python - 中文編碼/ASCII
Python 中文編碼:
為了處理漢字,程式設計師設計了用於簡體中文的GB2312和用於繁體中文的big5.
GB2312(1980年)一共收錄了7445個字元,包括6763個漢子和682個其他符號。漢字區的內碼範圍高位元組從B0-E7,低位元組A1-FE,佔用的碼位是72*94=6768.其中5個空位是D7FA-D7EF。
GB2312支援的漢字太少。1995年的漢字擴充套件規範GBK1.0收錄了21886個符號,它分為漢字去和圖形符號區。漢字區包括21003個字元,2000年的GB18030是取代GBK1.0的正式國家標準。該標準收錄了27484個漢字,同時還收錄了藏文、蒙文、維吾爾文扥更主要的少數名族文字。現在的PC平臺必須支援GB18030,對嵌入式產品暫不做要求。所以手機、MP3一般支援GB2312.
從ASCII、GB2312、GBK到GB18030,這些編碼方法是向下相容的,即同一個字元在這些方案中總是有相同的編碼,後面的標準支援更多的字元。這些編碼中,英文和中文可以統一地處理,區分中文編碼的方法是高位元組的最高位不為0.按照程式設計師的稱呼,GB2312、GBK到GB18030都屬於雙位元組字符集(DBCS)
有的中文windows的預設內碼還是GBK,可以通過GB18030升級包升級到GB118030,不過GB18030相對GBK增加的字元,普通人很難用到,通常我們還是用GBK只帶中文windows內碼。
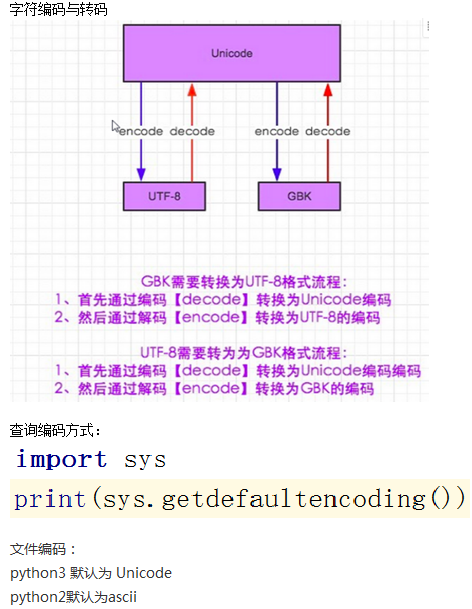
關於ASCII碼/unicode/utf-8
顯然ASCII碼無法將世界上的各種文字和符號全部表示,所以,就需要新出一種可以程式碼所有字元和符號的編碼即:Unicode
unicode(統一碼、萬國碼、單一碼)是一種在計算機上使用的字元編碼、unicode是為了解決傳統的字元編碼方法的侷限而產生的,它為每種語言中的每個字元設定了統一併且唯一的二進位制編碼,規定雖有的字元和符號最少由16位表示(2個位元組)即2**16 = 65536
UTF-8是對unicode編碼的壓縮和優化,他不在使用最少使用2個位元組,而是將所有的字元和符號進行分類ascii碼中的內容用1個位元組儲存、歐洲的字元用2個位元組儲存,東亞的字元用3個位元組儲存。
所以,python直譯器在載入.py檔案中的程式碼時,會對內容進行編碼(預設ascill)
時間節點:
ASCII 255 1bytes
————1980 GB2312 7XXX
-----------1995 GBK1.0 2w+
-------------2000 GB18030 27xxxx
__________UNICODE 2bytes
----------utf-8 en:1byte, zh :3btes