
人臉對齊之SDM / 人臉對齊之LBF / 人臉實時替換

2015年9月16日釋出
2016年5月4日釋出
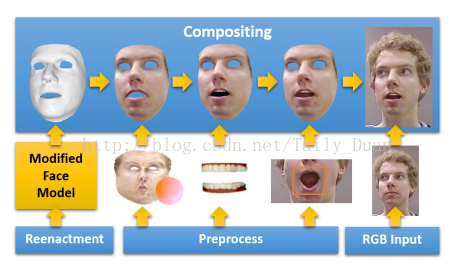
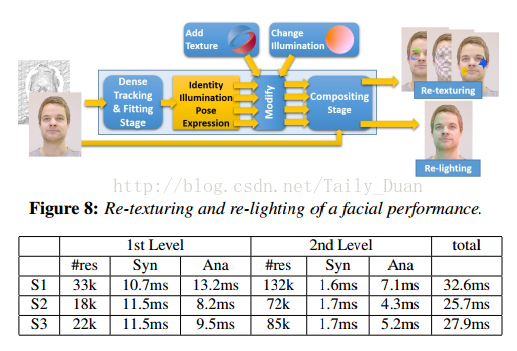
In computer animation, animating human faces is an art itself, but transferring expressions from one human to someone else is an even more complex task. One has to take into consideration the geometry, the reflectance properties, pose, and the illumination of both faces, and make sure that mouth movements and wrinkles are transferred properly. The fact that the human eye is very keen on catching artificial changes makes the problem even more difficult. This paper describes a real-time solution to this animation problem.
______________________
The paper "Face2Face: Real-time Face Capture and Reenactment of RGB Videos" is available here:
Recommended for you:
Real-Time Facial Expression Transfer (previous work) - https://www.youtube.com/watch?v=mkI6q...
WE WOULD LIKE TO THANK OUR GENEROUS SUPPORTERS WHO MAKE TWO MINUTE PAPERS POSSIBLE:
Sunil Kim, Vinay S.
https://www.patreon.com/TwoMinutePapers
Subscribe if you would like to see more of these! -
The background of the thumbnail image was created by DonkeyHotey (CC BY 2.0) - https://flic.kr/p/aPiKLe
Splash screen/thumbnail design: Felícia Fehér - http://felicia.hu
Károly Zsolnai-Fehér's links:
Facebook → https://www.facebook.com/TwoMinutePap...
Twitter → https://twitter.com/karoly_zsolnai
Web → https://cg.tuwien.ac.at/~zsolnai/
-
類別
-
許可
- 標準YouTube許可
======================================================================
SDM(Supervised Descent Method)是一種監督下降方法,屬於解決非線性最小化NLS(Non-linear Least Squares)問題的一種方法。
解決非線性最優化問題通常有2個難點,
(1)方程不可微,或者計算量太大
(2)Hessian矩陣太大,或者不是正定矩陣
基於這樣的難點,作者提出了自己的SDM方法,可以用於解決上述的問題,併成功的用次方法解決了人臉對齊中關鍵點的迴歸問題,取得了state-of-the-art的效果。
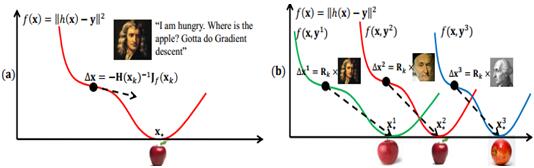
一個傳統和奏效的解決最小化二乘問題的方法就是牛頓下山法,正如,上面左圖所示,通過牛頓迭代,最終可以找到一個全域性最小值。這樣的迭代也肯定是效果最好的,但是在實際工程應用中,是不會有足夠的計算資源來將所有樣本一下都計算進去的,於是就有了上面右圖的方法,更新每一個daerta(x),每次都會找到一個最小值,然後不斷迭代,減少最小值之間的誤差距離,最終就會找到全域性最小值,類似深度學習裡的Mini batch SGD,就像吳恩達視訊中講的,雖然沒有理論的證明,區域性最小值就是全域性最小值,但是很多實際的經驗告訴我們,最後,只能收斂到一個最小值,也就是說,很多現實實際問題是隻有一個最小值的。
ps:還是很喜歡這個圖中的牛頓,高斯和拉格朗日。
SDM推導:
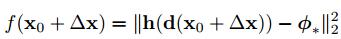
SDM的過程就是最小化上面函式的過程,其中,
d為m*1維,表示有m個畫素,
d(x)為p*1維,表示p個Landmarks,
h為非線性的特徵提取函式,提取的sift特徵h(d(x))為128p維
將上式子進行泰勒展開變為了下面的式子,
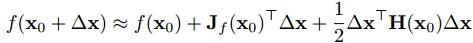
第一次初始化det(x1)按下式計算,
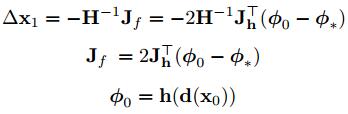
初始化時,第一次對於det(fai)的計算,可以看成det(fai)到R0的投影,因此,也可以近似的將R0看成是梯度方向。
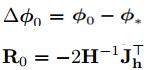
由於將R0近似為梯度方向,所以det由上面的非線性問題轉化為下面式子的線性問題,
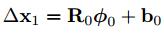
整個的訓練過程就是求一個最佳的R0和b0的過程,來保證det最小。最終也就將遞推公式由下面的第一個式子轉化為下面的第二個式子,也就不需要hession矩陣和Jacobian矩陣的計算了。實現了由2次問題到1次問題的轉化,但是2次問題肯定會收斂,1次的則很難保證,因此,作者引入了fai(k)這個一系列的特徵向量,而不是上式一樣,只有一個fai(0),從而來保證收斂,實驗過程中,迭代4-5次後就會收斂。
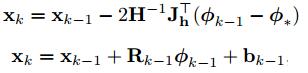
訓練過程中,採用L2-loss,如下式子,
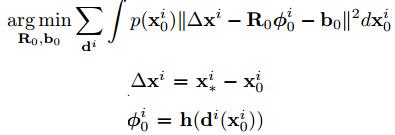
假設x服從正態分佈,採用蒙特卡洛(Monte Carlo)方法取樣,轉化為求下式的最小值,
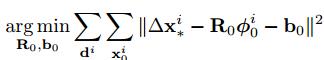
採用多個特徵向量後就轉化為下式,
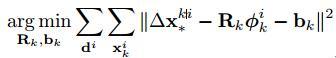
實驗效果:
在人臉對齊中,一個很重要的效能指標就是姿態估計,包括,yaw(左右旋轉),roll(平面內旋轉),pitch(上下旋轉)
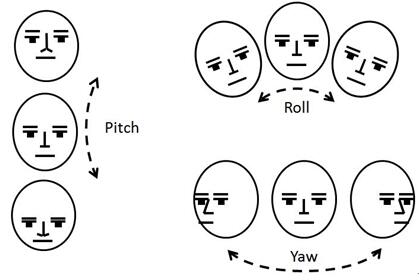
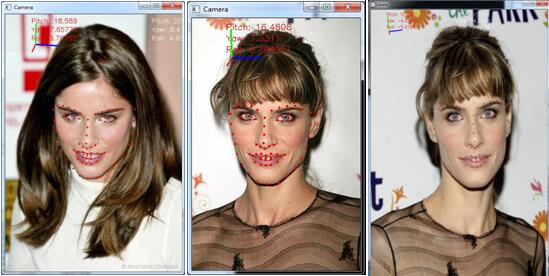
按作者論文中在Youtube上面的測試,姿態估計可以實現,yaw(-45到+45),roll(-90到+90),pitch(-30到+30),在i5-2400上達到了30fps的速度。
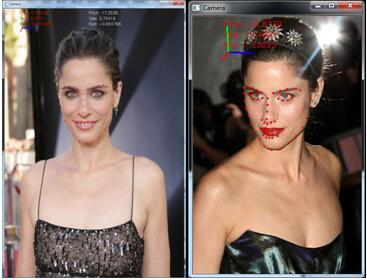
github上熱心網友的程式:
reference:
[1]Szabó Z. Supervised Descent Method and its Applications toFace Alignment[J]. 2015.
[2]www.humansensing.cs.cmu.edu/intraface
=====================================================================================
基於LBF方法的人臉對齊,出自Face Alignment at3000 FPS via Regressing Local Binary Features,由於該方法提取的是區域性二值特徵(LBF),所以特徵提取這個過程速度非常快,導致整個的演算法都速快相當快,論文作者的LBF fast達到了3000fps的速度,網上熱心網友分享的程式也達到了近300fps的速度,絕對是人臉對齊方面速度最快的一種演算法。因此,好多網友也將該方法稱為,3000fps。
該方法主要體現在2個方面,
(1)LBF特徵的提取
作者通過在特徵點附近隨機選擇點做殘差來學習LBF特徵,每一個特徵點都會學到由好多隨機樹組成的隨機森林,因此,一個特徵點就得用一個隨機森林生成的0,1特徵向量來表示,將所有的特徵點的隨機森林都連線到一起,生成一個全域性特徵,後續過程就可以使用該全域性特徵做全域性線性迴歸了。
(2)基於cascade的級聯的隨機森林做全域性線性迴歸
所謂的線性迴歸,其實就是一個不斷迭代的過程,對於每一個stage中,用上一個stage的狀態作為輸入來跟新,產生下一個stage的輸入,以此類推,直到達到最底層stage。
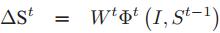
如上公式所示,I為輸入影象,St-1為第t-1stage的形狀,fait為t stage的特徵匹配函式,Wt為線性迴歸矩陣。

訓練過程,就是學習fait和wt的一個過程,測試過程就是用訓練好的fait和wt對提取的LBF特徵做迴歸的過程。
對於每個stage,越往下,所選擇的隨機點的範圍就越小,特徵點定位精度就越好。

本人下載的是c++版本的程式,最終的執行效果如下,
實際執行效果,速度絕對是人臉對齊中速度最快的一個演算法了,精度的話,比起sdm來,還是遜色一點,儘管作者論文中分析的資料來看比sdm好,但是不得不承認,還是比sdm的精度差點。

github上熱心網友的程式,
======================================================
搞了一年人臉識別,尋思著記錄點什麼,於是想寫這麼個系列,介紹人臉識別的四大塊:Face detection, alignment, verification and identification(recognization),本別代表從一張圖中識別出人臉位置,把人臉上的特徵點定位,人臉校驗和人臉識別。(後兩者的區別在於,人臉校驗是要給你兩張臉問你是不是同一個人,人臉識別是給你一張臉和一個庫問你這張臉是庫裡的誰。
今天先介紹第一部分和第二部分。 主要說三篇頂會文章。
==================================
關鍵詞:人臉檢測 人臉校準 特徵點定位 決策樹 隨機森林 CART RandForest RandFern Boosting Realboost
==================================
人臉檢測(detection)在opencv中早就有直接能拿來用的haar分類器,基於Viola-Jones演算法。但是畢竟是老掉牙的技術,Precision/Recall曲線渣到不行,在實際工程中根本沒法給boss看,作為MSRA腦殘粉,這裡介紹一種MSRA在14年的最新技術:Joint Cascade Face Detection and Alignment(ECCV14)。這篇文章直接在30ms的時間裡把detection和alignment都給做了,PR曲線彪到很高,時效性高,記憶體佔用卻非常低,在一些庫上虐了Face++和Google Picasa,正好契合這篇想講的東西。可以作為本節的主線。
人臉校準(alignment)是給你一張臉,你給我找出我需要的特徵點的位置,比如鼻子左側,鼻孔下側,瞳孔位置,上嘴脣下側等等點的位置。如果覺得還是不明白,看下圖:

圖中紅色框框就是在做detection,白色點點就是在做alignment。
如果知道了點的位置做一下位置驅動的變形,臉就成正的了,如何驅動變形不是本節的重點,在此省略。
首先介紹一下下面正文要寫的東西,由於乾貨非常多所以可能會看著看著就亂了,所以給出框架圖:

=================================
廢話說了這麼多,正文開始~
detection
作者建立了一個叫post classifier的分類器,方法如下:
1.樣本準備:首先作者呼叫opencv的Viola-Jones分類器,將recal閥值設到99%,這樣能夠儘可能地檢測出所有的臉,但是同時也會有非常多的不是臉的東東被檢測出來。於是,檢測出來的框框們被分成了兩類:是臉和不是臉。這些圖片被resize到96*96。
2.特徵提取:接下來是特徵提取,怎麼提取呢?作者採用了三種方法:
第一種:把window劃分成6*6個小windows,分別提取SIFT特徵,然後連線著36個sift特徵向量成為影象的特徵。
第二種:先求出一個固定的臉的平均shape(27個特徵點的位置,比如眼睛左邊,嘴脣右邊等等),然後以這27個特徵點為中心提取sift特徵,然後連線後作為特徵。
第三種:用他們組去年的另一個成果Face Alignment at 3000 FPS via Regressing Local Binary Features (CVPR14) ,也就是圖中的3000FPS方法,迴歸出每張臉的shape,然後再以每張臉自己的27個shape points為中心做sift,然後連線得到特徵。
3.分類:將上述的三種特徵分別扔到線性SVM中做分類,訓練出一個能分辨一張圖是不是臉的SVM模型。
緊接著作者將以上三種方法做出的分類器和初始分類器進行比對,畫了一個樣本分佈的圖:

這個圖從左到右依次是原始級聯分類器得到的樣本分類分佈和第一種到第三種方法提取的特徵得到的樣本分類分佈。可見做一下shape alignment可以得到一個更好的分類效果。但是問題來了:如果把所有的windows都做一下alignment,即使是3000 faces per second的速度一張圖可能也要處理上1秒,這無法滿足一般一秒30幀的實時需求。作者也說,用opencv分類器,引數設成99%的recall率將會帶來很嚴重的效率災難——一張圖能找出來3000個框,處理一張圖都要好幾秒。
這麼渣的效率可咋辦呢?以上內容已經證明了alignment確實對detection的preciseness有幫助,這就夠啦,對下面的工作也是個啟發——能不能在做detection的同時把alignment做了呢?alignment的中間結果是否能給detection帶來一些幫助呢?後面慢慢講。先說兩個通用的面部檢測和矯正的模型:
1.級聯檢測分類器(bagging):不失一般性,一個簡單的級聯分類器是這樣的:
圖中的Ci代表的是第i個弱分類器。x代表的是特徵向量,f代表分類得分。每個Ci會根據自己的分類方法對x輸出一個分類結果,比如是一張臉或者不是一張臉,而fn(n=1~N)都會對應一個thresholdΘi,讓任意一個fn小於對應的Θi的時候,樣本就會被拒絕。通常不是一張臉的圖片在經過前幾個弱分類器的判斷後就會被拒絕,根本不用做後面的判斷,所以速度很快。
2.級聯迴歸校準(我這翻譯…+_+):這裡介紹的是另一個人在10年發的文章:Cascaded Pose Regression (CVPR10),給影象一個初始shape(通常採用平均shape),然後通過一次一次的迴歸把shape迴歸到正確的地方。演算法結構很簡單,但是效果確實非常好:
迴歸過程如下:首先提取特徵,原作者採用的是Pose-Indexed point features,然後根據特徵訓練迴歸函式(可以用線性迴歸,CART,隨機森林等等),原作者採用了一個叫Random Fern Regressor的東西,這裡翻譯成隨機蕨好了(這名字…),迴歸出這一階段的偏移量,然後shape加上這個偏移量,反覆這一過程,直到迭代上限或者shape錯誤率不再下降。隨機蕨的演算法過程和隨機森林類似,他是一個半樸素貝葉斯模型。首先選取M組每組K個特徵建立M個蕨(弱分類器),然後假設蕨內特徵是相關的,蕨間特徵是獨立的,這樣從統計學上隨機蕨是一個完整的把樸素貝葉斯分類器,讓計算變得簡單:
式中C代表分類,ci代表第I類,M代表蕨數量。
綜上,這樣迴歸的過程可以總結成如下形式:
S代表shape,St代表在迴歸第t階段的shape,他等於上一階段的shape加上一個偏置,這個偏置就是上述迴歸方法之一搞定的。比如隨機森林或者隨機蕨,或者線性迴歸。
現在再說說怎麼訓練得到這個迴歸Rt。
有兩種思路:一種是像剛才隨機蕨那樣,每個每個蕨的葉子節點儲存一個偏移量,計算訓練的時候落入這個葉子節點的樣本偏移之平均,然後作為最終的葉子節點偏移量。其實就是在優化一個如下目標函式:
然而MSRA組在3000fps中採用的是另一種方法,形狀的偏移量ΔδS為:
目標函式是:
其實也是同樣的思路,Φ代表特徵提取函式,論文中稱Φ的輸出為區域性二值特徵(LBF),W為線性迴歸引數矩陣,其實就是把提取出來的特徵對映到一個二維的偏移量上,是一個2*lenth(特徵空間維數)的變換矩陣。
首先講Φ是怎麼訓練的:Φ其實就是一個隨機森林。輸入畫素差特徵(pixel-difference features),輸出一個offest。訓練的時候隨機給每個根節點畫素差特徵中的一部分。非葉節點的分裂依據是從輸入的pixel-difference features中找出能夠做到最大的方差衰減的feature。在最後的葉子節點上寫上落在葉子節點上的樣本偏移量,這個偏移量在之前說到的fern裡有用,但是在這裡沒啥用,因為作者最後不是用這個做迴歸的而是用LBF,詳細的得往下看。如果有多個樣本都落在這裡,則求平均。這樣訓練出來的東西就是下面這個公式所表達的東西:
可能有讀者看到這就會不懂了,不用管這個公式,等下面的看完了就會懂了。
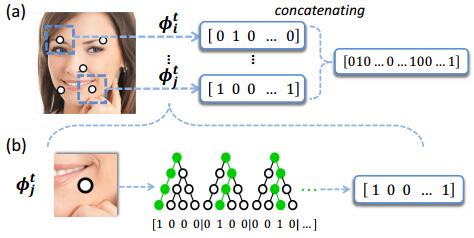
但是我只想要其中的Φ,於是這裡給出了LBF(local binary feature)的定義,直接簡單粗暴地統計所有樹葉節點是否被該樣本落入,如果落入了就記為1否則記為0,然後把所有的01串連起來就是LBF了。還是看圖說話:
先看b,隨機森林的三棵樹,樣本經過三棵樹後分別落在了第1,2,3個葉子節點上,於是三棵樹的LBF就是1000,0100,0010.連線起來就是100001000010.然後看a,把27個特徵點的lbf都連線起來形成總的LBF就是Φ了。
接下來是訓練w:之前已經得到了wΦ(I,S)以及Φ(I,S),現在想求w,這還不容易嗎,直接算呀。不過作者又調皮了,他說他不想求w,而是想求一個總的大W=[w1,w2,w3,…,w27].怎麼求呢?得做二次迴歸。至於為什麼要這麼做下面會介紹。目標函式:
後面加了個L2項,因為W是炒雞sparse的,防止過擬合。做線性迴歸即可得到W。
現在解釋一下為啥不直接用w1w2w3…而是要再回歸出來一個W:原因有兩個:
1. 再次迴歸W可以去除原先小wi葉子節點上的噪聲,因為隨機森林裡的決策樹都是弱分類器嘛噪聲多多滴;
2.大W是全域性迴歸(之前的一個一個小w也就是一個一個特徵點單獨的迴歸是local迴歸),全域性迴歸可以有效地實施一個全域性形狀約束以減少區域性誤差以及模糊不清的區域性表現。
這樣一來,測試的時候每輸入一張圖片I,先用隨機森林Φ求出它的LBF,然後在用W乘一下就得到了下一個stage的shape,然後迭代幾次就得到了最終的shape。所以效率十分的快。









好了,兜了一大圈該回來了,剛才講的是兩個uniform的model來做detection和shape regression的。接下來該講作者是怎麼邊detection邊regression shape的了!
作者建立了一個分類迴歸樹,就叫CRT好了。這個CRT在距離根節點比較近的幾層偏重於分類,在接近葉子節點的幾層偏重於迴歸,具體實現上,每個節點究竟用於迴歸還是分類呢?用一個概率p表示用於分類的概率,自然迴歸就是1-p了。而這個p隨著深數的深度減小,作者採用了一個經驗公式:
![]()
知道了CRT怎麼建立,那就直接就看演算法細節吧!邊測試是不是臉邊做特徵點回歸的演算法如下:

這個模型的訓練方法如下:

這樣就算完了嗎?不,既然要實現,就要細看一下以上用到的各類演算法細節:
部分摘自其他部落格,詳見參考文獻。
1.CART(Classification And Regression Tree)
思想:遞迴地將輸入空間分割成矩形
優點:可以進行變數選擇,可以克服missing data,可以處理混合預測
缺點:不穩定分類訓練過程:







就這樣不斷分割之後可以建立如下這樣的決策樹:
2.Bagging (Breiman1996): 也稱bootstrap aggregation
Bagging的策略:
- 從樣本集中用Bootstrap取樣選出n個樣本
- 在所有屬性上,對這n個樣本建立分類器(CART or SVM or ...)
- 重複以上兩步m次,i.e.build m個分類器(CART or SVM or ...)
- 將資料放在這m個分類器上跑,最後vote看到底分到哪一類
Fit many large trees to bootstrap resampled versions of the training data, and classify by majority vote.
下圖是Bagging的選擇策略,每次從N個數據中取樣n次得到n個數據的一個bag,總共選擇B次得到B個bags,也就是B個bootstrap samples.流程圖如下:
3.隨機森林:
隨機森林,指的是利用多棵樹對樣本進行訓練並預測的一種分類器。該分類器最早由Leo Breiman和Adele Cutler提出,並被註冊成了商標。簡單來說,隨機森林就是由多棵CART(Classification And Regression Tree)構成的。對於每棵樹,它們使用的訓練集是從總的訓練集中有放回取樣出來的,這意味著,總的訓練集中的有些樣本可能多次出現在一棵樹的訓練集中,也可能從未出現在一棵樹的訓練集中。在訓練每棵樹的節點時,使用的特徵是從所有特徵中按照一定比例隨機地無放回的抽取的,根據Leo Breiman的建議,假設總的特徵數量為M,這個比例可以是sqrt(M),1/2sqrt(M),2sqrt(M)。
因此,隨機森林的訓練過程可以總結如下:
(1)給定訓練集S,測試集T,特徵維數F。確定引數:使用到的CART的數量t,每棵樹的深度d,每個節點使用到的特徵數量f,終止條件:節點上最少樣本數s,節點上最少的資訊增益m
對於第1-t棵樹,i=1-t:
(2)從S中有放回的抽取大小和S一樣的訓練集S(i),作為根節點的樣本,從根節點開始訓練
(3)如果當前節點上達到終止條件,則設定當前節點為葉子節點,如果是分類問題,該葉子節點的預測輸出為當前節點樣本集合中數量最多的那一類c(j),概率p為c(j)佔當前樣本集的比例;如果是迴歸問題,預測輸出為當前節點樣本集各個樣本值的平均值。然後繼續訓練其他節點。如果當前節點沒有達到終止條件,則從F維特徵中無放回的隨機選取f維特徵。利用這f維特徵,尋找分類效果最好的一維特徵k及其閾值th,當前節點上樣本第k維特徵小於th的樣本被劃分到左節點,其餘的被劃分到右節點。繼續訓練其他節點。有關分類效果的評判標準在後面會講。
(4)重複(2)(3)直到所有節點都訓練過了或者被標記為葉子節點。
(5)重複(2),(3),(4)直到所有CART都被訓練過。
利用隨機森林的預測過程如下:
對於第1-t棵樹,i=1-t:
(1)從當前樹的根節點開始,根據當前節點的閾值th,判斷是進入左節點(<th)還是進入右節點(>=th),直到到達,某個葉子節點,並輸出預測值。
(2)重複執行(1)直到所有t棵樹都輸出了預測值。如果是分類問題,則輸出為所有樹中預測概率總和最大的那一個類,即對每個c(j)的p進行累計;如果是迴歸問題,則輸出為所有樹的輸出的平均值。
注:有關分類效果的評判標準,因為使用的是CART,因此使用的也是CART的平板標準,和C3.0,C4.5都不相同。
對於分類問題(將某個樣本劃分到某一類),也就是離散變數問題,CART使用Gini值作為評判標準。定義為Gini=1-∑(P(i)*P(i)),P(i)為當前節點上資料集中第i類樣本的比例。例如:分為2類,當前節點上有100個樣本,屬於第一類的樣本有70個,屬於第二類的樣本有30個,則Gini=1-0.7×07-0.3×03=0.42,可以看出,類別分佈越平均,Gini值越大,類分佈越不均勻,Gini值越小。在尋找最佳的分類特徵和閾值時,評判標準為:argmax(Gini-GiniLeft-GiniRight),即尋找最佳的特徵f和閾值th,使得當前節點的Gini值減去左子節點的Gini和右子節點的Gini值最大。
對於迴歸問題,相對更加簡單,直接使用argmax(Var-VarLeft-VarRight)作為評判標準,即當前節點訓練集的方差Var減去減去左子節點的方差VarLeft和右子節點的方差VarRight值最大。
Random Forest與Bagging的區別在於:Bagging每次生成決策樹的時候從全部的屬性Attributes裡面選擇,而Random Forest是隨機從全部Attributes的集合裡面生成一個大小固定的子集,相對而言需要的計算量更小一些。
4.Boosting(Freund & Schapire 1996):
boosting在選擇hyperspace的時候給樣本加了一個權值,使得loss function儘量考慮那些分錯類的樣本(i.e.分錯類的樣本weight大)。
怎麼做的呢?
- boosting重取樣的不是樣本,而是樣本的分佈,對於分類正確的樣本權值低,分類錯誤的樣本權值高(通常是邊界附近的樣本),最後的分類器是很多弱分類器的線性疊加(加權組合),分類器相當簡單。結構如圖:
AdaBoost和RealBoost是Boosting的兩種實現方法。general的說,Adaboost較好用,RealBoost較準確。由於Boosting演算法在解決實際問題時有一個重大的缺陷,即他們都要求事先知道弱分類演算法分類正確率的下限,這在實際問題中很難做到。後來 Freund 和 Schapire提出了 AdaBoost 演算法,該演算法的效率與 Freund 方法的效率幾乎一樣,卻可以非常容易地應用到實際問題中。AdaBoost 是Boosting 演算法家族中代表演算法,AdaBoost 主要是在整個訓練集上維護一個分佈權值向量 D( x) t ,用賦予權重的訓練集通過弱分類演算法產生分類假設 Ht ( x) ,即基分類器,然後計算他的錯誤率,用得到的錯誤率去更新分佈權值向量 D( x) t ,對錯誤分類的樣本分配更大的權值,正確分類的樣本賦予更小的權值。每次更新後用相同的弱分類演算法產生新的分類假設,這些分類假設的序列構成多分類器。對這些多分類器用加權的方法進行聯合,最後得到決策結果。這種方法不要求產生的單個分類器有高的識別率,即不要求尋找識別率很高的基分類演算法,只要產生的基分類器的識別率大於 015 ,就可作為該多分類器序列中的一員。
尋找多個識別率不是很高的弱分類演算法比尋找一個識別率很高的強分類演算法要容易得多,AdaBoost 演算法的任務就是完成將容易找到的識別率不高的弱分類演算法提升為識別率很高的強分類演算法,這也是 AdaBoost 演算法的核心指導思想所在,如果演算法完成了這個任務,那麼在分類時,只要找到一個比隨機猜測略好的弱分類演算法,就可以將其提升為強分類演算法,而不必直接去找通常情況下很難獲得的強分類演算法。通過產生多分類器最後聯合的方法提升弱分類演算法,讓他變為強的分類演算法,也就是給定一個弱的學習演算法和訓練集,在訓練集的不同子集上,多次呼叫弱學習演算法,最終按加權方式聯合多次弱學習演算法的預測結果得到最終學習結果。包含以下2點:樣本的權重
AdaBoost 通過對樣本集的操作來訓練產生不同的分類器,他是通過更新分佈權值向量來改變樣本權重的,也 就是提高分錯樣本的權重,重點對分錯樣本進行訓練。
(1) 沒有先驗知識的情況下,初始的分佈應為等概分佈,也就是訓練集如果有 n個樣本,每個樣本的分佈概率為1/ n。(2) 每次迴圈後提高錯誤樣本的分佈概率,分錯的樣本在訓練集中所佔權重增大,使得下一次迴圈的基分類器能夠集中力量對這些錯誤樣本進行判斷。弱分類器的權重
最後的強分類器是通過多個基分類器聯合得到的,因此在最後聯合時各個基分類器所起的作用對聯合結果有很大的影響,因為不同基分類器的識別率不同,他的作用就應該不同,這裡通過權值體現他的作用,因此識別率越高的基分類器權重越高,識別率越低的基分類器權重越低。權值計算如下: 基分類器的錯誤率: e = ∑( ht ( x i) ≠yi) Di (1) 基分類器的權重:W t = F( e) ,由基分類器的錯誤率計算他的權重。2.3 演算法流程及偽碼描述 演算法流程描述 演算法流程可用結構圖 1 描述,如圖 1 所示 AdaBoost重複呼叫弱學習演算法(多輪呼叫產生多個分類器) ,首輪呼叫弱學習演算法時,按均勻分佈從樣本集中選取子集作為該次訓練集,以後每輪對前一輪訓練失敗的樣本,賦予較大的分佈權值( Di 為第i 輪各個樣本在樣本集中參與訓練的概率) ,使其在這一輪訓練出現的概率增加,即在後面的訓練學習中集中對比較難訓練的樣本進行學習,從而得到 T個弱的基分類器, h1 , h2 , …, ht ,其中 ht 有相應的權值 w t ,並且其權值大小根據該分類器的效果而定。最後的分類器由生成的多個分類器加權聯合產生。











==================================
參考文章:
[1]Joint Cascade Face Detection and Alignment(ECCV14)
[2]Face Alignment at 3000 FPS via Regressing Local Binary Features (CVPR14)
[3]Cascaded Pose Regression (CVPR10)
[4]Fast Keypoint Recognition in Ten Lines of Code
Taily老段的微信公眾號,歡迎交流學習