
比特幣原始碼情景分析之bloom filter精讀
阿新 • • 發佈:2019-01-02
上一篇SPV錢包裡utxos同步提到了bloom filter,這一章節我們將從原始碼分析角度來個深度解剖Bloom filter基本原理 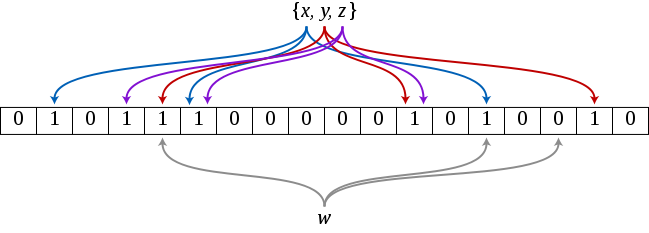 An example of a Bloom filter, representing the set {x, y, z}. The colored arrows show the positions in the bit array that each set element is mapped to. The element w is not in the set {x, y, z}, because it hashes to one bit-array position containing 0. For this figure, m = 18 and k = 3.
An example of a Bloom filter, representing the set {x, y, z}. The colored arrows show the positions in the bit array that each set element is mapped to. The element w is not in the set {x, y, z}, because it hashes to one bit-array position containing 0. For this figure, m = 18 and k = 3.
else if (strCommand == NetMsgType::FILTERLOAD) { CBloomFilter filter;
比如根據交易的publicKey來過濾交易,就可以在transaction的txin, txout的上做文章.想P2PK的解鎖和鎖定指令碼中都有pubKey,可以用來filter./********************************* 本文來自CSDN博主"愛踢門"******************************************/
An example of a Bloom filter, representing the set {x, y, z}. The colored arrows show the positions in the bit array that each set element is mapped to. The element w is not in the set {x, y, z}, because it hashes to one bit-array position containing 0. For this figure, m = 18 and k = 3.else if (strCommand == NetMsgType::FILTERLOAD) { CBloomFilter filter;
比如根據交易的publicKey來過濾交易,就可以在transaction的txin, txout的上做文章.想P2PK的解鎖和鎖定指令碼中都有pubKey,可以用來filter./********************************* 本文來自CSDN博主"愛踢門"******************************************/