
使用Python讀寫處理Excel表格
引
由於需要解決大批量Excel處理的事情,與其手工操作還不如寫個簡單的程式碼來處理,大致選了一下感覺還是Python最容易操作。
安裝庫
Python環境
首先當然是配環境,不過選Python的一個重要原因就是Mac內是自帶Python環境的,不需要額外的配置環境,省下了一筆工作,如果你用的是Windows系統,那就還需要配置一下Python的環境了,我Mac的Python版本是2.7。
第三方庫
Python自己是不支援直接操作Excel的,但是Python強大之處就在於有大量好用的第三方庫,這裡我們選用讀Excel的xlrd庫和寫Excel的xlwt庫來操作。
關於第三方庫的安裝很簡單,首先,去專門下載Python庫的網站下載兩個庫的原始碼:
*
* 下載xlwt
注意對於新手來說最簡單的安裝方式就是原始碼安裝,不需要去折騰第三方庫的管理器,直接點選這個先下載兩個庫的原始碼:


你看他後面也描述了型別是原始碼嘛。
下載好之後在mac中解壓,得到資料夾,可以看到裡面都是有一個 setup.py 檔案的:
這裡當然不是直接雙擊安裝了,py型別表示它是一個Python程式碼檔案,雙擊只會開啟檔案看程式碼。我們要使用終端,輸入命令號進入當前所在的資料夾,比如我把檔案放在了“下載”中,那麼做法是:
$ cd Downloads/
$ cd xlwt-1.1.2
$ sudo python setup.py install- 1
- 2
- 3
這裡 cd 的意思是進入該資料夾,sudo 的意思是使用管理員許可權安裝,不使用的話會告訴你沒有許可權的,回車後會要你輸入電腦密碼,輸入後回車即可,python 是執行 python程式碼檔案的命令,install 就是安裝了。
然後會看到刷刷刷一堆文字過去,最後告訴你 finished 了,就是安裝完成了。
xlrd 也是同樣的安裝方式。
寫程式碼
讀寫Excel的第三方庫都安裝好了,就可以開始寫程式碼了。
我們在一個資料夾下建立一個 hello.py 檔案,然後用sublime之類的文件編輯器開啟它,開始編寫程式碼。(PS:Python中 # 號開頭表示註釋)
讀Excel
# -*- coding: utf-8 -*-
import xdrlib ,sys
import xlrd
#開啟excel檔案
def open_excel(file= 'test.xlsx'):
try:
data = xlrd.open_workbook(file)
return - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
這個程式碼很多我都註釋了,只講幾個要注意的地方,首先最開始我們設定了utp8編碼,然後一定要記得匯入xlrd包,這樣才能使用它的函式去讀取excel。裡面的 main() 是主函式,python 會執行這個函式,這個函式呼叫了其餘的函式來讀取資料。這個程式碼實現的是將excel檔案 test.xlsx 中的 Sheet1 表中的資料一行行讀取出來並列印。
Excel中內容如下:

有兩行內容。
要執行這個程式碼,需要用終端使用命令列,首先 cd 進入到程式碼所在的資料夾,程式碼和Excel檔案都要放在這個資料夾裡。然後使用 python hello.py 命令來執行這個程式碼檔案:
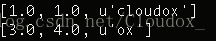
以上就是 Python 讀取並打印出來的內容,u 表示使用的是unicode編碼,可以看到與Excel中是一致的。
建立Excel
使用xlwt庫我們可以建立一個Excel:
# -*- coding: utf-8 -*-
import xlwt
def testXlwt(file = 'new.xls'):
book = xlwt.Workbook() #建立一個Excel
sheet1 = book.add_sheet('hello') #在其中建立一個名為hello的sheet
sheet1.write(0,0,'cloudox') #往sheet裡第一行第一列寫一個數據
sheet1.write(1,0,'ox') #往sheet裡第二行第一列寫一個數據
book.save(file) #建立儲存檔案
#主函式
def main():
testXlwt()
if __name__=="__main__":
main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
這個程式碼更簡單,同樣記得要在開頭匯入庫。
程式碼中我們建立了一個excel,在其中新增一個sheet,寫入兩個資料,最後按照我們的命名儲存了檔案。
按照上面同樣的方法執行程式碼後,終端中不會有列印的內容,但是我們去資料夾中看會得到一個名為 new.xls 的新excel檔案,開啟可以看到:
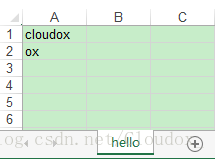
按照我們的方法寫了資料,同時sheet名字也是hello。
值得注意的是,在xlwt庫的說明中有這麼一句話:
Library to create spreadsheet files compatible with MS Excel 97/2000/XP/2003 XLS files, on any platform, with Python 2.6, 2.6, 3.3+
也就是說,它只能建立 xls 的檔案格式,不能建立現在的 xlsx 格式,其實有點老了,如果你把檔名寫了 xlsx 格式,將會無法開啟。
處理Excel內容
其實單獨的讀和寫只是基本功,我們最終是想要處理Excel中的內容的。
這裡我們假設一個使用場景,我們希望將Excel中所有第一列和第二列相同的行資料篩選出來儲存到一個新的Excel中去。
那麼我們的流程是:
- 開啟目標Excel
- 讀取內容
- 讀取每一行的同時篩選第一列和第二列相等的行保留下來
- 建立一個新Excel
- 將篩選出來的內容寫進去
- 儲存新Excel
那麼我們看程式碼:
# -*- coding: utf-8 -*-
import xdrlib ,sys
import xlrd
import xlwt
#開啟excel檔案
def open_excel(file= 'test.xlsx'):
try:
data = xlrd.open_workbook(file)
return data
except Exception,e:
print str(e)
#根據索引獲取Excel表格中的資料 引數:file:Excel檔案路徑 colnameindex:表頭列名所在行的索引 ,by_index:表的索引
def excel_table_byindex(file= 'test.xlsx',colnameindex=0,by_index=0):
data = open_excel(file) #開啟excel檔案
table = data.sheets()[by_index] #根據sheet序號來獲取excel中的sheet
nrows = table.nrows #行數
ncols = table.ncols #列數
colnames = table.row_values(colnameindex) #某一行資料
list =[] #裝讀取結果的序列
for rownum in range(0,nrows): #遍歷每一行的內容
row = table.row_values(rownum) #根據行號獲取行
if row: #如果行存在
app = [] #一行的內容
for i in range(len(colnames)): #一列列地讀取行的內容
app.append(row[i])
if app[0] == app[1] : #如果這一行的第一個和第二個資料相同才將其裝載到最終的list中
list.append(app)
testXlwt('new.xls', list) #呼叫寫函式,講list內容寫到一個新檔案中
return list
#將list中的內容寫入一個新的file檔案
def testXlwt(file = 'new.xls', list = []):
book = xlwt.Workbook() #建立一個Excel
sheet1 = book.add_sheet('hello') #在其中建立一個名為hello的sheet
i = 0 #行序號
for app in list : #遍歷list每一行
j = 0 #列序號
for x in app : #遍歷該行中的每個內容(也就是每一列的)
sheet1.write(i, j, x) #在新sheet中的第i行第j列寫入讀取到的x值
j = j+1 #列號遞增
i = i+1 #行號遞增
# sheet1.write(0,0,'cloudox') #往sheet裡第一行第一列寫一個數據
# sheet1.write(1,0,'ox') #往sheet裡第二行第一列寫一個數據
book.save(file) #建立儲存檔案
#主函式
def main():
tables = excel_table_byindex()
for row in tables:
print row
if __name__=="__main__":
main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
這次我們開頭要匯入xlrd和xlwt兩個庫,因為既要讀也要寫。
程式碼內容基本與上面兩個差不多,有一點點加深,在讀取的時候我們判斷了第一列和第二列資料相同的行才加到list中去。在寫的時候我們用了兩個for迴圈來對新excel中的一個個單元格寫資料,使用了i和j兩個變數來記錄位置。此外在獲取sheet的時候,與上面的不同,這裡是通過sheet的序號(這裡是0)來獲取的,上面的是通過sheet名稱來獲取。
我們要處理的Excel中的內容是這樣的:
按道理我們篩選後只應該保留第一行的內容,執行完後我們得到了一個新的Excel檔案,裡面的內容如下:

可以看到和預期是相符的。
結
這裡只是簡單的例子,兩個庫的操作還有很多,能夠進行的處理也有很多,如果要處理大量資料,可能還要考慮記憶體,分批次來處理,總之,本文只是一個入門,儘量追求零基礎也能學著使用來解放勞動力,更多的用法,就看自己琢磨了。