
日誌分析:SLS vs ELK
背景
提到日誌實時分析,大部分人第一想到是社群很火ELK Stack(Elastic/Logstash/Kibana)。ELK方案上手難度小、開源材料眾多、在社群中有大量的使用案例。
阿里雲日誌服務(SLS/Log) 是阿里巴巴集團對日誌場景的解決方案產品,前身是2012年初阿里雲在研發飛天作業系統過程中用來監控+問題診斷的產物,但隨著使用者增長與產品發展,慢慢開始向面向Ops(DevOps,Market Ops,SecOps)日誌分析領域發展(見下圖),期間經歷雙十一、螞蟻雙十二、新春紅包、國際業務等場景挑戰,成為同時服務內外的產品。

面向日誌分析場景
搞搜尋都知道Apache Lucene(Lucene是Doug Cutting 2001年貢獻,Doug也是Hadoop創始人)。2012年Elastic把Lucene基礎庫包成了一個更好用的軟體,並且在2015年推出ELK Stack(Elastic Logstash Kibana)解決集中式日誌採集、儲存和查詢問題。Lucene設計場景是Information Retrial,面對是Document型別,因此對於Log這種資料有一定限制,例如規模、查詢能力、以及一些定製化功能(例如智慧聚類LogReduce)等。
SLS提供日誌儲存引擎是阿里內部自研究技術,經過3年W級應用錘鍊,每日索引資料量達PB級,服務萬級開發者每天億次查詢分析。在阿里集團內阿里雲全站,SQL審計、鷹眼、螞蟻雲圖、飛豬Tracing、阿里雲諦聽等都選擇SLS作為日誌分析引擎。
<div id="xe41iq" data-type="image" data-display="block" data-align="center" data-src="https://cdn.nlark.com/lark/0/2018/png/26154/1545743982489-63f095dc-da3c-4fd4-ab2a-52a055b15e10.png" data-width="747"> <img src="https://cdn.nlark.com/lark/0/2018/png/26154/1545743982489-63f095dc-da3c-4fd4-ab2a-52a055b15e10.png" width="747" /> </div>
而日誌查詢是DevOps最基礎需求,從業界的調研《50 Most Frequently Used Unix Command》也驗證了這一點,排名第一的是tar、第二的就Grep這個命令了,由此可見他對程式設計師的重要性。
我們在日誌查詢分析場景上以如下點對ELK 與 SLS 做一個全方位比較:
- 易用:上手及使用過程中的代價
- 功能(重點):主要針對查詢分析兩個場景
- 效能(重點):對於單位大小資料量查詢與分析需求,延時如何
- 規模(重點):能夠承擔的資料量,擴充套件性等
- 成本:同樣功能和效能,使用分別花多少錢
利益關係:本人SLS研發可能帶一些主觀色彩, 但一切都以技術指標來對比,如有偏頗請不吝指正
易用性
對日誌分析系統而言,有如下使用過程:
- 採集:將資料穩定寫入
- 配置:如何配置資料來源
- 擴容:接入更多資料來源,更多機器,對儲存空間,機器進行擴容
- 匯出:資料能否方便匯出到其他系統,例如做流計算、放到物件儲存中進行備份
- 多租戶:如何將資料能否分享給他人使用,使用是否安全等
以下是比較結果:
| 採集 | 協議 |
|
|
| 客戶端 |
|
|
|
| 配置 | 單元 |
|
|
| 屬性 |
|
|
|
| 擴容 | 儲存 |
|
|
| 計算 |
|
|
|
| 配置 |
|
|
|
| 採集點 |
|
|
|
| 容量 |
|
|
|
| 匯出 | 方式 |
|
|
| 多租戶 | 安全 |
|
|
| 流控 |
|
|
|
| 多租戶 |
|
|
整體而言:
- ELK 有非常多生態和寫入工具,使用中的安裝、配置等都有較多工具可以參考
- SLS 是託管服務,從接入、配置、使用上整合度非常高,普通使用者5分鐘就可以接入,但在生態與豐富度和ELK相比有較大差距
- SLS 是SaaS化服務,在過程中不需要擔心容量、併發等問題,彈性伸縮,免運維
功能(查詢+分析)
查詢主要將符合條件的日誌快速命中,分析功能是對資料進行統計與計算。例如我們有如下需求:所有大於200讀請求,根據Ip統計次數和流量,這樣的分析請求就可以轉化為兩個操作:查詢到指定結果,對結果進行統計分析。在一些情況下我們也可以不進行查詢,直接對所有日誌進行分析。
Query1:
Status in (200,500] and Method:Get*
Query2:
select count(1) as c, sum(inflow) as sum_inflow, ip group by Ip查詢基礎對比
| 型別 | 小項 | ELK | SLS |
|---|---|---|---|
| 文字 | 索引查詢 | 支援 | 支援 |
| 分詞 | 支援 | 支援 | |
| 中文分詞 | 支援 | 支援 | |
| 字首 | 支援 | 支援 | |
| 字尾 | 支援 | ||
| 模糊 | 支援 | 可通過SQL支援 | |
| Wildcast | 支援 | 可通過SQL支援 | |
| 數值 | long | 支援 | 支援 |
| double | 支援 | 支援 | |
| Nested | Json | 支援 | |
| Geo | Geo | 支援 | 可通過SQL支援 |
| Ip | Ip查詢 | 支援 | 可通過SQL支援 |
對比結論
- ES 支援資料型別豐富度,原生查詢能力比SLS更完整
- SLS 能夠通過SQL方式(如下)來代替字串模糊查詢,Geo等比較函式,但效能會比原生查詢稍差
子串命中
* | select content where content like '%substring%' limit 100
正則表示式匹配
* | select content where regexp_like(content, '\d+m')limit 100
JSON內容解析與匹配
* | select content where json_extract(content, '$.store.book')='mybook' limit 100
如果設定json型別索引也可以使用:
field.store.book='mybook'查詢擴充套件能力
在日誌分析場景中,光有檢索可能還不夠,需要能夠圍繞查詢做進一步的工作:
- 定位到錯誤日誌後,想看看上下文是什麼引數引起了錯誤
- 定位到錯誤後,想看看之後有沒有類似錯誤,類似tail -f 原始日誌檔案,並進行grep
- 通過關鍵詞搜尋到一大堆日誌(例如百萬條),其中90%都是已知問題剛乾擾調查線索
SLS 針對以上問題提供閉環解決方案:
- 上下文查詢(Context Lookup):原始上下文翻頁,免登伺服器
- LiveTail功能(Tail-f):原始上下文tail-f,更新實時情況
- 智慧聚類(LogReduce):根據日誌Pattern動態歸類,合併重複模式,洞察異常

查詢擴充套件能力(1):LiveTail(雲端 tail -f)
在傳統的運維方式中,如果需要對日誌檔案進行實時監控,需要到伺服器上對日誌檔案執行命令tail -f,如果實時監控的日誌資訊不夠直觀,可以加上grep或者grep -v進行關鍵詞過濾。SLS在控制檯提供了日誌資料實時監控的互動功能LiveTail,針對線上日誌進行實時監控分析,減輕運維壓力。

Livetail特點如下:
- 智慧支援Docker、K8S、伺服器、Log4J Appender等來源資料
- 監控日誌的實時資訊,標記並過濾關鍵詞
- 日誌欄位做分詞處理,以便查詢包含分詞的上下文日誌
具體使用場景參見文件:https://help.aliyun.com/document_detail/93633.html

查詢擴充套件能力(2):智慧聚類(LogReduce)
業務的高速發展,對系統穩定性提出了更高的要求,各個系統每天產生大量的日誌,你是否曾擔心過:
- 系統有潛在異常,但被淹沒在海量日誌中
- 機器被入侵,有異常登入,卻後知後覺
- 新版本上線,系統行為有變化,卻無法感知
這些問題,歸根到底,是資訊太多、太雜,不能良好歸類,同時記錄資訊的日誌,往往還都是無Schema,格式多樣,歸類難道更大。SLS提供實時日誌智慧聚類(LogReduce)功能根據日誌的相似性進行歸類,快速掌握日誌全貌: - 支援任意格式日誌:Log4J、Json、單行(syslog)
- 日誌經任意條件過濾後再Reduce;對Reduce後Pattern,根據signature反查原始資料
- 不同時間段Pattern比較
- 動態調整Reduce精度
- 億級資料,秒級出結果

文件:
分析能力對比
ES在docvalue之上提供一層聚合(Aggregation)語法,並且在6.x版本中提供SQL語法能夠對資料進行分組聚合運算。
SLS支援完整SQL92標準(提供restful 和 jdbc兩種協議),除基本聚合功能外,支援完整的SQL計算,並支援外部資料來源聯合查詢(Join),機器學習,模式分析等函式。

除SQL92標準語法外,我們根據實際日誌分析需求,研發一系列實用的功能:
分析功能演示(1):同比、環比函式
同比環比函式能夠通過SQL巢狀對任意計算(單值、多值、曲線)計算同環比(任意時段),以便洞察增長趨勢。
* | select compare( pv , 86400) from (select count(1) as pv from log)*|select t, diff[1] as current, diff[2] as yestoday, diff[3] as percentage from(select t, compare( pv , 86400) as diff from (select count(1) as pv, date_format(from_unixtime(__time__), '%H:%i') as t from log group by t) group by t order by t) s
分析功能演示(2):外部資料來源聯合查詢(Join)
可以在查詢分析中關聯外部數
- 支援logstore,MySQL,OSS(CSV)等資料來源
- 支援left,right,out,innerjoin
- SQL查詢外表,SQLJoin外表

Join外表的樣例:
sql
建立外表:
* | create table user_meta ( userid bigint, nick varchar, gender varchar, province varchar, gender varchar,age bigint) with ( endpoint='oss-cn-hangzhou.aliyuncs.com',accessid='LTA288',accesskey ='EjsowA',bucket='testossconnector',objects=ARRAY['user.csv'],type='oss')
使用外表
* | select u.gender, count(1) from chiji_accesslog l join user_meta1 u on l.userid = u.userid group by u.gender雲棲:https://yq.aliyun.com/articles/613365
文件:https://help.aliyun.com/document_detail/70479.html
分析功能演示(3):地理位置函式
針對IP地址、手機等內容,內建地理位置函式方便分析使用者來源,包括:
- IP:國家、省市、城市、經緯度、運營商
- Mobile:運營商、省市
- GeoHash:Geo位置與座標轉換
查詢結果分析樣例:
sql
* | SELECT count(1) as pv, ip_to_province(ip) as province WHERE ip_to_domain(ip) != 'intranet' GROUP BY province ORDER BY pv desc limit 10
* | SELECT mobile_city(try_cast("mobile" as bigint)) as "城市", mobile_province(try_cast("mobile" as bigint)) as "省份", count(1) as "請求次數" group by "省份", "城市" order by "請求次數" desc limit 100 查詢結果:

GeoHash:https://help.aliyun.com/document_detail/84374.html
IP函式:https://help.aliyun.com/document_detail/63458.html
電話號碼:https://help.aliyun.com/document_detail/98580.html
分析功能演示(4):安全分析函式
依託全球白帽子共享安全資產庫,提供安全檢測函式,您只需要將日誌中任意的IP、域名或者URL傳給安全檢測函式,即可檢測是否安全。
- security_check_ip
- security_check_domain
- security_check_url

分析功能演示(5):機器學習與時序檢測函式
新增機器學習與智慧診斷系列函式:
1)根據歷史自動學習其中規律,並對未來的走勢做出預測;
2)實時發現不易察覺的異常變化,並通過分析函式組合推理導致異常的特徵;
3)結合環比、告警功能智慧發現/巡檢。該功能適用在智慧運維、安全、運營等領域,幫助更快、更有效、更智慧洞察資料。
提供的功能有:
- 預測:根據歷史資料擬合基線
- 異常檢測、變點檢測、折點檢測:找到異常點
- 多週期檢測:發現數據訪問中的週期規律
- 時序聚類:找到形態不一樣的時序

文件: https://help.aliyun.com/document_detail/93024.html
雲棲:https://yq.aliyun.com/articles/670718
分析功能演示(6):模式分析函式
模式分析函式能夠洞察資料中的特徵與規律,幫助快速、準確推斷問題:
- 定位頻繁集
例如:錯誤請求中90%由某個使用者ID構成 -
定位兩個集合中最大支援因素,例如:
- 延時>10S請求中某個ID構成比例遠遠大於其他維度組合
- 並且該ID在對比集合(B)中的比例較低
- A和B中差異明顯

效能
接下來我們測試針對相同資料集,分別對比寫入資料及查詢,和聚合計算能力。
實驗環境
- 測試配置
| 自建ELK | LogSearch/LogAnalytics | |
|---|---|---|
| 環境 | ECS 4核16GB * 4臺 + 高效雲盤 SSD | |
| Shard | 10 | 10 |
| 拷貝數 | 2 | 3 (預設配置,對使用者不可見) |
-
測試資料
- 5列double,5列long,5列text,字典大小分別是256,512,768,1024,1280
- 以上欄位完全隨機(測試日誌樣例如下)
- 原始資料大小:50 GB
- 日誌行數:162,640,232 (約為1.6億條)
timestamp:August 27th 2017, 21:50:19.000
long_1:756,444 double_1:0 text_1:value_136
long_2:-3,839,872,295 double_2:-11.13 text_2:value_475
long_3:-73,775,372,011,896 double_3:-70,220.163 text_3:value_3
long_4:173,468,492,344,196 double_4:35,123.978 text_4:value_124
long_5:389,467,512,234,496 double_5:-20,10.312 text_5:value_1125寫入測試結果
ES採用bulk api批量寫入,SLS(LogSearch/Analytics)用PostLogstoreLogs API批量寫入,結果如下:
| 型別 | 專案 | 自建ELK | LogSearch/Analytics |
|---|---|---|---|
| 延時 | 平均寫入延時 | 40 ms | 14 ms |
| 儲存 | 單拷貝資料量 | 86G | 58G |
| 膨脹率:資料量/原始資料大小 | 172% | 121% |
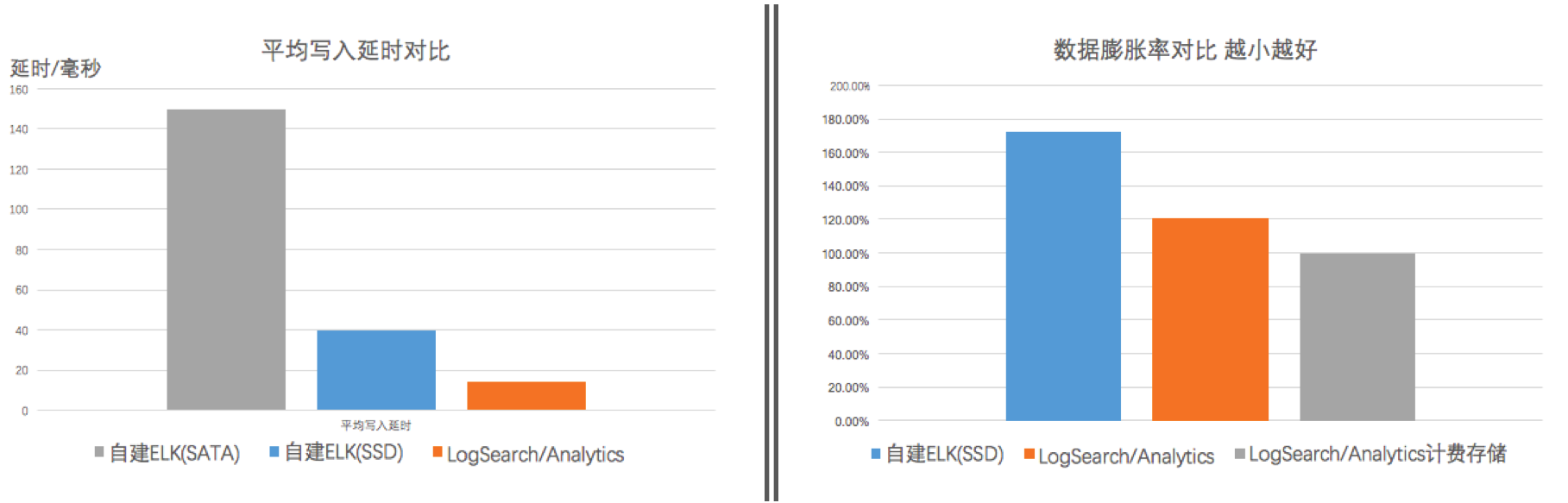
備註:SLS 產生計費的儲存量包括壓縮的原始資料寫入量(23G)+索引流量(27G),共50G儲存費用。
從測試結果來看
- SLS寫入延時好於ES,40ms vs 14 ms
- 空間:原始資料50G,因測試資料比較隨機所以儲存空間會有膨脹(大部分真實場景下,儲存會因壓縮後會比原始資料小)。ES脹到86G,膨脹率為172%,在儲存空間超出SLS 58%。這個資料與ES推薦的儲存大小為原始大小2.2倍比較接近。
讀取(查詢+分析)測試
測試場景
選取兩種比較常見的場景:日誌查詢和聚合計算。分別統計併發度為1,5,10時,兩種case的平均延時。
-
針對全量資料,對任意text列計算group by,計算5列數值的avg/min/max/sum/count,並按照count排序,取前1000個結果,例如:
select count(long_1) as pv,sum(long_2),min(long_3),max(long_4),sum(long_5) group by text_1 order by pv desc limit 1000 -
針對全量資料,隨機查詢日誌中的關鍵詞,例如查詢 "value_126",獲取命中的日誌數目與前100行,例如:
value_126
測試結果
| 型別 | 併發數 | ES延時(單位s) | LogSearch/Analytics延時(單位s) |
|---|---|---|---|
| case1:分析類 | 1 | 3.76 | 3.4 |
| 5 | 3.9 | 4.7 | |
| 10 | 6.6 | 7.2 | |
| case2:查詢類 | 1 | 0.097 | 0.086 |
| 5 | 0.171 | 0.083 | |
| 10 | 0.2 | 0.082 |

結果分析
- 從結果看,對於1.5億資料量這個規模,兩者都達到了秒級查詢與分析能力
- 針對統計類場景(case 1), ES和日誌服務延時處同一量級。ES採用SSD硬碟,在讀取大量資料時IO優勢比較高
- 針對查詢類場景(case 2), LogAnalytics在延時明顯優於ES。隨著併發的增加,ELK延時對應增加,而LogAnalytics延時保持穩定甚至略有下降
規模與成本
1. 規模能力
- SLS可以處理PB/Day級資料,一次查詢可以在秒級過TB規模資料,在資料規模上可以做到彈性伸縮與水平擴充套件
-
ES比較適合服務場景為:寫入GB-TB/Day、儲存在TB級。主要受限於2個原因:
- 單叢集規模:比較理想為20臺左右,據我瞭解業界比較大為100節點一個叢集,為了應對業務往往拆成多個叢集
- 寫入擴容:shard建立後便不可再修改,當吞吐率增加時,需要動態擴容節點,最多可使用的節點數便是shard的個數
- 儲存擴容:主shard達到磁碟的上線時,要麼遷移到更大的一塊磁碟上,要麼只能分配更多的shard。一般做法是建立一個新的索引,指定更多shard,並且rebuild舊的資料
1.1 使用者案例(規模帶來的問題)
客戶A是國內最大資訊類網站之一,有數千臺機器與百號開發人員。運維團隊原先負責一套ELK叢集用來處理Nginx日誌,但始終處於無法大規模使用狀態:
- 一個大Query容易把叢集打爆,導致其他使用者無法使用
- 在業務高峰期間,採集與處理能力打滿叢集,造成資料丟失,查詢結果不準確
- 業務增長到一定規模,因記憶體設定、心跳同步等節點經常記憶體失控導致OOM
不能保證可用性與準確性,開發最終沒有使用起來,成為一個擺設。
在2018年6月份,運維團隊開始執行SLS方案:
- 使用Logtail來採集線上日誌,將採集配置,機器管理等通過API整合進客戶自己運維與管控系統
- 將SLS查詢頁面嵌入統一登入與運維平臺,進行業務與賬戶許可權隔離
- 通過控制檯內嵌方案滿足開發查詢日誌需求,通過Grafana外掛呼叫SLS統一業務監控,通過DataV連線SLS進行大盤搭建
控制檯嵌入方案:https://help.aliyun.com/document_detail/74971.html
接入Grafana:https://help.aliyun.com/document_detail/60952.html
接入DataV:https://help.aliyun.com/document_detail/62961.html
對接Jaeger:https://help.aliyun.com/document_detail/68035.html
整體架構如下圖:

平臺上線2個月後:
- 每天查詢的呼叫量大幅上升,開發逐步開始習慣在運維平臺進行日誌查詢與分析,提升了研發的效率,運維部門也回收了線上登入的許可權
- 除Nginx日誌外,把App日誌、移動端日誌、容器日誌也進行接入,規模是之前10倍
- 除查詢日誌外,也衍生出很多新的玩法,例如通過Jaeger外掛與控制檯基於日誌搭建了Trace系統,將線上錯誤配置成每天的告警與報表進行巡檢
- 通過統一日誌接入管理,規範了各平臺對接匯流排,不再有一份資料同時被採集多次的情況,大資料部門Spark、Flink等平臺可以直接去訂閱實時日誌資料進行處理
2. 成本估計
以上述測試資料為例,一天寫入50GB資料(其中27GB 為實際的內容),儲存90天,平均一個月的耗費。
- 日誌服務(LogSearch/LogAnalytics)計費規則參考,包括讀寫流量、索引流量、儲存空間等計費項,查詢功能免費。
| 計費專案 | 值 | 單價 | 費用(元) |
|---|---|---|---|
| 讀寫流量 | 23G * 30 | 0.2 元/GB | 138 |
| 儲存空間(儲存90天) | 50G * 90 | 0.3 元/GB*Month | 1350 |
| 索引流量 | 27G * 30 | 0.35 元/GB | 283 |
| 總計 | 1771 |
-
ES費用包括機器費用,及儲存資料SSD雲盤費用
- 雲盤一般可以提供高可靠性,因此我們這裡不計費副本儲存量
- 儲存盤一般需要預留15%剩餘空間,以防空間寫滿,因此乘以一個1.15係數
| 計費專案 | 值 | 單價 | 費用(元) |
|---|---|---|---|
| 伺服器 | 4臺4核16G(三個月)(ecs.mn4.xlarge) | 包年包月費用:675 元/Month | 2021 |
| 儲存 | 86 * 1.15 * 90 (這裡只計算一個副本) | SSD:1 元/GB*M | 8901 |
| SATA:0.35 元/GB*M | 3115 | ||
| 總計 | 12943 (SSD) | ||
| 5135 (SATA) |

同樣效能,使用SLS(SSD)費用比為 13.6%。在測試過程中,我們也嘗試把SSD換成SATA以節省費用(SLS與SATA版費用比為 34%),但測試發現延時會從40ms上升至150ms,在長時間讀寫下,查詢和讀寫延時變得很高,無法正常工作了。
3. 時間成本(Time to Value)
除硬體成本外,SLS在新資料接入、搭建新業務、維護與資源擴容成本基本為0:
- 支援各種日誌處理生態,可以和Spark、Hadoop、Flink、Grafana等系統無縫對接
- 在全球化部署(有20+ Region),方便拓展全球化業務
- 提供30+日誌接入SDK,與阿里雲產品無縫打通整合
SLS採集和視覺化可以參見如下文章,非核心功能不展開做比較

寫在最後
ES是一把鋒利的軍刀,支撐更新、查詢、刪除等更通用場景,在搜尋、資料分析、應用開發等領域有廣泛使用,ELK組合在日誌分析場景上把ES靈活性與效能發揮到極致;SLS是純定位在日誌類資料分析場景的服務,在該領域內做了很多定製化開發。一個服務更廣,一個場景更專。當然離開了場景純數字的比較沒有意義,找到適合自己場景的才重要。