
第十七天 -- IDEA -- MAVEN -- AWK -- MapReduce簡單案例
第十七天 – IDEA – MAVEN – AWK – MapReduce簡單案例
一、IDEA
安裝
下載地址 點選進入
分為旗艦版和社群版,旗艦版需要付費,可以破解,社群版完全免費,它們在一些功能支援上有所差異。推薦使用旗艦版。
下載後直接一路下一步安裝即可,可以修改安裝路徑等配置。
破解
旗艦版安裝完成後需要破解,破解過程 點選進入 按照該網頁提示的過程即可破解。
簡單配置
設定位置:File – Settings
-
字型大小、顏色等:Editor – Font / Color Scheme
-
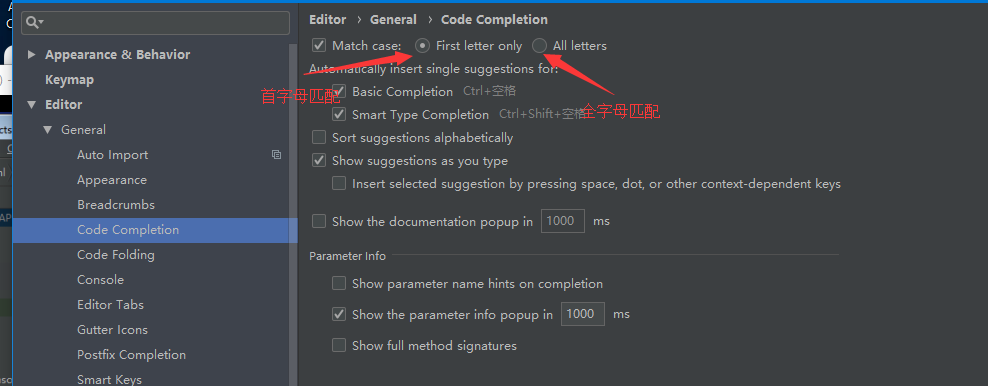
程式碼提示:Editor – General – Code Completion,建議選擇首字母匹配
-
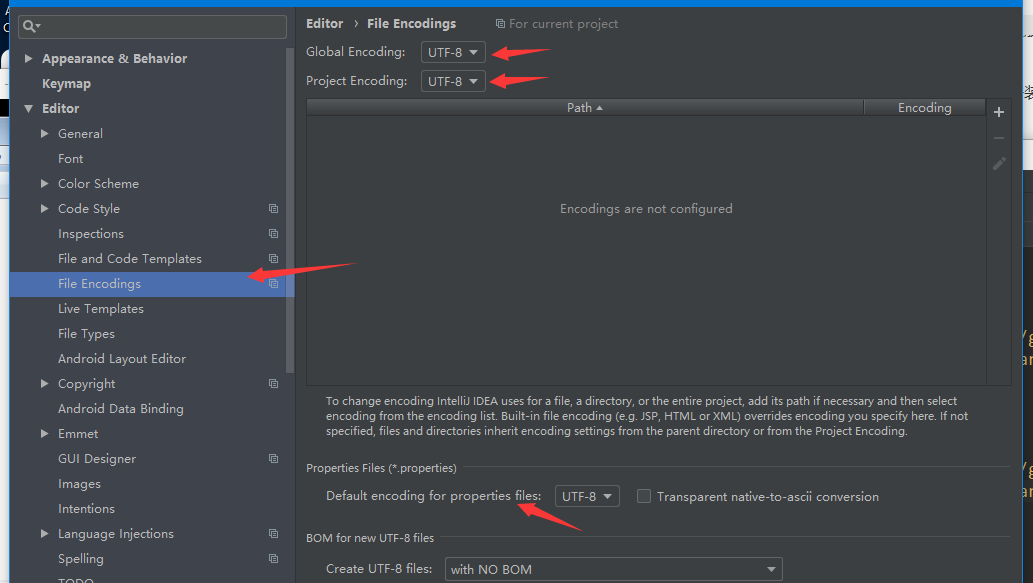
編碼設定:Editor – File Encodings,將下圖三處改為UTF-8
-
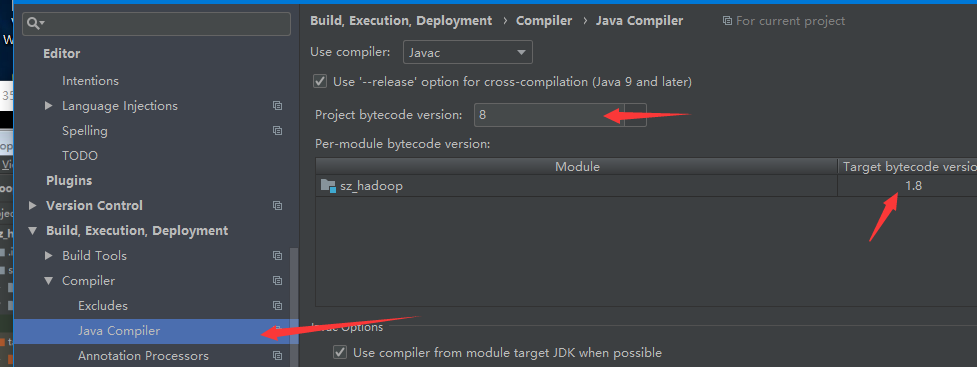
修改jdk版本:Build,Execution,Deployment – Compiler – Java Compiler
-
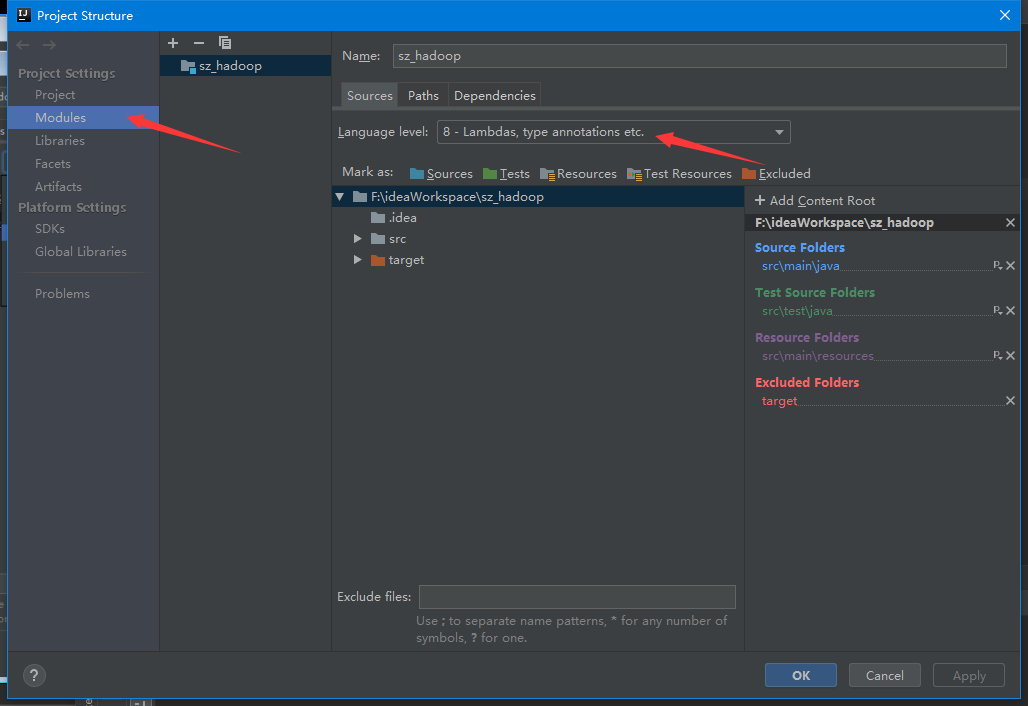
專案中修改Modules的jdk:File – Project Structure,選中Modules
常用快捷鍵
- Ctrl+Shift + Enter,語句補全
- Ctrl+Alt+L,格式化程式碼(與qq快捷鍵衝突)
- Ctrl+Enter,匯入包,自動修正
- Ctrl+Alt+T,把程式碼包在一個塊內,例如:if、if/else、try/catch等
- Ctrl+Alt+V,引入變數。例如:輸入new ArrayList(); 會自動補全為ArrayList<Object> objects = new ArrayList<>();
- Ctrl+X,刪除當前行
- Ctrl+D,複製當前行到下一行
- Ctrl+/或Ctrl+Shift+/,註釋(//或者/**/)
- Shift+Enter,向下插入新行
- Ctrl+O,重寫方法
- Ctrl+I,實現方法
二、Maven
簡介
Apache Maven是一個軟體專案管理和綜合工具。基於專案物件模型(POM)的概念,Maven可以從一箇中心資料片管理專案構建,報告和檔案。
下載
解壓安裝
直接使用解壓縮軟體解壓至某個安裝目錄下,如D:\software\apache-maven-3.3.9
配置環境變數
右鍵此電腦 – 屬性 – 高階系統設定 – 環境變數
- 在系統變數中新建MVN_HOME,值D:\software\apache-maven-3.3.9
- 編輯Path變數,新增%MVN_HOME%\bin
測試
開啟cmd,輸入mvn -version,出現以下資訊,代表安裝、配置環境變數成功

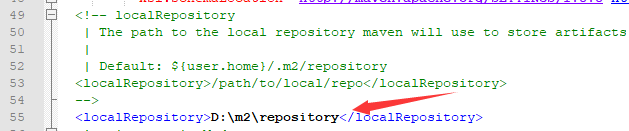
配置maven本地倉庫
開啟maven安裝目錄comf資料夾下的settings.xml,預設配置是將本地倉庫存放在該使用者家目錄的.m2資料夾下的repository下,但考慮到使用者目錄一般在C盤,下載的jar包多了之後佔用系統盤空間,所以自行配置將存放位置配置到其他盤中
D:\m2\repository
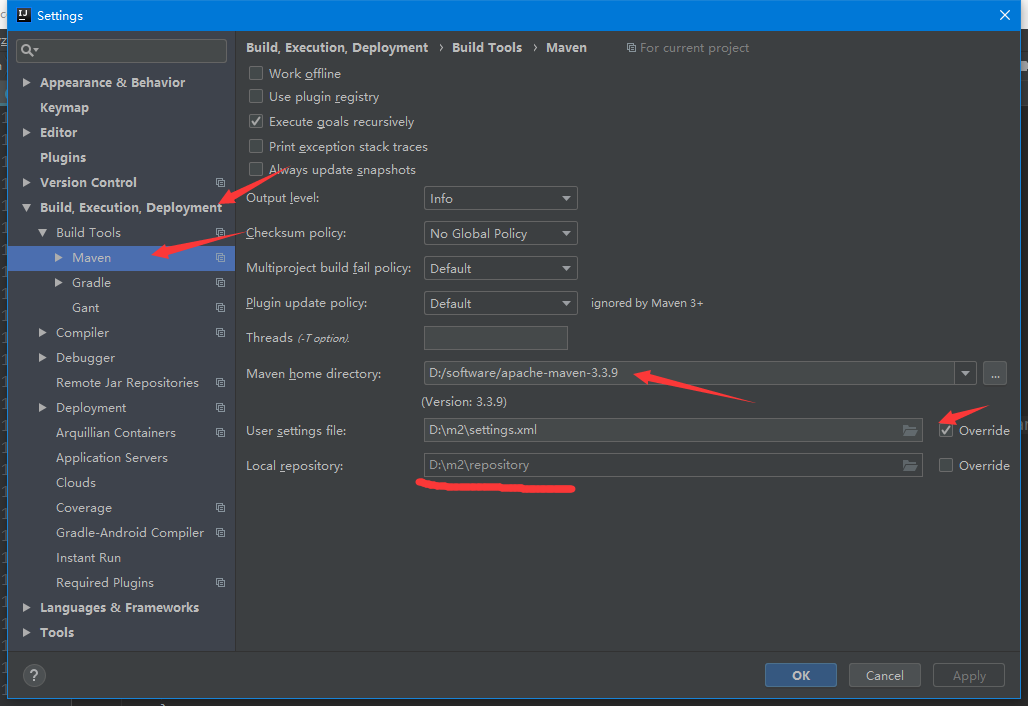
Idea中配置Maven
File – Settings --Build,Execution,Deployment – Maven
配置Maven home directory為本地安裝目錄(idea自帶兩個maven,但是不利於進行配置,所以使用自己安裝的maven)
配置User settings file,將Override打上勾,選擇自己的配置檔案settings.xml,選中後Local repository會自動變為settings.xml上一步配置的本地倉庫目錄
**注意:**settings只是設定當前專案,需要選擇other settings --> default settings(或者是settings for new projects)再設定一遍。這樣新建專案後設置項也不會變回默認了
Maven依賴查詢
三、IDEA專案
新建Maven專案
File – New – Project,選擇Maven,選擇sdk版本,可以New本機jdk安裝目錄

pom.xml
新建maven專案時,會自動生成pom.xml,此檔案中可以配置依賴、打包選項等功能。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.szbd</groupId>
<artifactId>sz_hadoop</artifactId>
<version>1.0</version>
<!--配置專案所依賴的jar包-->
<dependencies>
</dependencies>
</project>
配置jar包依賴,在maven依賴查詢網址中查到對應的配置項後,複製貼上到標籤中
四、awk命令
簡介
awk其名稱得自於它的創始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首個字母。實際上 AWK 的確擁有自己的語言: AWK 程式設計語言 , 三位建立者已將它正式定義為“樣式掃描和處理語言”。它允許您建立簡短的程式,這些程式讀取輸入檔案、為資料排序、處理資料、對輸入執行計算以及生成報表,還有無數其他的功能。
awk基本命令格式
資料來源|awk -F “” ‘BEGIN{} {}… END{}’
awk -F “” ‘BEGIN{} {}… END{}’ 資料來源
awk -F “” ‘{}… END{}’ 資料來源
awk -F “” '{}… ’ 資料來源
BEGIN{}類似於MapReduce中的setup()函式,在{}之前執行且僅執行一次
END{}類似於MapReduce中的clean()函式,在{}之後執行且僅執行一次
awk案例
-
過濾(獲得使用者中使用者組id大於500的資訊)
cat /etc/passwd | awk -F “:” ‘{if($3>500)print $1,$2,$3}’
-
分段統計、百分比
資料
a 300 200 300
b 800 900 200
c 500 800 900
d 900 900 300命令
cat ./pc | awk -F “\t” ’
BEGIN{
ge0lt1000=0
ge1000lt1500=0
ge1500lt2000=0
ge2000=0
print “zone\tcount\tpercent”
}{
if(($2+$3+$4) < 1000){
ge0lt1000++
} else if(($2+$3+$4) < 1500){
ge1000lt1500++
} else if(($2+$3+$4) < 2000){
ge1500lt2000++
} else {
ge2000++
}
}END{
print “ge0lt1000”,ge0lt1000,ge0lt1000/NR100.0"%"
print “ge1000lt1500”,ge1000lt1500,ge1000lt1500/NR100.0"%"
print “ge1500lt2000”,ge1500lt2000,ge1500lt2000/NR100.0"%"
print “ge2000”,ge2000,ge2000/NR100.0"%"
}
’結果
zone count percent
ge0lt1000 1 25%
ge1000lt1500 0 0%
ge1500lt2000 1 25%
ge2000 2 50%
五、簡單的MapReduce案例
解析json字串
需求:
輸入資料:
{"add":"183.160.122.237|20171030080000015","ods":{"hed":"20171030075958865|011001103233576|60427fbe7d66,60427f8b733b|NewTV02SkyworthNews|192.168.1.6|4|6|60000185|3","dt":"20171030075958865|4|7,3404304,19458158,0,1,60000,0,2430|"}}
輸出:
183.160.122.237|20171030080000015 20171030075958865|011001103233576|60427fbe7d66,60427f8b733b|NewTV02SkyworthNews|192.168.1.6|4|6|60000185|3 20171030075958865|4|7,3404304,19458158,0,1,60000,0,2430|
程式碼:
import com.alibaba.fastjson.JSONObject;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Map;
public class JSONanalysis{
public static class MyMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
public static Text k = new Text();
public static FloatWritable v = new FloatWritable();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
Map<String, Object> map = JSONObject.parseObject(value.toString(), Map.class);
Map<String, String> ods = JSONObject.parseObject(map.get("ods").toString(), Map.class);
String result = map.get("add") + "\t" + ods.get("hed") + "\t" + ods.get("dt");
context.write(new Text(result), NullWritable.get());
}
}
public static class MyReducer extends Reducer<Text, NullWritable, Text, NullWritable>{
/*@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, null);
}*/
}
// 驅動
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1.獲取配置物件資訊
Configuration conf = new Configuration();
// 2.對conf進行設定(沒有就不用)
conf.set("fs.defaultFS", "hdfs://sz01:8020/");
// 3.獲取job物件
Job job = Job.getInstance(conf, "jsonanalysis");
// 4.設定job的執行主類
job.setJarByClass(JSONanalysis.class);
// 5.對map階段進行設定
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
setArgs(job, args);
// 7.提交job並列印資訊
int isok = job.waitForCompletion(true) ? 0 : 1;
// 退出整個job
System.exit(isok);
}
/**
* 作業引數處理
* @param job
* @param args
*/
public static void setArgs(Job job , String[] args){
try {
if(args.length != 2){
System.out.println("argments size is not enough!!!");
System.out.println("Useage :yarn jar *.jar wordcount /inputdata /outputdata");
}
//設定輸入檔案路徑
FileInputFormat.addInputPath(job, new Path(args[0]));
//判斷輸出目錄是否存在
FileSystem fs = FileSystem.get(job.getConfiguration());
System.out.println(fs);
Path op = new Path(args[1]);
if(fs.exists(op)){
fs.delete(op, true);
}
//設定輸出資料目錄
FileOutputFormat.setOutputPath(job, new Path(args[1]));
} catch (Exception e) {
e.printStackTrace();
}
}
}
多檔案輸出
需求
資料:
hello qianfeng qianfeng world heloo
Hello Hi Hello World
QF QQ
163.com
15900001111 17900001111
@163.com
@189.com
$1100000
*[a-z]
輸出:
part-r-00000
hello 1
heloo 1
qianfeng 2
world 1
part-r-00001
Hello 2
Hi 1
QF 1
QQ 1
part-r-00002
163.com 1
15900001111 1
17900001111 1
part-r-00003
@163.com 1
@189.com 1
$1100000 1
*[a-z] 1
程式碼:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Partition {
public static class MyMapper extends Mapper<LongWritable, Text, Text, Text>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
for (String s : words){
context.write(new Text(s), new Text(1 + ""));
}
}
}
public static class MyReducer extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
int count = 0;
for(Text t : values){
count += Integer.parseInt(t.toString());
}
context.write(key, new Text(count + ""));
}
}
public static class MyPartitioner extends Partitioner<Text, Text>{
@Override
public int getPartition(Text key, Text value, int numPartitions) {
String firstChar = key.toString().substring(0, 1);
if(firstChar.matches("^[a-z]")) {
return 0;
}else if(firstChar.matches("^[A-Z]")) {
return 1;
}else if(firstChar.matches("^[0-9]")) {
return 2;
}else {
return 3;
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1.獲取配置物件資訊
Configuration conf = new Configuration();
// 2.對conf進行設定(沒有就不用)
conf.set("fs.defaultFS", "hdfs://sz01:8020/");
// 3.獲取job物件
Job job = Job.getInstance(conf, "jsonanalysis");
// 4.設定job的執行主類
job.setJarByClass(Partition.class);
// 5.對map階段進行設定
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 設定分割槽
job.setPartitionerClass(MyPartitioner.class);
job.setNumReduceTasks(4);
// 6.對reduce階段設定
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
setArgs(job, args);
// 7.提交job並列印資訊
int isok = job.waitForCompletion(true) ? 0 : 1;
// 退出整個job
System.exit(isok);
}
/**
* 作業引數處理
* @param job
* @param args
*/
public static void setArgs(Job job , String[] args){
try {
if(args.length != 2){
System.out.println("argments size is not enough!!!");
System.out.println("Useage :yarn jar *.jar wordcount /inputdata /outputdata");
}
//設定輸入檔案路徑
FileInputFormat.addInputPath(job, new Path(args[0]));
//判斷輸出目錄是否存在
FileSystem fs = FileSystem.get(job.getConfiguration());
Path op = new Path(args[1]);
if(fs.exists(op)){
fs.delete(op, true);
}
//設定輸出資料目錄
FileOutputFormat.setOutputPath(job, new Path(args[1]));
} catch (Exception e) {
e.printStackTrace();
}
}
}
倒序索引
需求:
資料:
index.html
hadoop hadoop hadoop is nice is good hadoop hadoop
hadoop-info.html
hadoop hadoop hadoop is better
spark-info.html
spark spark spark hadoop is nice nice nice
輸出資料:
better hadoop-info.html:1
good hadoop-info.html:1
hadoop index.html:5;hadoop-info.html:3;spark-info.html:1
....
spark spark-info.html:3
程式碼:
DescIndex.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class DescIndex {
public static class MyMapper extends Mapper<LongWritable, Text, Text, Text>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
InputSplit is = context.getInputSplit();
String fileName = ((FileSplit)is).getPath().getName();
String line = value.toString();
String[] words = line.split(" ");
for (String s : words) {
context.write(new Text(s + "_" + fileName), new Text(1 + ""));
}
}
}
public static class MyReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void setup(Context context) throws IOException, InterruptedException {
}
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String str = "";
for (Text t : values) {
str += t.toString() + ";";
}
context.write(key, new Text(str.substring(0, str.length() - 1)));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1.獲取配置物件資訊
Configuration conf = new Configuration();
// 2.對conf進行設定(沒有就不用)
conf.set("fs.defaultFS", "hdfs://sz01:8020/");
// 3.獲取job物件
Job job = Job.getInstance(conf, "descindex");
// 4.設定job的執行主類
job.setJarByClass(DescIndex.class);
// 5.對map階段進行設定
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 設定combiner
job.setCombinerClass(MyCombiner.class);
// 6.對reduce階段設定
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
setArgs(job, args);
// 7.提交job並列印資訊
int isok = job.waitForCompletion(true) ? 0 : 1;
// 退出整個job
System.exit(isok);
}
/**
* 作業引數處理
* @param job
* @param args
*/
public static void setArgs(Job job , String[] args){
try {
if(args.length != 2){
System.out.println("argments size is not enough!!!");
System.out.println("Useage :yarn jar *.jar wordcount /inputdata /outputdata");
}
//設定輸入檔案路徑
FileInputFormat.addInputPath(job, new Path(args[0]));
//判斷輸出目錄是否存在
FileSystem fs = FileSystem.get(job.getConfiguration());
Path op = new Path(args[1]);
if(fs.exists(op)){
fs.delete(op, true);
}
//設定輸出資料目錄
FileOutputFormat.setOutputPath(job, new Path(args[1]));
} catch (Exception e) {
e.printStackTrace();
}
}
}
MyCombiner.java:
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.*;
public class MyCombiner extends Reducer<Text, Text, Text, Text> {
Map<Text, Integer> reduceMap = new HashMap<>();
ValueComparator bvc = new ValueComparator(reduceMap);
TreeMap<Text, Integer> sorted_map = new TreeMap<>(bvc);
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String[] str = key.toString().split("_");
int counter = 0;
for (Text t : values) {
counter += Integer.parseInt(t.toString());
}
//context.write(new Text(str[0]), new Text(str[1] + ":" + counter));
sorted_map.put(new Text(str[0] + "_" + str[1]), counter);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
System.out.println(reduceMap);
for(Text in : reduceMap.keySet()){
context.write(new Text(in.toString().split("_")[0]), new Text(in.toString().split("_")[1] + reduceMap.get(in)));
}
}
}
去重
需求:
2017-11-28 北京-天津
2017-11-29 北京-天津
2017-11-27 北京-天津
2017-11-27 北京-天津
2017-11-28 北京-天津
2017-11-26 北京-天津
2017-11-26 北京-哈爾濱
2017-11-29 北京-天津
2017-11-26 北京-三亞
輸出:
2017-11-28 北京-天津
2017-11-29 北京-天津
2017-11-27 北京-天津
2017-11-26 北京-天津
2017-11-26 北京-哈爾濱
2017-11-26 北京-三亞
程式碼:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 去重
*/
public class Distinct {
public static class MyMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
context.write(new Text(line),NullWritable.get());
}
}
public static class MyReducer extends Reducer<Text, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
// 驅動
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1.獲取配置物件資訊
Configuration conf = new Configuration();
// 2.對conf進行設定(沒有就不用)
conf.set("fs.defaultFS", "hdfs://sz01:8020/");
// 3.獲取job物件
Job job = Job.getInstance(conf, "distinct");
// 4.設定job的執行主類
job.setJarByClass(Distinct.class);
// 5.對map階段進行設定
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
// 6.對reduce階段設定
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
setArgs(job, args);
// 7.提交job並列印資訊
int isok = job.waitForCompletion(true) ? 0 : 1;
// 退出整個job
System.exit(isok);
}
/**
* 作業引數處理
* @param job
* @param args
*/
public static void setArgs(Job job , String[] args){
try {
if(args.length != 2){
System.out.println("argments size is not enough!!!");
System.out.println("Useage :yarn jar *.jar wordcount /inputdata /outputdata");
}
//設定輸入檔案路徑
FileInputFormat.addInputPath(job, new Path(args[0]));
//判斷輸出目錄是否存在
FileSystem fs = FileSystem.get(job.getConfiguration());
System.out.println(fs);
Path op = new Path(args[1]);
if(fs.exists(op)){
fs.delete(op, true);
}
//設定輸出資料目錄
FileOutputFormat.setOutputPath(job, new Path(args[1]));
} catch (Exception e) {
e.printStackTrace();
}
}
}