
CUDA從入門到精通(七):流並行
前面我們沒有講程式的結構,我想有些童鞋可能迫不及待想知道CUDA程式到底是怎麼一個執行過程。好的,這一節在介紹流之前,先把CUDA程式結構簡要說一下。
CUDA程式檔案字尾為.cu,有些編譯器可能不認識這個字尾的檔案,我們可以在VS2008的Tools->Options->Text Editor->File Extension裡新增cu字尾到VC++中,如下圖:
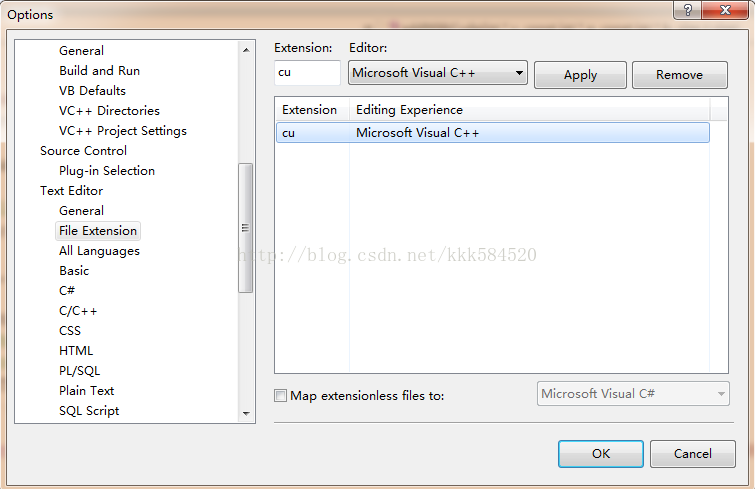
一個.cu檔案內既包含CPU程式(稱為主機程式),也包含GPU程式(稱為裝置程式)。如何區分主機程式和裝置程式?根據宣告,凡是掛有“__global__”或者“__device__”字首的函式,都是在GPU上執行的裝置程式,不同的是__global__裝置程式可被主機程式呼叫,而__device__裝置程式則只能被裝置程式呼叫。
沒有掛任何字首的函式,都是主機程式。主機程式顯示宣告可以用__host__字首。裝置程式需要由NVCC進行編譯,而主機程式只需要由主機編譯器(如VS2008中的cl.exe,Linux上的GCC)。主機程式主要完成裝置環境初始化,資料傳輸等必備過程,裝置程式只負責計算。
主機程式中,有一些“cuda”打頭的函式,這些都是CUDA Runtime API,即執行時函式,主要負責完成裝置的初始化、記憶體分配、記憶體拷貝等任務。我們前面第三節用到的函式cudaGetDeviceCount(),cudaGetDeviceProperties(),cudaSetDevice()都是執行時API。這些函式的具體引數宣告我們不必一一記下來,拿出第三節的官方利器就可以輕鬆查詢,讓我們開啟這個檔案:
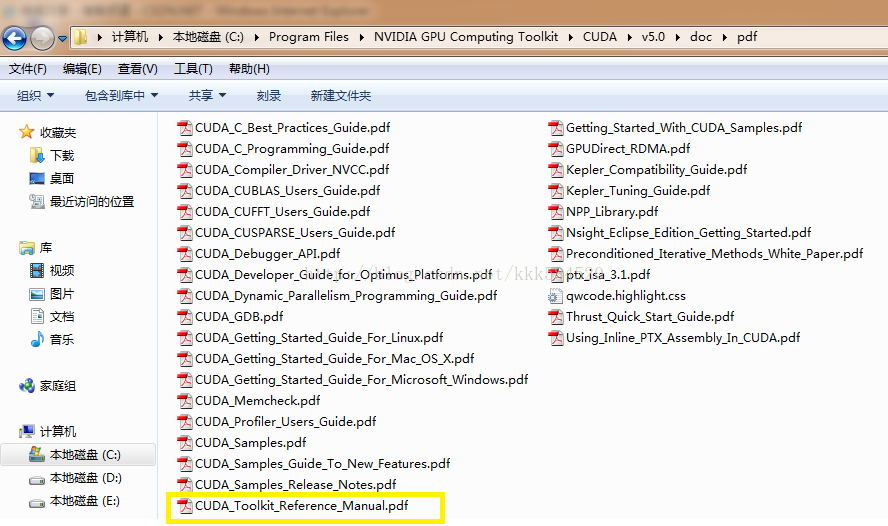
開啟後,在pdf搜尋欄中輸入一個執行時函式,例如cudaMemcpy,查到的結果如下:
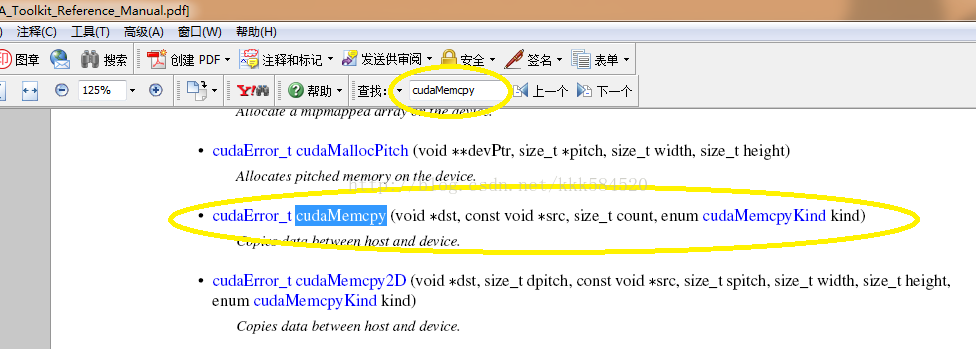
可以看到,該API函式的引數形式為,第一個表示目的地,第二個表示來源地,第三個引數表示位元組數,第四個表示型別。如果對型別不瞭解,直接點選超連結,得到詳細解釋如下:

可見,該API可以實現從主機到主機、主機到裝置、裝置到主機、裝置到裝置的記憶體拷貝過程。同時可以發現,利用該API手冊可以很方便地查詢我們需要用的這些API函式,所以以後編CUDA程式一定要把它開啟,隨時準備查詢,這樣可以大大提高程式設計效率。
好了,進入今天的主題:流並行。
前面已經介紹了執行緒並行和塊並行,知道了執行緒並行為細粒度的並行,而塊並行為粗粒度的並行,同時也知道了CUDA的執行緒組織情況,即Grid-Block-Thread結構。一組執行緒並行處理可以組織為一個block,而一組block並行處理可以組織為一個Grid,很自然地想到,Grid只是一個網格,我們是否可以利用多個網格來完成並行處理呢?答案就是利用流。
流可以實現在一個裝置上執行多個核函式。前面的塊並行也好,執行緒並行也好,執行的核函式都是相同的(程式碼一樣,傳遞引數也一樣)。而流並行,可以執行不同的核函式,也可以實現對同一個核函式傳遞不同的引數,實現任務級別的並行。
CUDA中的流用cudaStream_t型別實現,用到的API有以下幾個:cudaStreamCreate(cudaStream_t * s)用於建立流,cudaStreamDestroy(cudaStream_t s)用於銷燬流,cudaStreamSynchronize()用於單個流同步,cudaDeviceSynchronize()用於整個裝置上的所有流同步,cudaStreamQuery()用於查詢一個流的任務是否已經完成。具體的含義可以查詢API手冊。
下面我們將前面的兩個例子中的任務改用流實現,仍然是{1,2,3,4,5}+{10,20,30,40,50} = {11,22,33,44,55}這個例子。程式碼如下:
[cpp] view plain copy print?- #include "cuda_runtime.h"
- #include "device_launch_parameters.h"
- #include <stdio.h>
- cudaError_t addWithCuda(int *c, constint *a, constint *b, size_t size);
- __global__ void addKernel(int *c, constint *a, constint *b)
- {
- int i = blockIdx.x;
- c[i] = a[i] + b[i];
- }
- int main()
- {
- constint arraySize = 5;
- constint a[arraySize] = { 1, 2, 3, 4, 5 };
- constint b[arraySize] = { 10, 20, 30, 40, 50 };
- int c[arraySize] = { 0 };
- // Add vectors in parallel.
- cudaError_t cudaStatus;
- int num = 0;
- cudaDeviceProp prop;
- cudaStatus = cudaGetDeviceCount(&num);
- for(int i = 0;i<num;i++)
- {
- cudaGetDeviceProperties(&prop,i);
- }
- cudaStatus = addWithCuda(c, a, b, arraySize);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "addWithCuda failed!");
- return 1;
- }
- printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",c[0],c[1],c[2],c[3],c[4]);
- // cudaThreadExit must be called before exiting in order for profiling and
- // tracing tools such as Nsight and Visual Profiler to show complete traces.
- cudaStatus = cudaThreadExit();
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaThreadExit failed!");
- return 1;
- }
- return 0;
- }
- // Helper function for using CUDA to add vectors in parallel.
- cudaError_t addWithCuda(int *c, constint *a, constint *b, size_t size)
- {
- int *dev_a = 0;
- int *dev_b = 0;
- int *dev_c = 0;
- cudaError_t cudaStatus;
- // Choose which GPU to run on, change this on a multi-GPU system.
- cudaStatus = cudaSetDevice(0);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
- goto Error;
- }
- // Allocate GPU buffers for three vectors (two input, one output) .
- cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- // Copy input vectors from host memory to GPU buffers.
- cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- <span style="BACKGROUND-COLOR: #ff6666"> cudaStream_t stream[5];
- for(int i = 0;i<5;i++)
- {
- cudaStreamCreate(&stream[i]); //建立流
- }
- </span> // Launch a kernel on the GPU with one thread for each element.
- <span style="BACKGROUND-COLOR: #ff6666"> for(int i = 0;i<5;i++)
- {
- addKernel<<<1,1,0,stream[i]>>>(dev_c+i, dev_a+i, dev_b+i); //執行流
- }
- cudaDeviceSynchronize();
- </span> // cudaThreadSynchronize waits for the kernel to finish, and returns
- // any errors encountered during the launch.
- cudaStatus = cudaThreadSynchronize();
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
- goto Error;
- }
- // Copy output vector from GPU buffer to host memory.
- cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
- if (cudaStatus != cudaSuccess)
- {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- Error:
- <span style="BACKGROUND-COLOR: #ff6666"> for(int i = 0;i<5;i++)
- {
- cudaStreamDestroy(stream[i]); //銷燬流
- }
- </span> cudaFree(dev_c);
- cudaFree(dev_a);
- cudaFree(dev_b);
- return cudaStatus;
- }
注意到,我們的核函式程式碼仍然和塊並行的版本一樣,只是在呼叫時做了改變,<<<>>>中的引數多了兩個,其中前兩個和塊並行、執行緒並行中的意義相同,仍然是執行緒塊數(這裡為1)、每個執行緒塊中執行緒數(這裡也是1)。第三個為0表示每個block用到的共享記憶體大小,這個我們後面再講;第四個為流物件,表示當前核函式在哪個流上執行。我們建立了5個流,每個流上都裝載了一個核函式,同時傳遞引數有些不同,也就是每個核函式作用的物件也不同。這樣就實現了任務級別的並行,當我們有幾個互不相關的任務時,可以寫多個核函式,資源允許的情況下,我們將這些核函式裝載到不同流上,然後執行,這樣可以實現更粗粒度的並行。
好了,流並行就這麼簡單,我們處理任務時,可以根據需要,選擇最適合的並行方式。