
Spark Client和Cluster兩種執行模式的工作流程
1.client mode: In client mode,
the driver is launched in the same process as the client that submits the application..也就是說在Client模式下,Driver程序會在當前客戶端啟動,客戶端程序一直存在直到應用程式執行結束。
該模式下的工作流程圖主要如下:
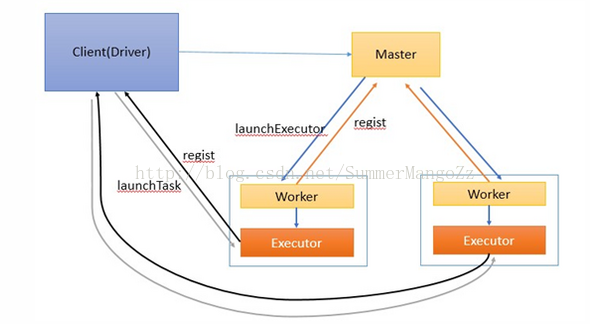
工作流程如下:
1.啟動master和worker . worker負責整個叢集的資源管理,worker負責監控自己的cpu,記憶體資訊並定時向master彙報
2.在client中啟動Driver程序,並向master註冊
3.master通過rpc與worker進行通訊,通知worker啟動一個或多個executor程序
4.executor程序向Driver註冊,告知Driver自身的資訊,包括所在節點的host等
5.Driver對job進行劃分stage,並對stage進行更進一步的劃分,將一條pipeline中的所有操作封裝成一個task,併發送到向自己註冊的executor
程序中的task執行緒中執行
6.應用程式執行完成,Driver程序退出
2.cluster模式:In cluster
該模式下的工作流程圖如下:
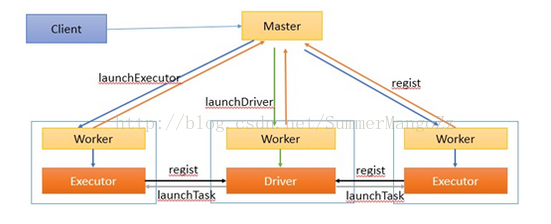
工作流程如下:
1.在叢集的節點中,啟動master , worker程序,worker程序啟動成功後,會向Master進行註冊。
2.客戶端提交任務後,ActorSelection(master的actor引用),然後通過ActorSelection給Master傳送註冊Driver請求(RequestSubmitDriver)
3.客戶端提交任務後,master通知worker節點啟動driver程序。(worker的選擇是隨意的,只要worker有足夠的資源即可)
driver程序啟動成功後,將向Master返回註冊成功資訊
4.master通知worker啟動executor程序
5.啟動成功後的executor程序向driver進行註冊
6.Driver對job進行劃分stage,並對stage進行更進一步的劃分,將一條pipeline中的所有操作封裝成一個task,併發送到向自己註冊的executor
程序中的task執行緒中執行
7.所有task執行完畢後,程式結束。
通過上面的描述我們知道:Mater負責整個叢集的資源的管理和建立worker,worker負責當前結點的資源的管理,並會將當前的cpu,記憶體等資訊定時告知master,並且負責建立Executor程序(也就是最小額資源分配單位),Driver負責整個應用任務的job的劃分和stage的切割以及task的切割和優化,並負責把task分發到worker對應的節點的executor程序中的task執行緒中執行, 並獲取task的執行結果,Driver通過SparkContext物件與spark叢集獲取聯絡,得到master主機host,就可以通過rpc向master註冊自己。