
第二章:基於IK的智慧分詞、細粒度分詞、同義詞、停用詞
阿新 • • 發佈:2019-01-02
2. 將檔案放入solr.war的WEB-INF/lib下
3. 將IKAnalyzer.cfg.xml、ext.dic、stopword.dic放到WEB-INF/classes目錄下,注意:classes目錄沒有,需要手動建立
4. 配置同義詞與停用詞
5. 配置schema.xml<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 擴充套件配置</comment> <!--使用者可以在這裡配置自己的擴充套件字典--> <entry key="ext_dict">ext.dic;</entry> <!--使用者可以在這裡配置自己的擴充套件停止詞字典--> <entry key="ext_stopwords">stopword.dic;</entry> </properties>
注意:isMaxWordLength為true表示進行智慧分詞,相反為細粒度分詞 6. 測試,搜尋關鍵詞“一臺筆記本” ext.dic檔案內容<fieldType name="text_ik" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="org.wltea.analyzer.lucene.IKAnalyzerSolrFactory" isMaxWordLength="false"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.wltea.analyzer.lucene.IKAnalyzerSolrFactory" isMaxWordLength="true"/> <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
一臺
筆記本stopword.dic檔案內容
的synonyms.txt檔案內容
筆記本 => 膝上型電腦 超薄筆記本7. 使用solr admin進行測試,搜尋關鍵詞“一臺筆記本”
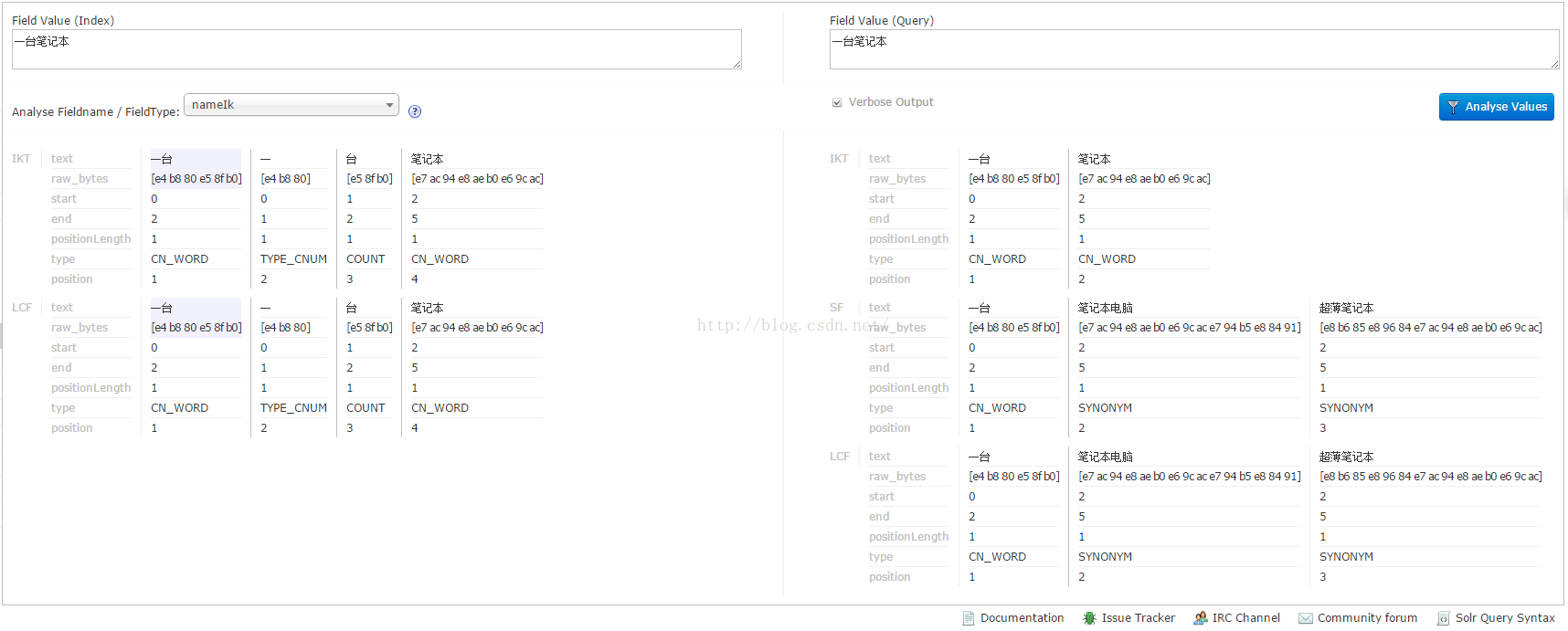
ST:使用StandardTokenizer解析的結果
LCF:使用LowercaseFilter解析的結果
參考資料:
http://blog.csdn.net/clj198606061111/article/details/21289897
http://onlyonetoone.iteye.com/blog/2155740