
LeetCode: Two Sum 求解兩數之和及雜湊演算法
=======題目描述=======
題目連結:https://leetcode.com/problems/two-sum/
題目內容:
Two Sum
Given an array of integers, return indices of the two numbers such that they add up to a specific target.
You may assume that each input would have exactly one solution, and you may not use the same
Example:
Given nums = [2, 7, 11, 15], target = 9,
Because nums[0] + nums[1] = 2 + 7 = 9,
return [0, 1].=======演算法實現=======
雜湊法
C++實現
class Solution { public: vector<int> twoSum(vector<int>& nums, int target) { unordered_map<int, int> umapping; vector<int> result; //將陣列轉換為雜湊表 for(int i=0; i<nums.size();i++) { umapping[nums[i]]= i; } for(int i=0;i<nums.size();i++) { //將target與當前nums[i]的差即另一個目標的值,作為key int gap= target-nums[i]; //umapping.find(gap) !=umapping.end() 代表存在於雜湊表中 //umapping[gap]>i代表非同一個數組元素 if(umapping.find(gap) !=umapping.end() &&umapping[gap]>i) { result.push_back(i); result.push_back(umapping[gap]); break; } } return result; } };
c++ unordered_map 判斷某個鍵是否存在:
unordered_map c++ reference 是c++ 雜湊表的實現模板,在標頭檔案<unordered_map>中,儲存key-value的組合,unordered_map可以在常數時間內,根據key來取到value值。
若有unordered_map<int, int> mp;查詢x是否在map中
方法1: 若存在 mp.find(x)!=mp.end()
方法2: 若存在 mp.count(x)!=0
python實現
class Solution:
def twoSum(self, nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: List[int]
"""
num_dict = dict()
# 建立字典.
for num_ndx in range(len(nums)):
num_dict[nums[num_ndx]] = num_ndx
for i in range(len(nums)):
diff = target - nums[i]
if (diff in num_dict and num_dict[diff] != i):
return [i, num_dict[diff]]
=======演算法筆記->雜湊演算法=======
什麼是雜湊表和雜湊演算法
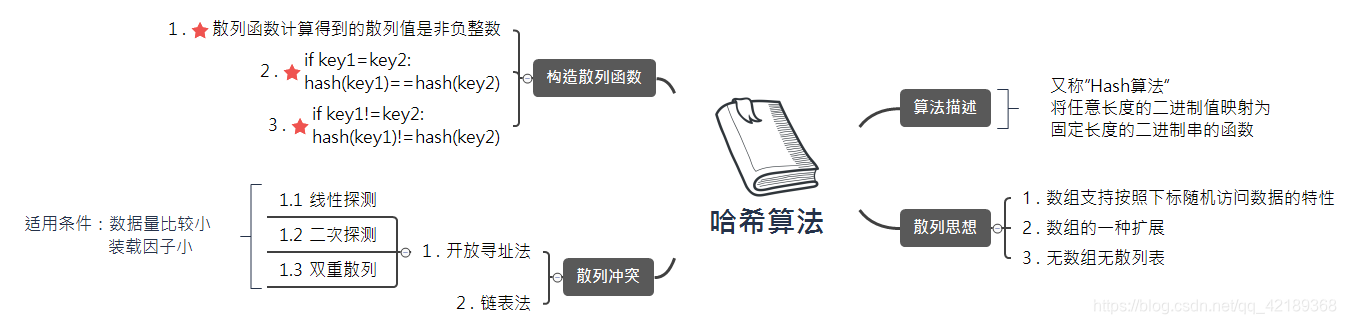
圖片來自:https://github.com/Burgessz/leetcode_solution
什麼是雜湊表和雜湊演算法?中講解的很生動:
①
雜湊演算法並不是一個特定的演算法而是一類演算法的統稱。雜湊演算法也叫雜湊演算法,一般來說滿足這樣的關係:f(data)=key,輸入任意長度的data資料,經過雜湊演算法處理後輸出一個定長的資料key。同時這個過程是不可逆的,無法由key逆推出data。
如果是一個data資料集,經過雜湊演算法處理後得到key的資料集,然後將keys與原始資料進行一一對映就得到了一個雜湊表。一般來說雜湊表M符合M[key]=data這種形式。
雜湊表的優點:當原始資料較大時,可以用雜湊演算法處理得到定長的雜湊值key,那麼這個key相對原始資料要小得多。就可以用這個較小的資料集來做索引,達到快速查詢的目的。
②
雜湊(Hash)是一種資料編碼方式,將大尺寸的資料(如一句話,一張圖片,一段音樂、一個視訊等)濃縮到一個數字中,從而方便地實現資料匹配·查詢的功能。
比如有一萬首歌,要求按照某種方式儲存好。到時給你一首新歌(命名為X),要求你確認新的這首歌是否在那一萬首歌之內。
無疑將一萬首歌一個個比對非常慢。但如果存在一種方式能將一萬首歌的每一首資料濃縮到一個數字(稱為雜湊碼)中,於是得到一萬個數字,那麼用同樣的演算法計算新歌X的編碼,看歌X的編碼是否在之前一萬個數字中,就能知道歌X是否在一萬首歌中。
將一首歌的5M位元組資料濃縮到一個數字中的演算法就是雜湊演算法。
那一萬首歌按照各自的編碼數字從小到大排序後得到的一個表就是雜湊表。
顯然,由於資訊量的丟失,有可能多首歌的雜湊碼是同一個。好的雜湊演算法會盡量減少這種衝突,讓不同的歌有不同的雜湊碼。最差的雜湊演算法自然就是所有的歌用那個演算法算出來的都是同一個雜湊碼。
作為例子,如果要你組織那一萬首歌,一個簡單的雜湊演算法就是讓歌曲所佔硬碟的位元組數作為雜湊碼。這樣的話,你可以讓一萬首歌“按照大小排序”,然後遇到一首新的歌,只要看看新的歌的位元組數是否和已有的一萬首歌中的某一首的位元組數相同,就知道新的歌是否在那一萬首歌之內了。
對於一萬首歌的規模而言,這個演算法已經相當好,因為兩首歌有完全相同的位元組數是不大可能的。就算真有極小概率出現不同的歌有相同的雜湊碼,那也只有寥寥幾首歌,此時再逐首比對即可。
雜湊表優缺點
雜湊表是一種與陣列、連結串列等不同的資料結構,與他們需要不斷的遍歷比較來查詢的辦法,雜湊表設計了一個對映關係f(key)= address,根據key來計算儲存地址address,這樣可以1次查詢,f既是儲存資料過程中用來指引資料儲存到什麼位置的函式,也是將來查詢這個位置的演算法,叫做雜湊演算法。
陣列的特點是:定址容易,插入和刪除困難;
而連結串列的特點是:定址困難,插入和刪除容易。
優點:
雜湊表是種資料結構,它可以提供快速的插入操作和查詢操作。不論雜湊表中有多少資料,插入和刪除(有時包括側除)只需要接近常量的時間即0(1)的時間級。
缺點:
雜湊表也有一些缺點它是基於陣列的,陣列建立後難於擴充套件某些雜湊表被基本填滿時,效能下降得非常嚴重,所以程式雖必須要清楚表中將要儲存多少資料(或者準備好定期地把資料轉移到更大的雜湊表中,這是個費時的過程)。
而且,也沒有一種簡便的方法可以以任何一種順序〔例如從小到大〕遍歷表中資料項。如果需要這種能力,就只能選擇其他資料結構。
然而如果不需要有序遍歷資料,井且可以提前預測資料量的大小。那麼雜湊表在速度和易用性方面是無與倫比的。
解決衝突的辦法:
1、開放定址法
Hi=(H(key)+di) MOD m i=1,2,...,k(k<=m-1)
其中m為表長,di為增量序列
如果di值可能為1,2,3,...m-1,稱線性探測再雜湊。
如果di取值可能為1,-1,2,-2,4,-4,9,-9,16,-16,...k*k,-k*k(k<=m/2)
稱二次探測再雜湊。
如果di取值可能為偽隨機數列。稱偽隨機探測再雜湊。
例:在長度為11的雜湊表中已填有關鍵字分別為17,60,29的記錄,現有第四個記錄,其關鍵字為38,由雜湊函式得到地址為5,若用線性探測再雜湊,如下:

2、再雜湊法
當發生衝突時,使用第二個、第三個、雜湊函式計算地址,直到無衝突時。缺點:計算時間增加。
3、鏈地址法
將所有關鍵字為同義詞的記錄儲存在同一線性連結串列中。
 雜湊表演算法
雜湊表演算法
4、建立一個公共溢位區
假設雜湊函式的值域為[0,m-1],則設向量HashTable[0..m-1]為基本表,另外設立儲存空間向量OverTable[0..v]用以儲存發生衝突的記錄。
雜湊表,首先是一種資料結構,是一種效率極高的查詢方式,雜湊表的核心在於雜湊函式的設計,雜湊衝突了不要緊,我們要增加隨機性以及對衝突進行適當的有損化的處理。