基本的緩衝區型別。用於複製緩衝區的 api:
Java程式碼
public abstract class CharBuffer extends Buffer implements CharSequence, Comparable {
// This is a partial API listing
public abstract CharBuffer duplicate();
public abstract CharBuffer asReadOnlyBuffer();
public abstract CharBuffer slice();
}
● duplidate()
複製一個緩衝區會建立一個新的 Buffer 物件,但並不複製資料。原始緩衝區和副本都會操作同樣的資料元素。
duplicate() 函式建立了一個與原始緩衝區相似的新緩衝區。兩個緩衝區共享資料元素,擁有同樣的容量,但每個緩衝區擁有各自的 position、limit 和 mark 屬性。對一個緩衝區你的資料元素所做的改變會反映在另外一個緩衝區上。這一副本緩衝區具有與原始緩衝區同樣的資料檢視。如果原始的緩衝區為只讀,或者為直接緩衝區,新的緩衝區將繼承這些屬性。duplicate() 複製緩衝區:
Java程式碼
CharBuffer buffer = CharBuffer.allocate(8);
buffer.position(3).limit(6).mark().position (5);
CharBuffer dupeBuffer = buffer.duplicate();
buffer.clear();
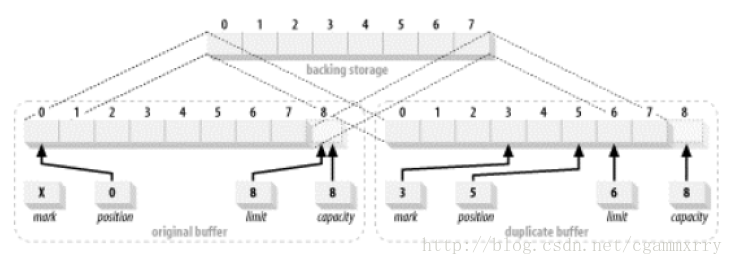
複製一個緩衝區
● asReadOnlyBuffer()
asReadOnlyBuffer() 函式來生成一個只讀的緩衝區檢視。這與duplicate() 相同,除了這個新的緩衝區不允許使用 put(),並且其 isReadOnly() 函式將會返回 true。
如果一個只讀的緩衝區與一個可寫的緩衝區共享資料,或者有包裝好的備份陣列,那麼對這個可寫的緩衝區或直接對這個陣列的改變將反映在所有關聯的緩衝區上,包括只讀緩衝區。
● slice()
分割緩衝區與複製相似,但 slice() 建立一個從原始緩衝區的當前 position 開始的新緩衝區,並且其容量是原始緩衝區的剩餘元素數量(limit - position)。這個新緩衝區與原始緩衝區共享一段資料元素子序列。分割出來的緩衝區也會繼承只讀和直接屬性。slice() 分割緩衝區:
Java程式碼
CharBuffer buffer = CharBuffer.allocate(8);
buffer.position(3).limit(5);
CharBuffer sliceBuffer = buffer.slice();
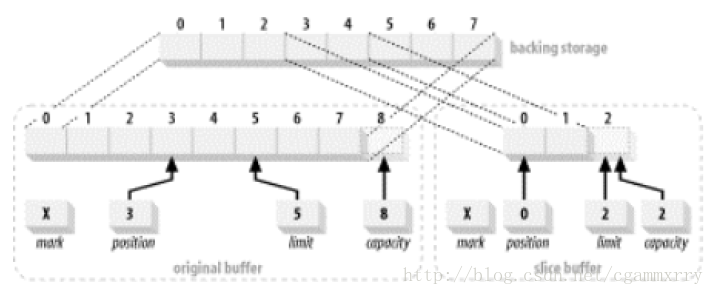
建立分割緩衝區
◇ 位元組緩衝區(ByteBuffer)
ByteBuffer 只是 Buffer 的一個子類,但位元組緩衝區有位元組的獨特之處。位元組緩衝區跟其他緩衝區型別最明顯的不同在於,它可以成為通道所執行的 I/O 的源頭或目標,後面你會發現通道只接收 ByteBuffer 作為引數。
位元組是作業系統及其 I/O 裝置使用的基本資料型別。當在 JVM 和作業系統間傳遞資料時,將其他的資料型別拆分成構成它們的位元組是十分必要的,系統層次的 I/O 面向位元組的性質可以在整個緩衝區的設計以及它們互相配合的服務中感受到。同時,作業系統是在記憶體區域中進行 I/O 操作。這些記憶體區域,就作業系統方面而言,是相連的位元組序列。於是,毫無疑問,只有位元組緩衝區有資格參與 I/O 操作。
非位元組型別的基本型別,除了布林型都是由組合在一起的幾個位元組組成的。那麼必然要引出另外一個問題:位元組順序。
多位元組數值被儲存在記憶體中的方式一般被稱為 endian-ness(位元組順序)。如果數字數值的最高位元組 - big end(大端),位於低位地址(即 big end 先寫入記憶體,先寫入的記憶體的地址是低位的,後寫入記憶體的地址是高位的),那麼系統就是大端位元組順序。如果最低位元組最先儲存在記憶體中,那麼系統就是小端位元組順序。在 java.nio 中,位元組順序由 ByteOrder 類封裝:
Java程式碼
package java.nio;
public final class ByteOrder {
public static final ByteOrder BIG_ENDIAN;
public static final ByteOrder LITTLE_ENDIAN;
public static ByteOrder nativeOrder();
public String toString();
}
ByteOrder 類定義了決定從緩衝區中儲存或檢索多位元組數值時使用哪一位元組順序的常量。如果你需要知道 JVM 執行的硬體平臺的固有位元組順序,請呼叫靜態類函式 nativeOrder()。
每個緩衝區類都具有一個能夠通過呼叫 order() 查詢的當前位元組順序:
Java程式碼
public abstract class CharBuffer extends Buffer implements Comparable, CharSequence {
// This is a partial API listing
public final ByteOrder order();
}
這個函式從 ByteOrder 返回兩個常量之一。對於除了 ByteBuffer 之外的其他緩衝區類,位元組順序是一個只讀屬性,並且可能根據緩衝區的建立方式而採用不同的值。除了 ByteBuffer,其他通過 allocate() 或 wrap() 一個數組所建立的緩衝區將從 order() 返回與 ByteOrder.nativeOrder() 相同的數值。這是因為包含在緩衝區中的元素在 JVM 中將會被作為基本資料直接存取。
ByteBuffer 類有所不同:預設位元組順序總是 ByteBuffer.BIG_ENDIAN,無論系統的固有位元組順序是什麼。Java 的預設位元組順序是大端位元組順序,這允許類檔案等以及序列化的物件可以在任何 JVM 中工作。如果固有硬體位元組順序是小端,這會有效能隱患。在使用固有硬體位元組順序時,將 ByteBuffer 的內容當作其他資料型別存取很可能高效得多。
為什麼 ByteBuffer 類需要一個位元組順序?位元組不就是位元組嗎?ByteBuffer 物件像其他基本資料型別一樣,具有大量便利的函式用於獲取和存放緩衝區內容。這些函式對位元組進行編碼或解碼的方式取決於 ByteBuffer 當前位元組順序的設定。ByteBuffer 的位元組順序可以隨時通過呼叫以 ByteOrder.BIG_ENDIAN 或 ByteOrder.LITTL_ENDIAN 為引數的 order() 函式來改變:
Java程式碼
public abstract class ByteBuffer extends Buffer implements Comparable {
// This is a partial API listing
public final ByteOrder order();
public final ByteBuffer order(ByteOrder bo);
}
如果一個緩衝區被建立為一個 ByteBuffer 物件的檢視,,那麼 order() 返回的數值就是檢視被建立時其建立源頭的 ByteBuffer 的位元組順序。檢視的位元組順序設定在建立後不能被改變,而且如果原始的位元組緩衝區的位元組順序在之後被改變,它也不會受到影響。
◇ 直接緩衝區
核心空間(與之相對的是使用者空間,如 JVM)是作業系統所在區域,它能與裝置控制器(硬體)通訊,控制著使用者區域程序(如 JVM)的執行狀態。最重要的是,所有的 I/O 都直接(實體記憶體)或間接(虛擬記憶體)通過核心空間。
當程序(如 JVM)請求 I/O 操作的時候,它執行一個系統呼叫將控制權移交給核心。當核心以這種方式被呼叫,它隨即採取任何必要步驟,找到程序所需資料,並把資料傳送到使用者空間你的指定緩衝區。核心試圖對資料進行快取記憶體或預讀取,因此程序所需資料可能已經在核心空間裡了。如果是這樣,該資料只需簡單地拷貝出來即可。如果資料不在核心空間,則程序被掛起,核心著手把資料讀進記憶體。
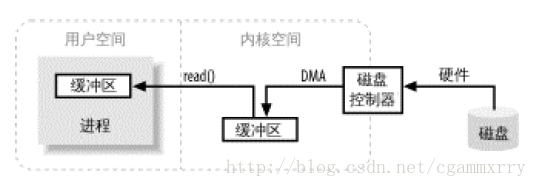
I/O 緩衝區操作簡圖
從圖中你可能會覺得,把資料從核心空間拷貝到使用者空間似乎有些多餘。為什麼不直接讓磁碟控制器把資料送到使用者空間的緩衝區呢?首先,硬體通常不能直接訪問使用者空間。其次,像磁碟這樣基於塊儲存的硬體裝置操作的是固定大小的資料塊,而使用者程序請求的可能是任意大小的或非對齊的資料塊。在資料往來於使用者空間與儲存裝置的過程中,核心負責資料的分解、再組合工作,因此充當著中間人的角色。
因此,作業系統是在記憶體區域中進行 I/O 操作。這些記憶體區域,就作業系統方面而言,是相連的位元組序列,這也意味著I/O操作的目標記憶體區域必須是連續的位元組序列。在 JVM中,位元組陣列可能不會在記憶體中連續儲存(因為 JAVA 有 GC 機制),或者無用儲存單元(會被垃圾回收)收集可能隨時對其進行移動。
出於這個原因,引入了直接緩衝區的概念。直接位元組緩衝區通常是 I/O 操作最好的選擇。非直接位元組緩衝區(即通過 allocate() 或 wrap() 建立的緩衝區)可以被傳遞給通道,但是這樣可能導致效能損耗。通常非直接緩衝不可能成為一個本地 I/O 操作的目標。
如果你向一個通道中傳遞一個非直接 ByteBuffer 物件用於寫入,通道可能會在每次呼叫中隱含地進行下面的操作:
建立一個臨時的直接 ByteBuffer 物件。
將非直接緩衝區的內容複製到臨時直接緩衝區中。
使用臨時直接緩衝區執行低層 I/O 操作。
臨時直接緩衝區物件離開作用域,並最終成為被回收的無用資料。
這可能導致緩衝區在每個 I/O 上覆制併產生大量物件,而這種事都是我們極力避免的。如果你僅僅為一次使用而建立了一個緩衝區,區別並不是很明顯。另一方面,如果你將在一段高效能指令碼中重複使用緩衝區,分配直接緩衝區並重新使用它們會使你遊刃有餘。
直接緩衝區可能比建立非直接緩衝區要花費更高的成本,它使用的記憶體是通過呼叫本地作業系統方面的程式碼分配的,繞過了標準 JVM 堆疊,不受垃圾回收支配,因為它們位於標準 JVM 堆疊之外。
直接 ByteBuffer 是通過呼叫具有所需容量的 ByteBuffer.allocateDirect() 函式產生的。注意,wrap() 函式所建立的被包裝的緩衝區總是非直接的。與直接緩衝區相關的 api:
Java程式碼
public abstract class ByteBuffer extends Buffer implements Comparable {
// This is a partial API listing
public static ByteBuffer allocateDirect (int capacity);
public abstract boolean isDirect();
}
所有的緩衝區都提供了一個叫做 isDirect() 的 boolean 函式,來測試特定緩衝區是否為直接緩衝區。但是,ByteBuffer 是唯一可以被分配成直接緩衝區的 Buffer。儘管如此,如果基礎緩衝區是一個直接 ByteBuffer,對於非位元組檢視緩衝區,isDirect() 可以是 true。
◇ 檢視緩衝區
I/O 基本上可以歸結成組位元組資料的四處傳遞,在進行大資料量的 I/O 操作時,很又可能你會使用各種 ByteBuffer 類去讀取檔案內容,接收來自網路連線的資料,等等。ByteBuffer 類提供了豐富的 API 來建立檢視緩衝區。
檢視緩衝區通過已存在的緩衝區物件例項的工廠方法來建立。這種檢視物件維護它自己的屬性,容量,位置,上界和標記,但是和原來的緩衝區共享資料元素。
每一個工廠方法都在原有的 ByteBuffer 物件上建立一個檢視緩衝區。呼叫其中的任何一個方法都會建立對應的緩衝區型別,這個緩衝區是基礎緩衝區的一個切分,由基礎緩衝區的位置和上界決定。新的緩衝區的容量是位元組緩衝區中存在的元素數量除以檢視型別中組成一個數據型別的位元組數,在切分中任一個超過上界的元素對於這個檢視緩衝區都是不可見的。檢視緩衝區的第一個元素從建立它的 ByteBuffer 物件的位置開始(positon() 函式的返回值)。來自 ByteBuffer 建立檢視緩衝區的工廠方法:
Java程式碼
public abstract class ByteBuffer extends Buffer implements Comparable {
// This is a partial API listing
public abstract CharBuffer asCharBuffer();
public abstract CharBuffer asShortBuffer( );
public abstract CharBuffer asIntBuffer( );
public abstract CharBuffer asLongBuffer( );
public abstract CharBuffer asFloatBuffer( );
public abstract CharBuffer asDoubleBuffer( );
}
下面的程式碼建立了一個 ByteBuffer 緩衝區的 CharBuffer 檢視。演示 7 個位元組的 ByteBuffer 的 CharBuffer 檢視:
Java程式碼
/**
* 1 char = 2 byte,因此 7 個位元組的 ByteBuffer 最終只會產生 capacity 為 3 的 CharBuffer。
*
* 無論何時一個檢視緩衝區存取一個 ByteBuffer 的基礎位元組,這些位元組都會根據這個檢視緩衝區的位元組順序設
* 定被包裝成一個數據元素。當一個檢視緩衝區被建立時,檢視建立的同時它也繼承了基礎 ByteBuffer 物件的
* 位元組順序設定,這個檢視的位元組排序不能再被修改。位元組順序設定決定了這些位元組對是怎麼樣被組合成字元
* 型變數的,這樣可以理解為什麼 ByteBuffer 有位元組順序的概念了吧。
*/
ByteBuffer byteBuffer = ByteBuffer.allocate (7).order (ByteOrder.BIG_ENDIAN);
CharBuffer charBuffer = byteBuffer.asCharBuffer();
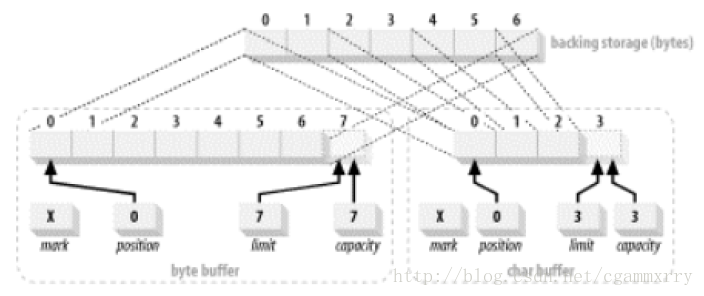
7 個 位元組的 ByteBuffer 的 CharBuffer 檢視
◇ 資料元素檢視
ByteBuffer 類為每一種原始資料型別提供了存取的和轉化的方法:
Java程式碼
public abstract class ByteBuffer extends Buffer implements Comparable {
public abstract short getShort( );
public abstract short getShort(int index);
public abstract short getInt( );
public abstract short getInt(int index);
......
public abstract ByteBuffer putShort(short value);
public abstract ByteBuffer putShort(int index, short value);
public abstract ByteBuffer putInt(int value);
public abstract ByteBuffer putInt(int index, int value);
.......
}
這些函式從當前位置開始存取 ByteBuffer 的位元組資料,就好像一個數據元素被儲存在那裡一樣。根據這個緩衝區的當前的有效的位元組順序,這些位元組資料會被排列或打亂成需要的原始資料型別。
如果 getInt() 函式被呼叫,從當前的位置開始的四個位元組會被包裝成一個 int 型別的變數然後作為函式的返回值返回。實際的返回值取決於緩衝區的當前的位元排序(byte-order)設定。不同位元組順序取得的值是不同的:
Java程式碼
// 大端順序
int value = buffer.order(ByteOrder.BIG_ENDIAN).getInt();
// 小端順序
int value = buffer.order(ByteOrder.LITTLE_ENDIAN).getInt();
// 上述兩種方法取得的 int 是不一樣的,因此在呼叫此類方法前,請確保位元組順序是你所期望的
如果你試圖獲取的原始型別需要比緩衝區中存在的位元組數更多的位元組,會丟擲 BufferUnderflowException。