
AutoEncoder 及其相關模型
引言
AutoEncoder 是 Feedforward Neural Network 的一種,曾經主要用於資料的降維或者特徵的抽取,而現在也被擴充套件用於生成模型中。與其他 Feedforward NN 不同的是,其他 Feedforward NN 關注的是 Output Layer 和錯誤率,而 AutoEncoder 關注的是 Hidden Layer;其次,普通的 Feedforward NN 一般比較深,而 AutoEncoder 通常只有一層 Hidden Layer。
本篇文章會主要介紹傳統的 AutoEncoder 相關模型、以及生成模型 Variational AutoEncoder。為了方便講述,以下主要以單層 Hidden Layer 的 AutoEncoder 為例。
AutoEncoder
原始 AutoEncoder
原始的 AutoEncoder 結構很簡單:Input Layer、Hidden Layer、Output Layer。此網路的約束有:
- Hidden Layer 的維度要遠小於 Input Layer
- Output 用於重構 Input,也即讓誤差最小
於是,可以用 Hidden Layer 中神經元組成的向量(這裡我們稱為 Code)來表示 Input,就達到了對 Input 壓縮的效果。AutoEncoder 的訓練方式就是普通的 BP。其中,將 Input 壓縮為 Code 的部分稱為 encoder,將 Code 還原為 Input 的部分稱為 decoder。於是,AutoEncoder 的結構可以表示為
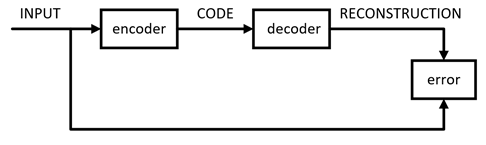
其數學表示式如下,其中、分別表示 encoder 和 decoder
可以看出,AutoEncoder 其實是增強的 PCA:AutoEncoder 具有非線性變換單元,因此學出來的 Code 可能更精煉,對 Input 的表達能力更強。
雖然用 AutoEncoder 來壓縮理論上看起來很智慧,但是實際上並不太好用:
- 由於 AutoEncoder 是訓練出來的,故它的壓縮能力僅適用於與訓練樣本相似的樣本
- AutoEncoder 還要求 encoder 和 decoder 的能力不能太強。極端情況下,它們有能力完全記憶住訓練樣本,那麼 Code 是什麼也就不重要了,更不用談壓縮能力了
下面再簡要介紹一些 AutoEncoder 的擴充套件。
Sparse AutoEncoder
Sparse 本身已經被研究了很多年了,比如曾輝煌一時的 Sparse Representation。Sparse AutoEncoder(SAE)其實就是對 AutoEncoder 的 Code 增加了稀疏的約束。而稀疏具有很多良好的性質,如:
- 有降維的效果,可以用於提取主要特徵
- 由於可以抓住主要特徵,故具有一定抗噪能力
- 稀疏的可解釋性好,現實場景大多滿足這種約束(如“奧卡姆剃刀定律”)
增加了稀疏約束後的 AutoEncoder 的損失函式定義如下:
其中,表示 KL散度,表示網路中神經元的期望啟用程度(若 Activation 為 Sigmoid 函式,此值可設為 0.05,表示大部分神經元未啟用),表示第個神經元的平均啟用程度。在此處,KL散度 定義如下
其中,定義為訓練樣本集上的平均啟用程度,公式如下。其中表示第個訓練樣本
Denoising AutoEncoder
Denoising AutoEncoder(DAE)是在“Vincent Extracting and composing robust features with denoising autoencoders, 2008”中提出的。本質就是在原樣本中增加噪聲,並期望利用 DAE 將加噪樣本來還原成純淨樣本。
在文章中,作者以影象為例,對影象中的畫素以一定概率遮擋,作為輸入。隨後利用 DAE 進行恢復。由於增加了噪聲,因此學習出來的 Code 會更加穩健。其次,論文中還從各種方面(流形、生成模型、資訊理論等等)對 DAE 進行了解釋。但是由於 DAE 應用不多,這裡就不展開了,有興趣的同學可以參考原文。
其他 AutoEncoder
除了上述的 AutoEncoder,為了學習出更加穩健,表達能力更強的 Code,還有其他的 AutoEncoder,如:
Contrative AutoEncoder(CAE),在文章"Contractive auto-encoders: Explicit invariance during feature extraction, 2011"中提出。其與 DAE 的區別就在於約束項進行了修改,意在學習出更加緊湊穩健的 Code。
Stacked AutoEncoder(SAE),在文章“Greedy Layer-Wise Training of Deep Networks, 2007”中提出。作者對單層 AutoEncoder 進行了擴充套件,提出了多層的 AutoEncoder,意在學習出對輸入更抽象、更具擴充套件性的 Code 的表達。
除此之外,還有將傳統 FNN 網路中的結構融入到 AutoEncoder 的,如:Convolutional Autoencoder、 Recursive Autoencoder、 LSTM Autoencoder 等等。
Autoencoder 期望利用樣本自適應學習出穩健、表達能力強、擴充套件能力強的 Code 的設想很好,但是實際中應用場景卻很有限。一般可以用於資料的降維、或者輔助進行資料的視覺化分析。有學者另闢蹊徑,借鑑了 Autoencoder 的思想,將其用於資料的生成,取得到驚人的效果,如下面會介紹的 Variational AutoEncoder。
Variational AutoEncoder
Variational AutoEncoder(VAE)是由 Kingma 和 Welling 在“Auto-Encoding Variational Bayes, 2014”中提出的一種生成模型。VAE 作為目前(2017)最流行的生成模型之一,可用於生成訓練樣本中沒有的樣本,讓人看到了 Deep Learning 強大的無監督學習能力。
如下圖這張廣為人知的“手寫數字生成圖”,就是由 VAE 產生的。

判別模型 與 生成模型
我們都知道一般有監督學習可以分為兩種模型:判別模型(DM,Discriminative Model)和生成模型(GM,Generative Model)。下面我們以分類問題為例,簡單回顧一下其概念。
對於分類問題,本質需要解決的其實就是最大化後驗概率,即
於是,可以衍生出兩種方案。第一種方法如下:
由於
原問題就轉化為了求和,這就是生成模型特點:需要直接或間接對建模。常見的生成模型有隱馬爾可夫模型(HMM)、樸素貝葉斯、高斯混合模型(GMM)等等。
形象一點地表達,即為了求樣本屬於每一類的概率,我們先求解每一類出現的概率;並對每一類分別建模,求出樣本在該類發生的概率。最後利用貝葉斯公式算出。
其二種方法即,我們可以直接對後驗建模,顯性或隱形地求出其表示式。對樣本,代入公式求解出每一類的後驗概率,取其中最大值即可。這就是判別模型。常見的判別模型有線性迴歸模型、支援向量機(SVM)、神經網路等等,
VAE
VAE 跟傳統 AutoEncoder 關係並不大,只是思想及架構上也有 Encoder 和 Decoder 兩個結構而已。跟 AutoEncoder 不同,VAE 理論跟實際效果都非常驚豔,理論上涉及到的主要背景知識也比較多,包括:隱變數(Latent Variable Models)、變分推理(Variational Inference)、Reparameterization Trick 等等。
由於涉及到的知識較多,本部分只會對 VAE 進行簡要介紹,省略很多證明。本部分講解思路參考論文"Tutorial on Variational Autoencoders"和部落格“Tutorial - What is a variational autoencoder? ”。
首先,先定義問題:我們希望學習出一個模型,能產生訓練樣本中沒有,但與訓練集相似的資料。換一種說法,對於樣本空間,當以抽取資料時,我們希望以較高概率抽取到與訓練樣本近似的資料。對於手寫數字的場景,則表現為生成像手寫數字的影象。
對於我們期望獲取的資料,其不同維度之間可能存在特定的聯絡。將這些聯絡對應的因素單獨抽取出來作為特徵,即隱變數(Latent Variables),寫作。則原來對建模轉為對進行建模,同時有
其中,是隱變數空間中的點,是模型引數空間中的點。此時可以分別對和建模,這就與上面提到的生成模型是一致的,因此 VAE 是無監督的生成模型。對於手寫數字的場景,隱變數可以理解成影象對應的真實數字、書寫的角度、筆尖寬度等等方面。
為了計算這個積分,首先需要給出的表達形式。在 VAE 中,作者選擇高斯分佈,即
其中,表示單位矩陣,為超引數。為將對映到的函式,即。
此時,還需要給出的表示式。不過,其中隱變數到底代表什麼(對應的數字、書寫的角度、筆尖寬度等等,難以人工窮舉),以及它們對應的表示式都是很難人工定義的。這裡,作者給出一個很巧妙的解決方法,即取,同時利用多層 DNN 來學習。當然,真實的隱變數不可能是簡單的。巧妙之處在於,由於任何維的分佈,都可以利用維的高斯分佈經過某種複雜函式變換得到。因此,對應的多層 DNN,前幾層負責將高斯分佈的對映到真正的隱變數,後幾層負責將這個隱變數對映到。
接下來我們可以開始解決最大化的問題,公式為
如果的數量較少,我們就可以利用取樣來計算積分,即
但若現在隱變數維度很大時,就會需要極大量的樣本,幾乎是不可能計算的。但是根據經驗可以得知,對大多數來說,,對估計沒有幫助。於是只需要取樣那些對有貢獻的。此時,就需要知道,但是這個無法直接求取。VAE 中利用 Variational Inference,引入來近似。
關於 Variational Inference,鑑於篇幅不會展開講,有需要了解的同學的請參考《PRML》第10章、《Deep Learning》第19章、以及其他教材。
最終,可以得到需要優化的目標 ELBO(Evidence Lower BOund),此處其定義為
其中,第一項是我們希望最大化的目標;第二項是在資料下真實分佈與假想分佈的距離,當的選擇合理時此項會接近為0。但公式中含有,無法直接求解,於是將其化簡後得到
上述公式中每一項的分佈如下。其中中引數和依然利用 DNN 來學習
由於兩個高斯分佈的 KL 距離可以直接計算,故當與中引數已知時(通過 DNN 學習),就能求解。當與很接近時,接近於0,優化此式就相當於在優化我們期望的目標。
概率視角講的差不多了,我們回到 DNN 視角。上述文章已經說明了我們需要最大化的目標是
於是,對於某個樣本,其損失函式可以表示為
其中,意味著將樣本編碼為隱變數,對應於 AutoEncoder 中的 Encoder;意味著將隱變數恢復成,對應著 Decoder。於是,的意義就可以這樣理解
第一項,表示隱變數對樣本的重構誤差,並在空間內取期望,即平均的重構誤差。我們的目標就是使誤差最小化
第二項,可以理解為正則項。其計算的是與真實的差異,表示我們用近似帶來的資訊損失。我們也希望這個資訊損失項儘可能的小
於是,VAE 的結構可以表示為
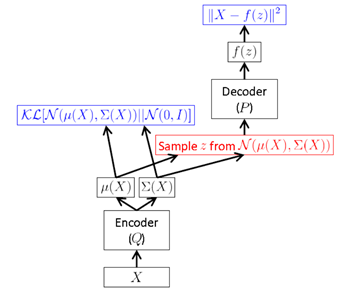
但是,上面這種方式需要在 FF 時進行取樣,而這種取樣操作是無法進行 BP 的。於是,作者提出一種“Reparameterization Trick”:將對取樣的操作移到輸入層進行。於是就有了下面的 VAE 最終形式
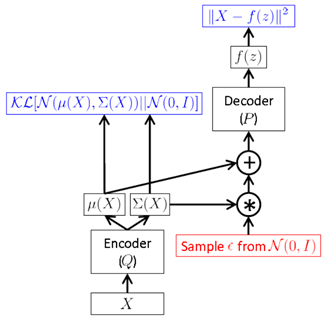
取樣時,先對輸入的進行取樣,然後計算間接對取樣。通過這種方式,就可以利用 BP 來優化損失函數了。
我們再結合兩個圖梳理一下 VAE 的過程。
下圖表示了 VAE 整個過程。即首先通過 Encoder 得到的隱變數分佈引數;然後取樣得到隱變數。接下來按公式,應該是利用 Decoder 求得的分佈引數,而實際中一般就直接利用隱變數恢復。

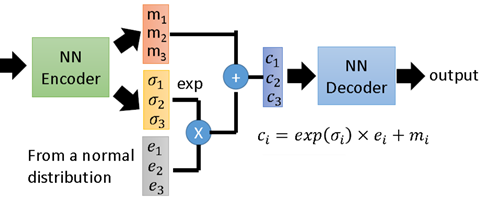
下圖展示了一個具有3個隱變數的 VAE 結構示意圖,是對上面抽象描述的一個補充說明,不再贅述。
尾巴
前幾周由於個人原因無暇他顧,使本篇拖更良久。近期更新可能仍會比較緩慢,但我還是會保持更新,畢竟值得寫的東西太多太多。
最後關於 VAE 部分,限於個人水平、VAE 的難度、篇幅等,本篇未能完全做到足夠清晰明瞭,其中省略了不少的證明及推理過程。有需要深入研究的同學建議看完本篇後,再深入閱讀下文中提到的 Paper,才能對 VAE 有更系統的理解。
Reference:
- 變分自編碼器(VAEs):在對 VAE 結構和原理有大致瞭解後,對背後的推導有興趣的同學可以參考此部落格