
精通Java8新特性Lambdas、Streams、Interface default methods
Java SE 8 是有史以來對 Java 語言和庫改變最大的一次,其新特性增加了函數語言程式設計風格的Lambda表示式。雖然一開始 lambda 表示式似乎只是“另一個語言特性”而已,但實際上,它們會改變你思考程式設計的方式。Java中的繼承和泛型在很大程度上是關於資料抽象的。而Lambda表示式則提供了用於對行為進行抽象的更棒的工具來彌補這一點.
引入Lambdas動機是需要更好的程式設計模型以及讓 Java 開始為多核處理器提供支援。
將新特性Stream整合到現有的 Java 平臺庫中,需要對已有的集合介面進行演化,而之前由於相容性問題這一點是沒法實現的,所以通過介面的預設方法的引入來解決這些問題。
1.Lambda表示式 Lambda Expression
eg1. 對集合中每個 Point 沿著 x 與 y 軸各平移 1 個單位的距離。
Java8之前最常見的迭代實現方式(外部迭代):
List<Point> pointList = Arrays.asList(new Point(1, 2), newPoint(2, 3));
for (Point p : pointList) {
p.translate(1, 1);
}
//或者 Java5之前
for (Iterator pointItr = pointList.iterator();pointItr.hasNext(); ) {
((Point) pointItr.next()).translate(1, 1);
} 而在Java8中可以用lambda表示式實現(內部迭代):
List<Point> pointList = Arrays.asList(new Point(1, 2), newPoint(2, 3));
pointList.forEach(p ->p.translate(1, 1));符號 -> 左邊部分是引數列表,右邊是簡單的表示式體或更復雜的lambda體(花括號包圍)。
如果從未使用過 lambda 表示式, 你會很難理解其中的p是啥。p是由編譯器推斷出來為Point型別。
List的foreach方法在Java8中加入的,它是定義在介面Iterable中的預設方法(介面繼承關係是List繼承Collection,Collection繼承Iterable)。Iterable的原始碼如下:
public interface Iterable<T> {
Iterator<T> iterator();
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
}
相對於外部迭代,可以看到foreach方法是在Iterable內部迭代的,稱為內部迭代。
從外部迭代到內部迭代的變化看起來很小,只不過是迭代工作跨越了客戶端-庫的邊界。不過,其結果卻並不是那麼簡單。我們所需要的並行工作現在可以定義在集合類中,不必重複寫在每一個要迭代集合的客戶端方法中。此外,實現上可以自由使用其他技術,比如說延遲載入、亂序執行或是其他方法,從而更快地
獲得結果。
foreach方法接收的引數是Consumer介面,所以Consumer介面與Lambda表示式是有關聯的,編譯器將lambda表示式轉換成對應的函式式介面Consumer,那它是如何轉化的呢?接下來先看看Consumer介面的完整程式碼:
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}該介面是非常簡單的,除預設方法default外,它只定義了一個方法accept(T t)。
這種只聲明瞭一個抽象方法的介面成為函式式介面。使用@FunctionalInterface 來註解自定義的函式式介面宣告可以讓編譯器檢查是否合法。
函式式介面又分為很多種, java.util.function 中包含 4 種基本的函式式介面型別,而定義的40多個奇怪的型別都是通過 3 種原生型別將型別引數替換掉的各種組合由這 4 種基本型別演化而來的:
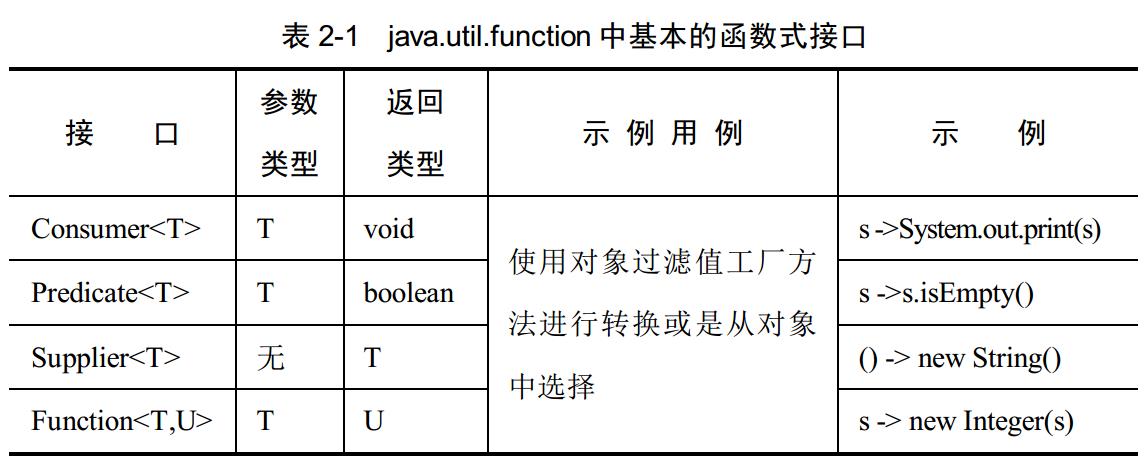
從名字可以看出該函式式介面的行為:
interface LongFunction<R> { R apply(long value); }//函式 引數long,返回R
interface ToIntFunction<T> { int applyAsInt(T value); }//引數T,返回int
interface LongToIntFunction { int applyAsInt(long value); }//引數long,返回int
interface BiConsumer<T,U> { void accept(T t, U u); }//二元消耗(引數T,U返回void)
interface BiFunction<T,U,R> { R apply(T t,U u); } //二元函式(引數T,U返回R)
interface ToIntBiFunction<T,U> { int apply(T t, U u); }//返回為int的二元函式
interface UnaryOperator<T> extends Function<T,T> { ... }//一元操作函式(引數T,返回T)
interface BinaryOperator<T> extends BiFunction<T,T,T> { ... }//二元操作函式(引數T,T返回T)
interface IntBinaryOperator { int applyAsInt(int left, int
right); }//返回為int的二元操作函式回到問題,編譯器是如何將lambda表示式轉換成對應的函式式介面型別呢?
pointList.forEach(p ->p.translate(1, 1));
//這段程式碼中的lambda表示式是如何轉換成對應的Consumer<T>的呢?
//轉換成如下形式
pointList.forEach(new Consumer<Point>(){
@Override
public void accept(Point p){
p.translate(1, 1));
}
});這個形式應該很熟悉吧,沒錯,這就是匿名內部類(實際上lambda與匿名內部類是有區別的,請先暫時認為是這樣轉換的)。以前編寫某個按鈕點選的響應事件時通常會採用這種匿名內部類的方式。那麼編譯器是如何知道表示式 p ->p.translate(1, 1)對應的是Consumer呢,而且又怎麼知道是執行Consumer的accept方法呢?
首先編譯器知道該表示式接收一個引數,然後執行的方法沒有返回值,再根據上下文pointList的元素型別Point,所以根據那表中4種基本函式式介面可以推斷出對應的是Consumer。另外函式式介面只聲明瞭一個抽象方法,所以編譯器可以直接推斷執行的是這個唯一的方法。如果介面中有多個抽象方法,那編譯器是無法推斷出來要執行哪個方法的,這也就是為什麼函式式介面僅僅只定義一個抽象方法的原因。
到此為止,應該對lambda表示式不再恐懼了吧。原來它可以轉換成匿名內部類,只不過要使用它,必須得掌握各種函式式介面的定義。它的這種簡潔性,完全是由編譯器幫我們完成的。
那麼如此的簡潔,總會有一些複雜的表示式是編譯器難以推斷出來的吧?確實有,它是通過 型別檢查(Type Checking)以及過載解析(Overload Resolution)來解決這些問題的。這兩個以及
變數捕獲(Variable Capture)請看電子書。
1.1 lambda 的語法 The Syntax of Lambdas
Java 中的 lambda 表示式包含一個引數列表和一個 lambda 體,二者之間通過一個函式箭頭“->”分隔。包含了單個引數:
p ->p.translate(1, 1)
i -> new Point(i, i + 1)不過與方法宣告類似,lambda 可以接收任意數量的引數。除了像之前那樣接收單個引數的 lambda 外, 引數列表必須使用圓括號包圍起來:
(x, y) -> x + y
() -> 23到目前為止,我們在宣告引數時並沒有顯式指定型別,因為不指定型別時 lambda 的可讀性通常會更好一些。不過,我們總是可以提供引數型別,有時這也是必要的,因為編譯器可能無法從上下文中推斷出其型別。如果顯式提供了型別,那就必須為所有引數都提供型別,而且引數列表必須包圍在圓括號中:
(int x, int y) -> x + y可以像方法引數那樣修改這種顯式型別的引數,例如,可以將其宣告為 final,也可以添加註解。
函式箭頭右側的 lambda 體可以是表示式, 到目前為止所有示例都是這樣的(注意,方法呼叫是表示式,包括那些返回 void 的方法)。諸如此類的 lambda 有時也稱為“表示式 lambda” 。更為一般的形式則是“語句 lambda” ,其中的 lambda 體是一個塊,也就是說,是由花括號包圍的一系列語句:
(Thread t) ->{ t.start(); }
() ->{ System.gc(); return 0; }表示式 lambda:
args -> expr
可以看成相應的語句 lambda 的簡寫形式:
args -> { return expr; }
在塊體中到底使用還是省略 return 關鍵字的原則與普通的方法體是一致的,也就是說,如果 lambda 體中的表示式有返回值,那就需要使用 return,也可以後跟一個引數來立刻終止 lambda 體的執行。如果 lambda 返回 void,那就可以省略 return,也可以使用它,但後面不帶引數。
lambda 表示式不需要也不允許使用 throws 語句來宣告它們可能會丟擲的異常。
1.2 方法與構造器引用 Method and Constructor References
一般來說,任何 lambda 表示式都可以看作宣告在函式式介面中的單個抽象方法的實現。不過,lambda 表示式只是呼叫現有類中的具名方法的一種方式時, 編寫 lambda 的更好方式則是使用已有的名字。例如,考慮如下程式碼,它會向控制檯輸出列表中的每個元素:
pointList.forEach(s -> System.out.print(s));這裡的 lambda 表示式只是將引數傳遞給 print 呼叫。諸如此類的 lambda(其唯一目的就是將引數提供給一個具體方法)完全是由該方法型別定義的。因此,假如可以通過某種方式確定出型別,那麼只包含方法名的簡短形式所提供的資訊就與完整的 lambda表示式一樣,但可讀性會更好。相比於上述程式碼,我們可以這樣編寫:
pointList.forEach(System.out::print);它表示相同的含義。這種對現有類的具體方法的操作寫法稱為方法引用。有 4 種類型的方法引用,如表 2-2 所示。
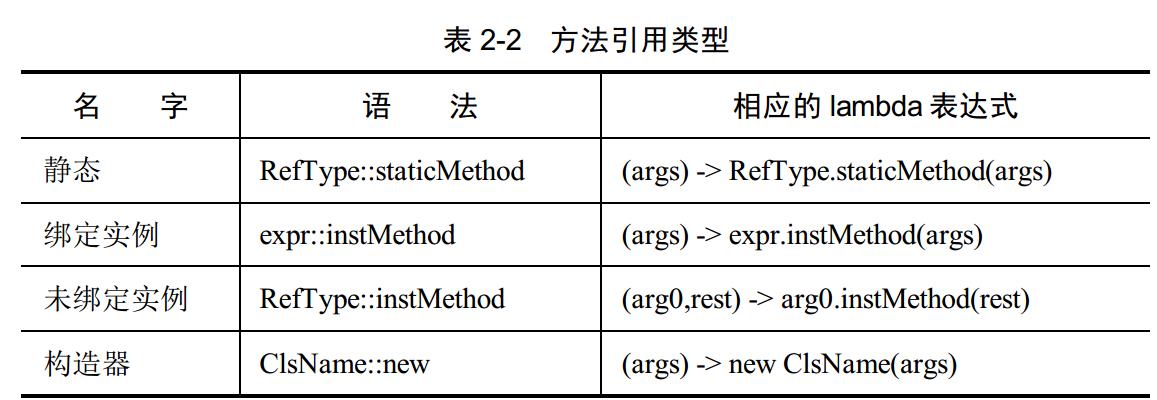
1.2.1 靜態方法引用 Static Method References
靜態方法引用的語法只需要類與靜態方法名,中間通過兩個
冒號分隔。例如:
String::valueOf
Integer::compare
對陣列 integerArray 排序就可以呼叫:
Arrays.sort(integerArray, (x,y) -> Integer.compareUnsigned(x,
y));這是合法的,不過這麼做要比相應的靜態方法引用冗長和重複:
Arrays.sort(integerArray, Integer::compareUnsigned);事實上,該方法是在 Java 8 中引入的,並且就是期望按照這種方式使用。未來,API 設計的一個要素就是希望方法簽名要適合於函式式介面轉換。
1.2.2 例項方法引用 Instance Method References
有兩種方式可以引用例項方法。繫結方法引用類似於靜態引用, 只不過是通ObjectReference::Identifier 替換 ReferenceType::Identifier。之前的示例就是繫結方法引用:forEach方法用於將集合中的每個元素傳遞給 PrintStream 物件 System.out 的例項方法print 進行處理,如下 lambda 表示式:
pointList.forEach(p ->System.out.print(p));可以替換為繫結方法引用:
pointList.forEach(System.out::print);之所以稱為繫結引用,是因為接收者已經確定為方法引用的一部分。 對方法引用 System.out::print 的每次呼叫都會有相同的接收者:System.out。不過,你常常會在呼叫方法引用時帶上方法接收者及其參(來自於方法引用的引數)。要想做到這一點,你需要一個未繫結的方法引用,之所以起這個名字,是因為接收者是不確定的;方法引用的第一個引數被用作接收者。在只有一個引數的情況下,未繫結方法引用是最容易理解的;例如,要想通過工廠方法 comparing建立一個 Comparator, 我們可以將如下 lambda
表示式:
Comparator personComp = Comparator.comparing(p ->p.getLastName());替換為未繫結方法引用:
Comparator personComp = Comparator.comparing(Person::getLastName);未繫結方法引用可以通過其語法識別出來:與靜態方法引用一樣,我們也使用格式 ReferenceType::Identifier,不過這裡的Identifier 指的是例項方法而非靜態方法。要想探尋繫結與未繫結
方法引用之間的差別,考慮呼叫方法 Map.replaceAll 並提供繫結與未繫結的例項方法引用:
其方法宣告為 public void replaceAll(BiFunction<K,V,V> );
Map.replaceAll 的 效 果 是 對 map 中 的 每 個 鍵 值 對 應 用 其BiFunction引數,並使用結果替換鍵值對中的值部分。如果變數map指向的是一個TreeMap,並且其字串表示如下:
{alpha=X, bravo=Y, charlie=Z}那麼像下面這樣通過繫結方法引用來呼叫 replaceAll:
String str = "alpha-bravo-charlie";
map.replaceAll(str::replace)效果就相當於三次應用 str.replace,即:
str.replace("alpha","X")
str.replace("bravo","Y")
str.replace("charlie","Z")每次呼叫的結果都會替換相應的值, 執行完畢後 map 將包含:
{alpha=X-bravo-charlie, bravo=alpha-Y-charlie,charlie=alpha-bravo-Z}現 在 使 用 map 的 初 始 值 來 重 新 執 行 該 例 , 再 次 調 用replaceAll, 這次使用未繫結方法引用 String::concat, 這是對 String例項方法的引用,接收單個引數。使用單個引數的例項方法作BiFunction 看起來有些奇怪,不過事實上它是 BiFunction 的方法引用:它會傳遞兩個引數(鍵值對)並將第一個引數作為接收者,因此方法本身會像下面這樣呼叫:key.concat(value)
方法引用的第 1 個引數移到了接收者的位置, 第 2 個引數(以及隨後的引數,如果存在的話)會向左移動一個位置。因此,如下呼叫:map.replaceAll(String::concat)的結果是:
{alpha=alphaX, bravo=bravoY, charlie=charlieZ}1.2.3 構造器的引用 Constructor References
方法引用是對現有方法的控制代碼,與之類似,構造器引用是對現有構造器的控制代碼。構造器引用的建立語法類似於方法引用,只不過使用關鍵字 new 替換方法名。例如:
ArrayList::new
File::new
與方法引用一樣,對於過載構造器的選擇是通過上下文的目標型別實現的。例如,在如下程式碼中,map 引數的目標型別是型別為 String -> File 的函式;為了與之匹配,編譯器會選擇帶有單
個 String 引數的 File 構造器。
Stream<String> stringStream = Stream.of("a.txt", "b.txt","c.txt");
Stream<File> fileStream = stringStream.map(File::new);1.2.4 lambda 與匿名內部類 Lambdas vs. Anonymous Inner Classes
事實上, lambda 表示式有時被錯誤地稱為匿名內部類的 “語法糖” ,這說的是二者之間只存在簡單的語法上的變化。但實際上,二者之間存在很多顯著差異,其中有兩點對於程式設計師來說非常重要:
● 內部類建立表示式會確保建立一個擁有唯一標識的新物件,而 lambda 表示式的計算結果可能有,也可能沒有唯一標識,這取決於具體實現。相對於對應的內部類來說,這種靈活性可以讓平臺使用更為高效的實現策略。
● 內部類的宣告會創建出一個新的命名作用域, 在這個作用域中,this與super指的是內部類本身的當前例項;相反,lambda表示式並不會引入任何新的命名環境。 這樣就避免了內部類名稱查詢的複雜性,名稱查詢會導致很多小錯誤,例如想要呼叫外圍例項的方法時卻錯誤地呼叫了內部類例項的Object方法。
1.2.4.1 無標識性問題 No Identity Crisis
到目前為止,Java 程式的行為總是與物件相關聯,以標識、狀態和行為為特徵。lambda 則違背了該規則;雖然它們會共享物件的一些屬性,但其唯一的用處是表示行為。由於沒有狀態,因此標識問題就不重要了。語言規範顯式表示其是未確定的,唯一的要求就是 lambda 必須計算出實現了恰當函式介面的類例項。這麼做的意圖是賦予平臺足夠的靈活性來進行優化,如果每個 lambda 表示式都要擁有唯一標識, 那麼這種靈活性無法實現。
1.2.4.2 lambda 的作用域規則 Scoping Rules for Lambdas
就像大多數內部類一樣, 匿名內部類的作用域規則非常複雜,這是因為它可以引用從父型別繼承下來的名字,以及宣告在外部類中的名字。lambda 表示式則要簡單得多,因為它們並不會從父型別中繼承名字 2。除了引數以外,用在 lambda 表示式體中的名字的含義與體外面是一樣的。例如,像下面這樣在lambda 中再次宣告一個區域性變數就是非法的:
void foo() { final int i = 2; Runnable r = () -> { int i = 3;}}//非法引數就像區域性宣告一樣,因為它們可以引入新的名稱:
IntUnaryOperator iuo = i ->{ int j = 3; return i + j; };lambda 引數與 lambda 體區域性宣告可以隱藏欄位名(也就是說,欄位名可能會臨時被重新宣告為引數或區域性變數名)。
class Foo {
Object i, j;
IntUnaryOperator iuo = i -> { int j = 3; return i + j; }
}由於 lambda 宣告就像簡單的塊一樣, 因此關鍵字 this 與 super與外圍環境的含義一樣:也就是說,它們分別指的是外圍物件及其父類物件。例如,如下程式會向控制檯打印出兩條“Hello,world!”訊息
public class Hello {
Runnable r1 = () -> { System.out.println(this); };
Runnable r2 = () -> { System.out.println(toString()); };
public String toString() { return "Hello, world!"; }
public static void main(String... args) {
new Hello().r1.run();
new Hello().r2.run();
}
}如果使用匿名內部類而非 lambda 表示式來編寫同樣的程式,那麼它會打印出在內部類的物件上呼叫 toString 方法的結果。對於匿名內部類來說,更為常見的訪問外圍物件當前例項的用法要使用笨拙的語法 OuterClass.this,而這對於 lambda 來說是非常直接的。
關於如何解釋 this:常常會有這樣一個問題:lambda 能否引用自身呢?如果名字在作用域中,那麼 lambda 就可以引用自身,不過初始化器中的前向引用限制規則(對於區域性變數與例項變數均如此)導致 lambda 變數無法初始化。我們還是可以宣告一個遞迴定義的 lambda:
public class Factorial {
IntUnaryOperator fact;
public Factorial() {
fact = i -> i == 0 ? 1 : i * fact.applyAsInt(i - 1);
}
}需要遞迴的 lambda 定義的場合並不太多, 這種做法完全可以勝任該任務。
2.流與管道的介紹 Introduction to Streams and Pipelines
引入lambda的兩個動機是更好的程式設計程式碼以及更容易的並行化。在Stream處理集合的介紹中將這兩者結合了起來。
2.1 流的基本原理 Stream Fundamentals
在操作方面,流不同於集合之處在於流不儲存值。它們的目標是處理它們。例如,有一個將集合作為它的輸入源的流:建立它的時候沒有資料流;當中間操作需要值的時候,流才從集合中拉取它們來供給;最後,當集合中所有的值被流拉取出來供給後,那流就被消耗掉了並且將來不能再使用。但是這和空的流不一樣;流在任何點上都不保留值。以非集合類作為源的流表現非常類似:例如,生成並列印前10個的2的冪次方可以用如下程式碼:
IntStream.iterate(1, i->i*2).limit(10).forEachOrdered(System.out::println);
//輸出結果是1 2 4 8 16 32 64 128 256 512儘管這個方法iterate生成一個無限流,但是這個lambda代表的函式只會在下游處理(本例是列印)需要值計算時才會被呼叫。 IntStream.iterate(int seed, IntUnaryOperator f) ,
該iterate方法產生一個無限的流:seed,f(seed),f(f(seed),f(f(f(seed)) ……
流背後的中心思想是延遲計算(lazy evaluation) :直到值需要時才會被計算。
在Java中,建立一個Itearator並不會導致任何的值處理髮生,只有當呼叫它的next方法時才會實際上從它的集合中返回值。流在概念上與Itearator很類似,但是有重要的改進:
• 流以一種更加與客戶端友好的方式處理消耗完。Iterators則是通過從hasNext方法返回false時才認為消耗完,因此客戶端每次取一個元素時需要測試它。這個互動式內在的缺陷,因為在呼叫hasNext和next之間的時間差正好是執行緒干擾的時機之窗。而且,它強制讓元素以順序的方式處理,由一個複雜的且通常低效的端/庫之間的互動來實現。
• 流還有一些方法能接受轉換流的行為引數(中間操作)且返回轉換後的流。這就可以使流連結在一起形成管道,不僅提供了一種流暢的程式設計風格,而且還有機會獲得性能上的提升。
• 流還保持關於源的屬性的資訊—例如,源的值是否有序,是否數量已知等等,這樣就允許在值處理方式上可以進行優化,但這對於Itearator則不可以,因為它除了值之外沒有保持其他任何資訊。
延遲計算的一個大的優點可以在流的‘search’方法上體現:findFirst, findAny, anyMatch, allMatch以及noneMatch。這些操作被稱為‘短路’操作,因為他們通常沒有必要處理流中的所有元素。
延遲計算的另一個主要的優點:它允許多個合法的操作混合進一個單一的資料通道。
eg2:首先生成了一個 Integer 例項的集合,接下來通過轉換生成了一個 Point 例項的集合,最後尋找到距離原點最遠的點到原點的距離.
通常可能會寫如下冗長而又低效的程式碼來實現:
List<Integer>intList = Arrays.asList(1, 2, 3, 4, 5);
List<Point>pointList = new ArrayList<>();
for (Integer i : intList) {
pointList.add(new Point(i % 3, i / 1));
}
doublemaxDistance = Double.MIN_VALUE;
for (Point p : pointList) {
maxDistance = Math.max(p.distance(0, 0), maxDistance);
}而流則可以將幾個中間操作(流的轉換)串在一起,值最後才被計算:
OptionalDouble maxDistance =intList.stream()
.map(i -> new Point(i % 3, i / 3))
.mapToDouble(p ->p.distance(0, 0))
.max();
//Integer流 -> Point流 -> Double流,最後在進行求max操作
如果需要並行處理(如果是4核處理器,理論上只需要四分之一的之前的時間)但則只需要改一處程式碼(stream改為parallelStream)即可實現:
OptionalDoublemaxDistance =intList.parallelStream()
.map(i -> new Point(i % 3, i / 3))
.mapToDouble(p ->p.distance(0, 0))
.max();可以看到對於大量的集合處理這是一種非常不同的處理模式。
2.1.1 面向並行的程式碼 Parallel-Ready Code
Lazy value sequences 在程式設計上是一個非常古老的概念。如何區分它們的實現在java上是通過概念上的擴充套件來區分的,包括並行處理。儘管順序處理仍然是一種非常重要的計算模式,但它已不再是唯一的參考模式: 因為並行處理已經如此重要以至於我們需要重新思考我們的計算模型要面向選擇一個程式碼到底如何執行都不可知的處理模式,是否是順序還是並行。那樣的話,我們的程式碼以及更重要的是我們的編碼風格需要迫切改變,當將來優勢的平衡傾斜於並行執行的時候。而Stream API就鼓勵這麼做。
2.1.2 原生流 Primitive Streams
Java5引入的自動裝箱與拆箱讓程式設計師可以忽略原生的值以及其包裹類之間的區別。編譯器通常能檢測出來進行自動裝箱和拆箱操作。但這會帶來一個很高的效能花費問題。例如:
//自動裝箱/拆箱 效能問題 每次計算i+1前要拆箱計算完後再裝箱
Optional<Integer> max = Arrays.asList(1,2,3,4,5)
.stream().map(i>i+1).max(Integer::compareTo);而為了避免自動裝箱拆箱帶來的效能問題,本例中可以可以使用原生流 IntStream,則程式碼可以重寫為:
OptionalInt max = IntStream.rangeClosed(1, 5).map(i->i+1).max();這樣就不會有裝箱拆箱問題,在處理大量資料時,效能上可以提高几個量級。
原生流型別有三種IntStream、LongStream、DoubleStream。float可以嵌入到DoubleStream,char、short、byte則可以嵌入到IntStream中。它們十分類似於引用流型別Stream。流型別可以互相轉變:
• IntStream和LongStream 可以通過asDoubleStream轉換成DoubleStream,對於IntStream 有asLongStream方法可以轉換成LongStream;
DoubleStream ds = IntStream.rangeClosed(1, 10).asDoubleStream();• 對於裝箱操作,每個原生流型別都有一個boxed方法,返回對應的包裹類的流:
Stream<Integer> is = IntStream.rangeClosed(1, 10).boxed();• 對於拆箱操作,包裹類的流可以轉換成對應的原生流,通過呼叫對應的map轉換操作,用合適的拆箱方法作為引數。如下將Stream<Integer>轉換成一個IntStream:
Stream<Integer> integerStream = Stream.of(1, 2);
IntStream intStream = integerStream.mapToInt(Integer::intValue);2.2 剖析管道 Anatomy of a Pipeline
流所有的功能由我們建立的管道通過將它們組合在一起來實現。前面很多例子都展示了管道的各個階段:它的起點是流的源,它的後續的 轉換操作是通過中間操作完成的,最後它的終點以一個終止操作來結束。
2.2.1 開始管道 Starting Pipelines
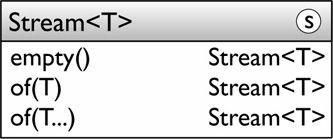
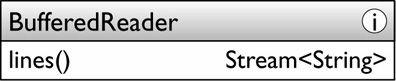
由於流應用於處理大量的資料集上具有巨大的優勢,所以平臺庫中的可以產生大量資料的很多類現在都可以建立流來處理資料。Collections有兩個Stream的工廠方法:
• java.util.Collection<T>:這個介面的兩個預設方法將是最通用的生成流的方式。

注意parallelStream這個方法返回的可能是個並行流,集合只是負責並行的呈現它的資料且並不所有的集合都能做到這點。
為了Collection介面可以引入Stream API ,採用了預設方法的方式。Java8在語法上作如此大的變化是為了解決向後相容性問題。
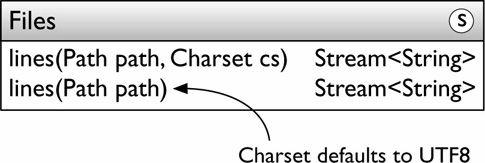
• java.util.stream.Stream<T>:這個介面暴露了幾個靜態工廠方法。原生流有類似的方法。






2.2.2 轉換管道 Transforming Pipelines
隨著流的建立,管道的下一個階段是由一系列中間操作組成。中間操作是延遲計算的:它們只會在終止管道時迫切需要時才會計算。
中間操作分為如下一些:
• Filtering 過濾 Stream<T> filter(Predicate<T>)
• Mapping 對映 ,將每個流中的元素T分別使用Fucntion<T,R>轉換成R:Stream<R> map(Function<T,R>)
例如:Stream<Year> bookTitles = library.stream().map(Book::getPubDate);
當然它有對映的原生型別的方法:

例如:
int totalAuthorships = library.stream().mapToInt(b->b.getAuthors().size()).sum();• One-to-Many Mapping 一對多對映 Stream<R> flatMap(Function<T,Stream<R>>)
例如流中每個元素book,都有多個作者:
Stream<String> authorStream = library.stream()
.flatMap(b->b.getAuthors().stream());通用它也有對應的對映為原生型別的方法:flatMapToInt, flatMapToLong, and flatMapToDouble。
• Debugging 除錯 peek操作的主要目的是用於檢視中間操作的結果,可以用於除錯。peek接收一個Consumer行為引數。
• Sorting and Deduplicating 排序和去重

例如自然排序:
Stream<String> sortedTitles = library.stream()
.map(Book::getTitles())
.sorted();自定義排序:
Stream<Book> booksSortedByTitle = library.stream()
.sorted(Comparator.comparing(Book::getTitle));distinct去重操作。
•Truncating 截斷
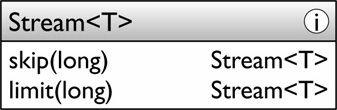
skip丟棄前n個元素,保留其他剩餘的元素,而limit則保留前n個元素,丟棄剩餘的元素。
2.2.3 非侵入性
Stream API 給程式設計師提供了並行操作的功能。並行處理就會涉及執行緒安全的問題。在設計面向並行的程式碼時記住一個原則:
behavioral parameters should be stateless(行為引數應該是狀態無關的)。
面向並行的程式碼的一個同等重要的要求是管道中在執行終止操作期間要避免改變它們的源。
2.2.4 終止管道
分為3類:
• Search operations搜素操作,用於檢測流的元素滿足某種條件,所以不用完全處理整個流就就可以完成操作。

boolean withinShelfHeight = libaray.stream()
.filter(b->b.getTopic() == HISTORY)
.allMatch(b->b.getHeight()<19);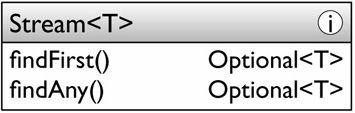
Optional<Book> anyBook = library.stream()
.filter(b->b.getAuthors().contains("Herman MV"))
.findAny();瞅瞅Optional<T> 這個類
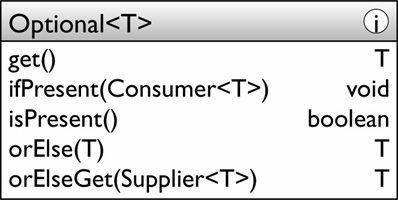
• Reductions 匯聚,以某種歸納流中元素值的方式返回一個單一的值。例如count、max、collectors.

IntSummaryStatistics pageCountStatistics = library.stream()
.mapToInt(b->IntStream.of(b.getPageCounts()).sum())
.summaryStatistics();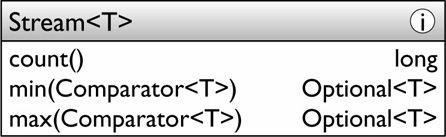
Optional<Book> oldest = library.stream()
.min(Comparator.comparing(Book::getPubDate));
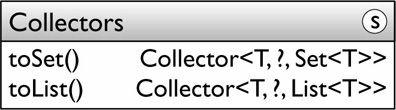
Set<String> titles = library.stream()
.map(Book::getTitle)
.collect(Collectors.toSet());
Map<String,Year> titleToPubdate = library.stream()
.collect(toMap(Book::getTitle,Book::getPubDate));Map<String,Year> titleToPubdate = library.stream()
.collect(toMap(Book::getTitle,Book::getPubDate,(x,y)->x.isAfter(y)?x:y));• Side-effecting operations 附加操作,這類操作只包含兩個方法,forEach和forEachOrder.
對於終止流:收集與匯聚Ending Streams: Collection and Reduction是一個大的話題,這裡不作詳細討論,以及另外流的效能和使用預設方法演化API 章節請看電子書。