
【機器學習】Tensorflow:理解和實現快速風格化影象fast neural style
Neural Style開闢了計算機與藝術的道路,可以將照片風格化為名家大師的畫風。然而這種方法即使使用GPU也要花上幾十分鐘。Fast Neural Style則啟用另外一種思路來快速構建風格化影象,在筆記本CPU上十幾秒就可以風格化一張圖片。我們來看看這是什麼原理。
傳統的Neural Style基於VGG構建了一個最優化模型。它將待風格化圖片和風格化樣本圖放入VGG中進行前向運算。其中待風格化影象提取relu4特徵圖,風格化樣本圖提取relu1,relu2,relu3,relu4,relu5的特徵圖。我們要把一個隨機噪聲初始化的影象變成目標風格化影象,將其放到VGG中計算得到特徵圖,然後分別計算內容損失和風格損失。內容損失函式為:
有了上面兩個損失函式,就可以構建感知損失函式:
Fast Neural Style則可以在普通膝上型電腦中十幾秒運算出一個風格化影象。在一些科普文中是這樣解釋:Neural Style每次風格化都重新訓練了一次生成過程,把這個過程提前做好,就可以加速風格化。我覺得這個說法有點奇怪,來看看原文流程圖:
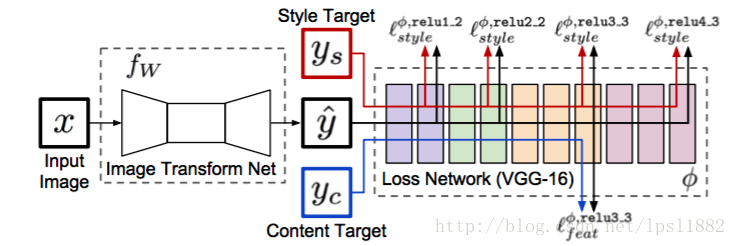
這個模型有兩個部分,後面一個loss network就是普通Neural Style的VGG網路,這裡只當做計算loss的網路,不進行訓練;前面一個Image Transform Network一般是一個deep residual CNN,即喜聞樂見的深度殘差網路,要訓練這個網路。然而,深度殘差網路的結構跟VGG是不同,訓練深度殘差網路不等於提前做好VGG生成過程。這裡的思想,我認為是一種生成-判別模型,有生成對抗網路GAN的影子:深度殘差網路-》生成模型,VGG-》判別模型。
下面的程式碼來自國人大神hzy46,我將預測部分的程式碼已經升級遷移到python3 tensorflow 1.0正式版:
def resize_conv2d(x, input_filters, output_filters, kernel, strides, training):
'''
An alternative to transposed convolution where we first resize, then convolve.
See http://distill.pub/2016/deconv-checkerboard/
For some reason the shape needs to be statically known for gradient propagation
through tf.image.resize_images, but we only know that for fixed image size, so we
plumb through a "training" argument
'''
with tf.variable_scope('conv_transpose') as scope:
height = x.get_shape()[1].value if training else tf.shape(x)[1]
width = x.get_shape()[2].value if training else tf.shape(x)[2]
new_height = height * strides * 2
new_width = width * strides * 2
x_resized = tf.image.resize_images(x, [new_height, new_width], tf.image.ResizeMethod.NEAREST_NEIGHBOR)
return conv2d(x_resized, input_filters, output_filters, kernel, strides)
def residual(x, filters, kernel, strides):
with tf.variable_scope('residual') as scope:
conv1 = conv2d(x, filters, filters, kernel, strides)
conv2 = conv2d(tf.nn.relu(conv1), filters, filters, kernel, strides)
residual = x + conv2
return residual
def instance_norm(x):
epsilon = 1e-9
mean, var = tf.nn.moments(x, [1, 2], keep_dims=True)
return tf.div(tf.subtract(x, mean), tf.sqrt(tf.add(var, epsilon)))
with tf.variable_scope('conv1'):
conv1 = tf.nn.relu(instance_norm(conv2d(image, 3, 32, 9, 1)))
with tf.variable_scope('conv2'):
conv2 = tf.nn.relu(instance_norm(conv2d(conv1, 32, 64, 3, 2)))
with tf.variable_scope('conv3'):
conv3 = tf.nn.relu(instance_norm(conv2d(conv2, 64, 128, 3, 2)))
with tf.variable_scope('res1'):
res1 = residual(conv3, 128, 3, 1)
with tf.variable_scope('res2'):
res2 = residual(res1, 128, 3, 1)
with tf.variable_scope('res3'):
res3 = residual(res2, 128, 3, 1)
with tf.variable_scope('res4'):
res4 = residual(res3, 128, 3, 1)
with tf.variable_scope('res5'):
res5 = residual(res4, 128, 3, 1)
with tf.variable_scope('deconv1'):
deconv1 = tf.nn.relu(instance_norm(resize_conv2d(res5, 128, 64, 3, 2, training)))
with tf.variable_scope('deconv2'):
deconv2 = tf.nn.relu(instance_norm(resize_conv2d(deconv1, 64, 32, 3, 2, training)))
with tf.variable_scope('deconv3'):
deconv3 = tf.nn.tanh(instance_norm(conv2d(deconv2, 32, 3, 9, 1)))
y = (deconv3 + 1) * 127.5明顯可以看到這裡用了反轉卷積conv2d_transpose,可以用resize_conv2d代替,也就是先放大影象然後卷積,數學意義相同,工程效果比直接conv2d_transpose要好,這是生成模型的標配啊!整個模型中,深度殘差網路不斷從原圖生成目標風格化影象,然後VGG不斷反饋深度殘差網路存在的問題,從而不斷優化生成網路,直到生成網路生成標準的風格化影象。最後要投入使用的時候,後面VGG判別網路根本不需要,只需要前面的深度殘差生成網路,就像GAN一樣。
Fast Neural Style的優點有:
- 生成速度快。
- 訓練好的模型檔案不大,載入簡單。不需要VGG網路,那個tensorflow model有500MB。
缺點有:
- 訓練速度很慢。官方推薦用coco資料集訓練深度殘差網路,這個資料集小的也有13GB,執行要幾十個小時。
- 一個生成網路只能生成一種風格化影象。我們訓練生成網路,使用的風格化影象只能用一種。
由於訓練的太慢,我就直接用hzy46大神的訓練好的model。經過訓練後的影象:
INFO:tensorflow:Elapsed time: 1.455744s
你們看,2015 macbook pro低配版上只要1.5秒鐘就完成了這個252x252的影象的風格化。
https://github.com/artzers/MachineLearning/tree/master/Tensorflow/fast-neural-style