
使用Linq中的Distinct方法對序列進行去重操作
使用Linq提供的擴充套件方法Distinct可以去除序列中的重複元素。
該方法具有以下兩種過載形式:
(1)public static IEnumerable<TSource> Distinct<TSource>(this IEnumerable<TSource> source) (過載1)
通過使用預設的相等比較器對值進行比較並返回序列中的非重複元素。
(2)publicstatic IQueryable<TSource> Distinct<TSource>(this IQueryable<TSource> source,IEqualityComparer<TSource> comparer) (過載2)
通過使用自定義的相等比較器對值進行比較返回序列中的非重複元素。 自定義的相等比較器需要實現介面IEqualityComparer<T>。
使用預設的相等比較器時,比較器是如何工作的?
對於值型別,比較器通過比較物件的值來確認物件是否相等;
對於引用型別,比較器通過比較物件的引用來確認物件是否相等;
而對於字串型別,儘管是引用型別,但比較器同樣通過比較物件的值來確認物件是否相等。
下面給出兩個使用Distinct方法去除序列重複元素的例項,其中,例1採用預設的比較器來工作,例2採用自定義的比較器工作。
例1 使用Distinct方法去除序列中的同名元素。
例1的執行結果如下圖所示。List<string> nameList = new List<string> { "張三", "李四", "張三", "張三", "李四"}; Console.WriteLine("原始序列:"); foreach (var s in nameList) { Console.WriteLine("Name = {0}", s); } var newNameList = nameList.Distinct(); Console.WriteLine("去重操作後的序列:"); foreach (var s in newNameList) { Console.WriteLine("Name = {0}", s); }
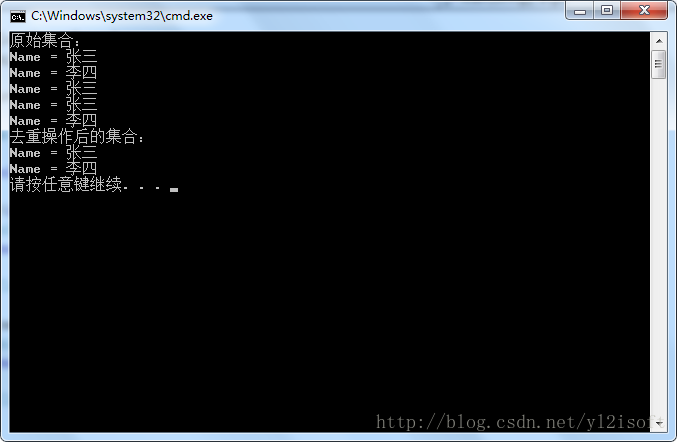
例1中採用Distinct方法的過載1來對序列進行去重操作,即使用預設的比較器來工作,同時,序列的元素型別為字串,所以會通過比較字串的值來確認字串是否相等,這樣一來,在返回的結果中,重複的“張三”與“李四”將會被去除。
例2-1 使用Distinct方法去除序列中的重複的學生元素。
例2-1的執行結果如下圖所示。public class Student { public string StudentName { get; set; } public int StudentCode { get; set; } } List<Student> studentList = new List<Student>(); studentList.Add(new Student() { StudentName = "張三", StudentCode = 1 }); studentList.Add(new Student() { StudentName = "李四", StudentCode = 1 }); studentList.Add(new Student() { StudentName = "張三", StudentCode = 1 }); studentList.Add(new Student() { StudentName = "張三", StudentCode = 2 }); studentList.Add(new Student() { StudentName = "李四", StudentCode = 1 }); Console.WriteLine("原始集合:"); foreach (var s in studentList) { Console.WriteLine("StudentName = {0}, StudentCode = {1}", s.StudentName, s.StudentCode); } var newStudentList = studentList.Distinct(); Console.WriteLine("去重操作後的集合:"); foreach (var s in newStudentList) { Console.WriteLine("StudentName = {0}, StudentCode = {1}", s.StudentName, s.StudentCode); }
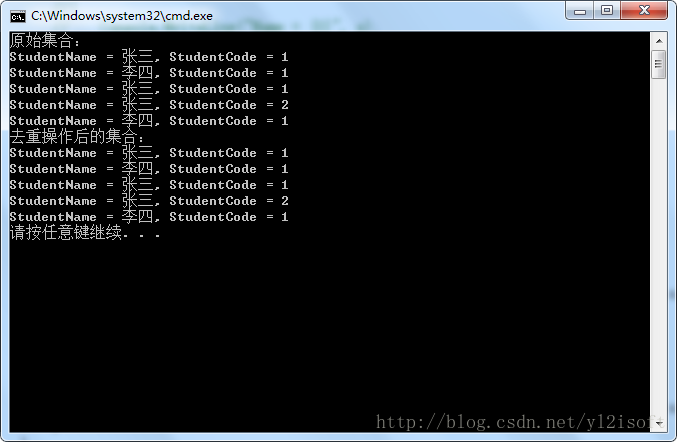
從結果可以看出,對序列執行Distinct方法並沒有去除序列中的重複元素。因為例2-1採用的仍是Distinct方法的過載1來對序列進行去重操作,那麼將會使用預設的比較器來工作,預設的比較器在比較引用型別時是通過比較物件的引用來確認物件是否相等,很顯然,例項序列中的各個元素的引用是不相等的,因此比較器會認為,序列中的全部元素都不相同,因此不會進行去重操作。
例2-2 使用Distinct方法去除序列中的重複的學生元素。(該自定義的比較器出場了吧)
public class StudentComparer : IEqualityComparer<Student>
{
public bool Equals(Student x, Student y)
{
if (Object.ReferenceEquals(x, y)) return true;
if (Object.ReferenceEquals(x, null) || Object.ReferenceEquals(y, null))
return false;
return x.StudentName == y.StudentName && x.StudentCode == y.StudentCode;
}
public int GetHashCode(Student student)
{
if (Object.ReferenceEquals(student, null)) return 0;
int hashStudentName = student.StudentName == null ? 0 : student.StudentName.GetHashCode();
int hashStudentCode = student.StudentCode.GetHashCode();
return hashStudentName ^ hashStudentCode;
}
}
Console.WriteLine("原始集合:");
foreach (var s in studentList)
{
Console.WriteLine("StudentName = {0}, StudentCode = {1}", s.StudentName, s.StudentCode);
}
var newStudentList = studentList.Distinct(new StudentComparer());//將自定義的比較器作為引數傳入
Console.WriteLine("去重操作後的集合:");
foreach (var s in newStudentList)
{
Console.WriteLine("StudentName = {0}, StudentCode = {1}", s.StudentName, s.StudentCode);
}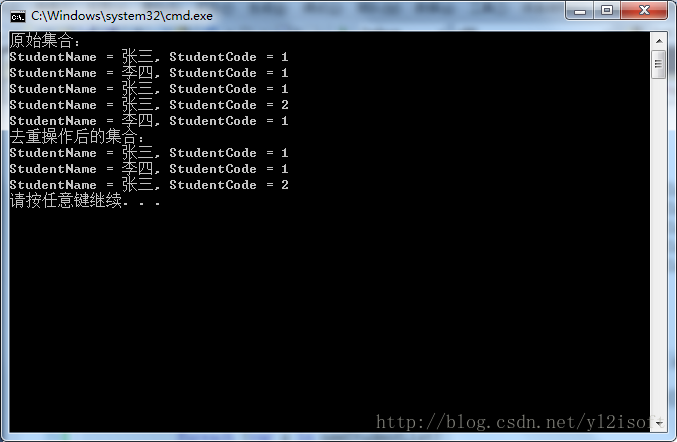
從結果可以看出,此次成功去除了序列中的重複記錄,功勞歸功於我們自定義的比較器,因為自定義的比較器不再通過比較引用來確認物件是否相等了,而是通過比較Student物件的StudentName與StudentCode的值來確認物件是否相等,很顯然,只要著兩個欄位的值相等將會被認為是重複記錄而被去除,所以得到了我們想要的結果。
擴充套件閱讀: