
python程式設計:tabula、pdfplumber、camelot進行表格資料識別
阿新 • • 發佈:2019-01-03
本文就目前python圖表識別的庫進行測試
1、tabula
2、pdfplumber
3、camelot
準備資料
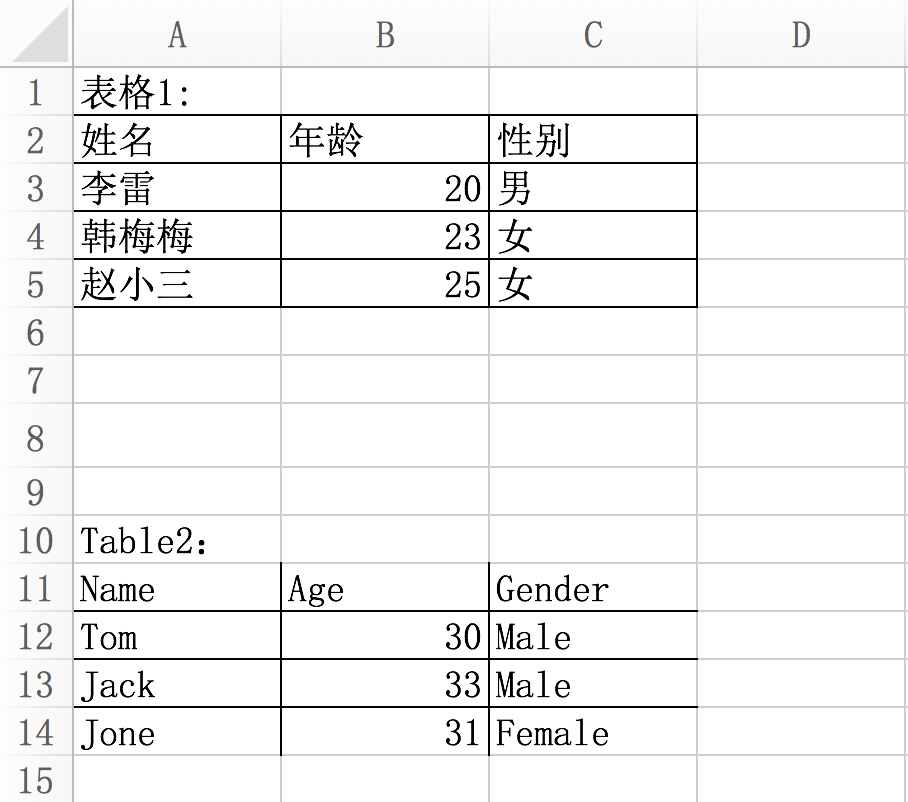
excel:names.xlsx,兩個表格
表格1:所有欄位都被線條包圍
表格2:最外層沒有線條包圍
將excel另存為pdf:names.pdf
1、tabula
github:https://github.com/chezou/tabula-py
安裝:
pip install tabula-py
依賴:
Java 7, 8
程式碼示例:
import tabula
tabula.convert_into(
input_path= 轉換出來的names.csv,發現只有表格1被提取出來了,而且不規範,中間多了逗號
"姓名",年齡,性別
"李雷",,20 男
"韓梅梅",,23 女
"趙小三",,25 女
2、pdfplumber
github: https://github.com/jsvine/pdfplumber
安裝
pip install pdfplumber
程式碼示例:
import pdfplumber
import pandas as 文字解析的很全,只有表格1解析完全了,表格2只是解析了有框的部分
3、camelot
github: https://github.com/socialcopsdev/camelot
安裝:
pip install camelot-py[cv]
示例
import camelot
tables = camelot.read_pdf("source/names.pdf")
tables.export("source/names.csv")
生成2個檔案:
source/names-page-1-table-1.csv
"姓名","年齡","性別"
"李雷","20 男",""
"韓梅梅","23 女",""
"趙小三","25 女",""
source/names-page-1-table-2.csv
"Name","Age","Gender"
"Tom","","30 Male"
"Jack","","33 Male"
"Jone","","31 Female"
發現表格2的內容被解析出來了,不過兩個表格的內容都錯位了
經過測試後,發現這3個庫對錶格識別都不是太好
總結
| 庫名 | 說明 |
|---|---|
| tabula | 能提取完整表格,提取結果不規範 |
| pdfplumber | 能提取完整表格,提取結果較為規範 |
| camelot | 能提取完整表格和不完整表格,提取結果不規範 |