
sql 提升查詢效率 group by option hash group
問題:
一個程式查詢經常超過20siis限制時間,排查問題後發現其中的一個儲存過程時間會在15s左右
解決思路:
1:確認問題點
通過輸出時間的方式檢視儲存過程中每個部分的執行時間,找到最耗時的三個過程
2:解決問題
發現查詢過程中出現 with nolock ,對於查詢過程沒有用處,刪除
先思考是否建立索引,發現有一個重要查詢條件沒有索引,建立索引後查詢時間從8s秒降低到7秒
最後看到group by 會導致時間變長,加OPTION(hash group)減少group by 的影響
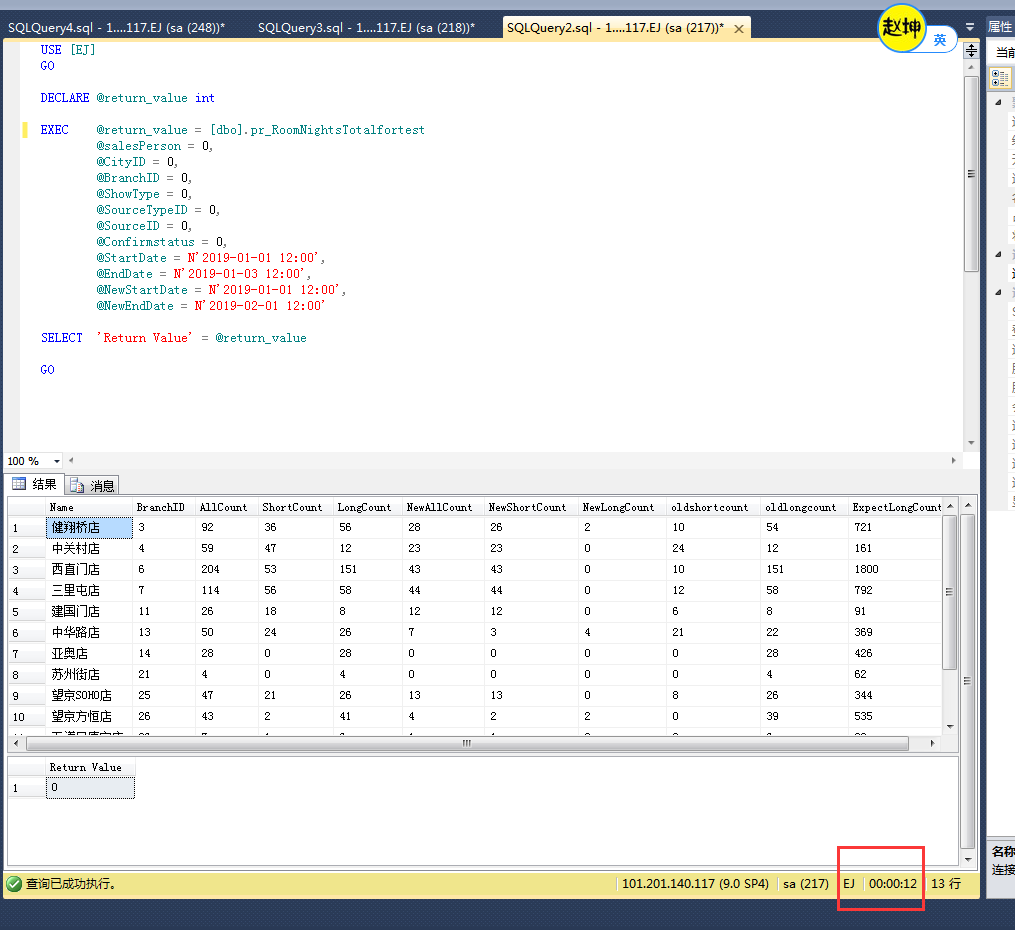

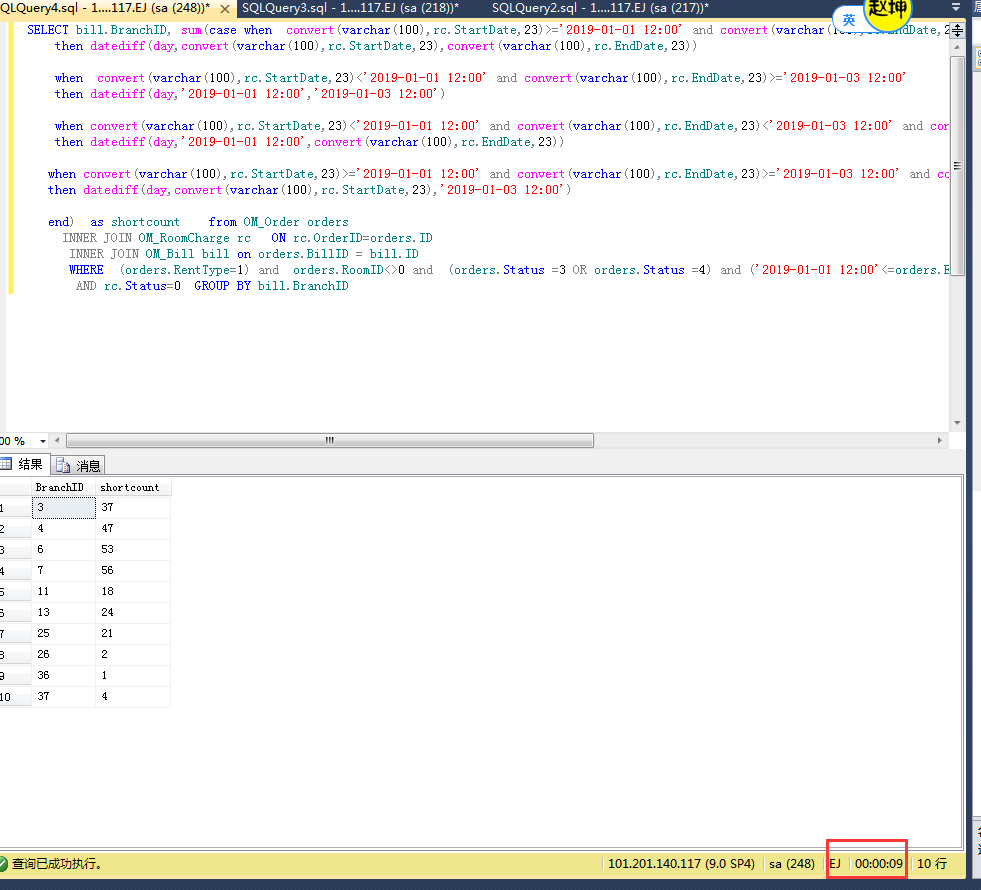
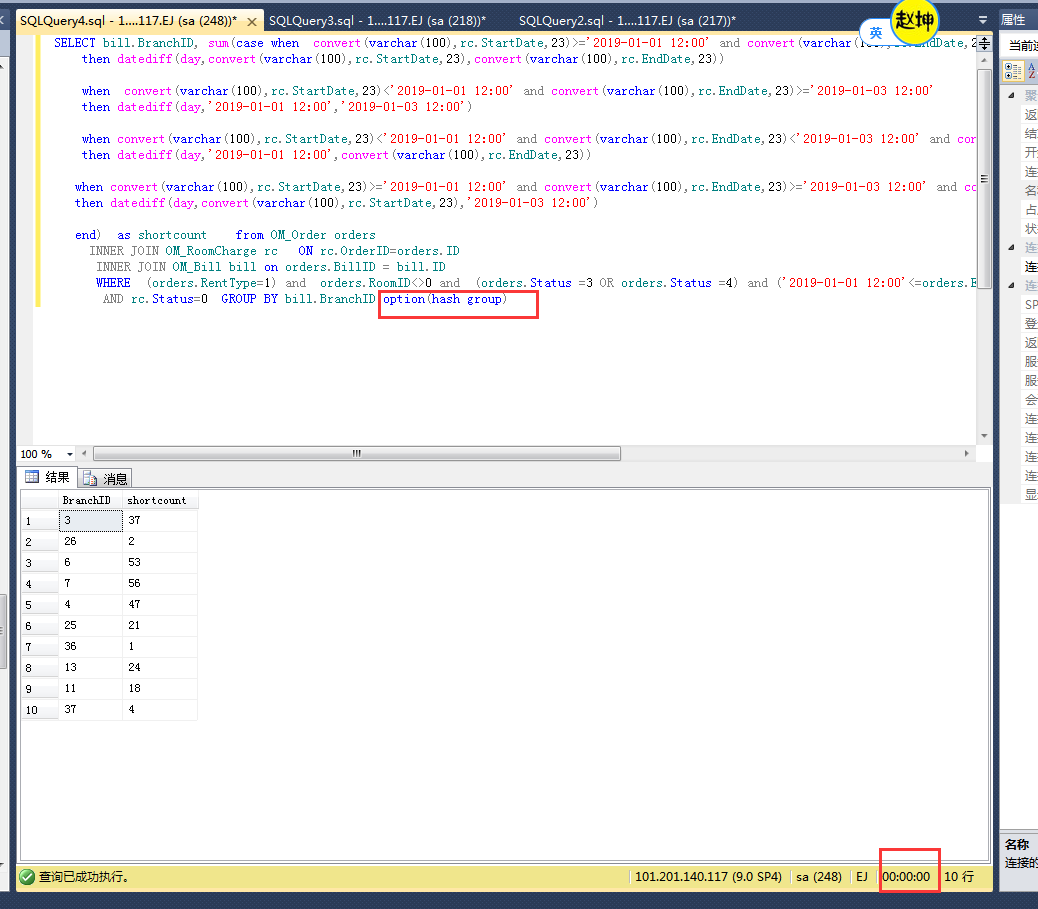
結果:最終單個查詢過程的時間從9S=》0S ,總查詢過程從15S=》1S
原理:
還在學習sql 中關於 option (hash group )的內容,學會了在分享原理吧。
相關推薦
sql 提升查詢效率 group by option hash group
問題: 一個程式查詢經常超過20siis限制時間,排查問題後發現其中的一個儲存過程時間會在15s左右 解決思路: 1:確認問題點 通過輸出時間的方式檢視儲存過程中每個部分的執行時間,找到最耗時的三個過程 2:解決問題 發現查詢過程中出現 with nolock ,對於查詢過程沒有用處,刪除 先思
SQL Server: 建立 XML 索引 提升查詢效率
Scenario: 最近在工作中遇到一個問題,客戶訪問公司產品的某報表功能時,速度極慢,在客戶環境甚至達到15+分鐘的頁面載入時間。經分析,問題的原因是多方面的,其中最主要的一項是產品資料庫(SQL Server)的一個核心欄位採用了XML型別儲存,先不討論其設計的優劣,但大
MySQL - 如何提高SQL的查詢效率(where條件優化)
目錄 說在前面 35條優化規則 總結 說在前面 整天說SQL優化,SQL優化,到底怎麼才算是SQL優化呢,下面從百度總結了一些關於Oracle裡常用的一些有效的優化方法。僅供參考,文章內容來源於網路。 35條優化規則 (1)優先考慮建立索引 對查詢進行優化,應
Oracle - 如何提高SQL的查詢效率(where條件優化)
目錄 說在前面 34條優化規則 總結 說在前面 整天說SQL優化,SQL優化,到底怎麼才算是SQL優化呢,下面從百度總結了一些關於Oracle裡常用的一些有效的優化方法。僅供參考,文章內容來源於網路。 34條優化規則 (1)選擇最有效率的表名順序(只在基於規則的優
mysql如何使用索引index提升查詢效率?
https://dev.mysql.com/doc/refman/8.0/en/mysql-indexes.html Indexes are used to find rows with specific column values quickly. Without an index, My
SQL重復記錄查詢-count與group by having結合查詢重復記錄
nbsp 根據 iteye sele rul 判斷 select pro .net 查找表中多余的重復記錄,重復記錄是根據單個字段(peopleId)來判斷select * from peoplewhere peopleId in (select peopleId fr
SQL group by分組查詢
create server insert 一定的 ID all 註意 至少 滿足 本文導讀:在實際SQL應用中,經常需要進行分組聚合,即將查詢對象按一定條件分組,然後對每一個組進行聚合分析。創建分組是通過GROUP BY子句實現的。與WHERE子句不同,GROUP BY
sql-多表查詢JOIN與分組GROUP BY
group 邊表 AS inner left join sdn AR full join ner 一、內部連接:兩個表的關系是平等的,可以從兩個表中獲取數據。用ON表示連接條件 SELECT A.a,B.b FROM At AS A INNER JOINT Bt AS B
SQL復雜查詢語句-SELECT * FROM cs WHERE score>70 GROUP BY s_id HAVING COUNT(*)>1
規範 des 刪除索引 表數 _id 需求 null rop 其他 如果同時存在where,group by,的時候的執行順序應該是這樣的: 1,首先where後面添加條件把數據進行了過濾,返回一個結果集 2,然後group by將上面返回的結果集進行分組,返回一個結果集
資料庫sql語句多表連線查詢+group by分組的使用
參考自:https://blog.csdn.net/fly_fly_fly_pig/article/details/81325116 平時用sql查詢經常遇到的問題,這次搜到了一個博主的文章,解決了問題。但是其中的深層原因還沒有想清楚,本文需要完善。 更正前 CREATE VIE
Mysql5.7.20使用group by查詢(select *)時出現錯誤--修改sql mode
Mysql5.7.20使用group by查詢(select *)時出現錯誤--修改sql mode 使用select * from 表 group by 欄位 時報錯 錯誤資訊說明: 1055 - Expression #1 of SELECT list
SQL查詢之 group by 中的坑
題目來源自, 牛客網資料庫實戰之獲取所有部門中當前員工薪水最高的相關資訊 給出dept_no, emp_no以及其對應的salary 初始化語句 CREATE TABLE `dept_emp` ( `emp_no` int(11) NOT NULL, `dept_no` char
SQL查詢語句where,group by,having,order by的執行順序和編寫順序
當一個查詢語句同時出現了where,group by,having,order by的時候,執行順序和編寫順序。 一、使用count(列名)當某列出現null值的時候,count(*)仍然會計算,但是count(列名)不會。 二、資料分組(group by ): sel
SQL Union和SQL Union All兩者用法區別效率以及與order by 和 group by配合問題
SQL UNION 操作符 UNION 操作符用於合併兩個或多個 SELECT 語句的結果集。 請注意,UNION 內部的 SELECT 語句必須擁有相同數量的列。列也必須擁有相似的資料型別。同時,每條 SELECT 語句中的列的順序必須相同。 SQL UNION
SQL入門筆記2——子查詢,JOIN,GROUP BY
一、SELECT 子查詢 例1.SQLZOO:SELECT within SELECT T7、在每一個州中找出最大面積的國家,列出洲份 continent, 國家名字 name 及面積 area。 (有
elasticsearch xpack sql group by 如何對時間按年月日進行分組查詢
ES從6.3開始已經支援SQL了,當然還有很多不完善的地方,比如對於巢狀查詢,連表查詢,但是對於單表而言,提供的SQL已經基本夠用了。 這裡只講一下我在實際業務中遇到的一個問題,運營那邊想要對時間進行分組查詢,可以按年或是月或是日進行分組,為了能滿足運營那邊的要求,自己研究
資料庫排名sql,group by 分組查詢按照時間最大值
先給出類似的簡單表 DROP TABLE IF EXISTS `TouTiaoAnchor`; CREATE TABLE `TouTiaoAnchor` ( `HourId` int(10) unsigned NOT NULL, `BetinTime` varcha
SQL Server溫故系列(5):SQL 查詢之分組查詢 GROUP BY
1、GROUP BY 與聚合函式 2、GROUP BY 與 HAVING 3、GROUP BY 擴充套件分組 3.1、GROUP BY ROLLUP 3.2、GROUP BY CUBE 3.3、GROUP BY GROUPING SETS 4、GROUP BY 擴充套件函式 4.1、GROUPING
記一次神奇的sql查詢經歷,group by慢查詢優化
一、問題背景 現網出現慢查詢,在500萬數量級的情況下,單表查詢速度在30多秒,需要對sql進行優化,sql如下: 我在測試環境構造了500萬條資料,模擬了這個慢查詢。 簡單來說,就是查詢一定條件下,都有哪些使用者的。很簡單的sql,可以看到,查詢耗時為37秒。 說一下app_account欄位
mybatis group by查詢返回map類型
macro fig link context hand out 取值 image 對象 故事的發生是這樣的. . . . . . . 一天 我發現我們的頁面顯示了這樣的匯總統計數據,看起來體驗還不錯哦~~ 然後,我發現代碼是這樣滴:分開每個狀態分別去查詢數量。 額e,可是