
CHAPTER 9 -Up and Running with TensorFlow part1
本篇文章是個人翻譯的,如有商業用途,請通知本人謝謝.
創造第一個圖譜,然後執行它
import tensorflow as tf
x = tf.Variable(3, name="x")
y = tf.Variable(4, name="y")
f = x*x*y + y + 2這就是它的一切! 最重要的是要知道這個程式碼實際上並不執行任何計算,即使它看起來像(尤其是最後一行)。 它只是建立一個計算圖譜。 事實上,變數都沒有初始化.要評估此圖,您需要開啟一個TensorFlow會話並使用它初始化變數並評估f。 TensorFlow會話負責處理在諸如CPU和GPU之類的裝置上的操作並執行它們,並且它保留所有變數值.以下程式碼建立一個會話,初始化變數,並評估,然後f關閉會話(釋放資源):
# way1
sess = tf.Session()
sess.run(x.initializer)
sess.run(y.initializer)
result = sess.run(f)
print(result)
sess.close()不得不每次重複sess.run()有點麻煩,但幸運的是有一個更好的方法:
#way2
with tf.Session() as sess:
x.initializer.run()
y.initializer.run()
result = f.eval()
print(result)在with塊中,會話被設定為預設會話。 呼叫x.initializer.run()等效於呼叫tf.get_default_session().run(x.initial), f.eval()等效於呼叫tf.get_default_session()。執行(F)。 這使得程式碼更容易閱讀。 此外,會話在塊的末尾自動關閉。
你可以使用global_variables_initializer()函式,而不是手動初始化每個變數。 請注意,它實際上沒有立即執行初始化,而是在圖譜中建立一個當程式執行時所有變數都會初始化的節點:
#way3
# init = tf.global_variables_initializer()
# with tf.Session() as sess:
# init.run()
# result = f.eval()
# print(result)在Jupyter內部或在Python shell中,您可能更喜歡建立一個InteractiveSession。 與常規會話的唯一區別是,當建立InteractiveSession時,它將自動將其自身設定為預設會話,因此您不需要使用模組(但是您需要在完成後手動關閉會話):
#way4
init = tf.global_variables_initializer()
sess = tf.InteractiveSession()
init.run()
result = f.eval()
print(result)
sess.close()管理圖譜
您建立的任何節點都會自動新增到預設圖形中:
>>> x1 = tf.Variable(1)
>>> x1.graph is tf.get_default_graph()
True>>> graph = tf.Graph()
>>> with graph.as_default():
... x2 = tf.Variable(2)
...
>>> x2.graph is graph
True
>>> x2.graph is tf.get_default_graph()
False在Jupyter(或Python shell)中,通常在實驗時多次執行相同的命令。 因此,您可能會收到包含許多重複節點的預設圖形。 一個解決方案是重新啟動Jupyter核心(或Python shell),但是一個更方便的解決方案是通過執行tf.reset_default_graph()來重置預設圖。
節點值的生命週期
評估節點時,TensorFlow會自動確定所依賴的節點集,並首先評估這些節點。 例如,考慮以下程式碼:
# w = tf.constant(3)
# x = w + 2
# y = x + 5
# z = x * 3
# with tf.Session() as sess:
# print(y.eval())
# print(z.eval())首先,這個程式碼定義了一個非常簡單的圖。然後,它啟動一個會話並執行圖來評估y:TensorFlow自動檢測到y取決於w,這取決於x,所以它首先評估w,然後x,然後y,並返回y的值。最後,程式碼執行圖來評估z。再次,TensorFlow檢測到它必須首先評估w和x。重要的是要注意,它不會重用以前的w和x的評估結果。簡而言之,前面的程式碼評估w和x兩次。
所有節點值都在圖執行之間刪除,除了變數值,由會話跨圖形執行維護(佇列和讀者也保持一些狀態)。變數在其初始化程式執行時啟動其生命週期,並且在會話關閉時結束。
如果要有效地評估y和z,而不像之前的程式碼那樣評估w和x兩次,那麼您必須要求TensorFlow在一個圖形執行中評估y和z,如下面的程式碼所示:
# with tf.Session() as sess:
# y_val, z_val = sess.run([y, z])
# print(y_val) # 10
# print(z_val) # 15Linear Regression with TensorFlow
TensorFlow操作(也稱為ops)可以採用任意數量的輸入併產生任意數量的輸出。 例如,加法運算和乘法運算都需要兩個輸入併產生一個輸出。 常量和變數不輸入(它們被稱為源操作)。 輸入和輸出是稱為張量的多維陣列(因此稱為“tensor flow”)。 就像NumPy陣列一樣,張量具有型別和形狀。 實際上,在Python API中,張量簡單地由NumPy ndarrays表示。 它們通常包含浮點數,但您也可以使用它們來傳送字串(任意位元組陣列)。
迄今為止的示例,張量只包含單個標量值,但是當然可以對任何形狀的陣列執行計算。例如,以下程式碼操作二維陣列來對加利福尼亞房屋資料集進行線性迴歸(在第2章中介紹)。它從獲取資料集開始;那麼它會向所有訓練例項新增一個額外的偏置輸入特徵(x0 = 1)(它使用NumPy進行,因此立即執行);那麼它建立兩個TensorFlow常數節點X和y來儲存該資料和目標,並且它使用TensorFlow提供的一些矩陣運算來定義theta。這些矩陣函式transpose(),matmul()和matrix_inverse() 是不言自明的,但是像往常一樣,它們不會立即執行任何計算;相反,它們會在圖形中建立在執行圖形時執行它們的節點。您可以認識到θ的定義對應於方程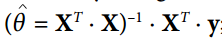
最後,程式碼建立asession並使用它來評估theta。
import numpy as np
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
m, n = housing.data.shape
#np.c_按colunm來組合array
housing_data_plus_bias = np.c_[np.ones((m, 1)), housing.data]
X = tf.constant(housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")
XT = tf.transpose(X)
theta = tf.matmul(tf.matmul(tf.matrix_inverse(tf.matmul(XT, X)), XT), y)
with tf.Session() as sess:
theta_value = theta.eval()
print(theta_value)其實這裡就是用最小二乘法算θ
實現梯度下降
讓我們嘗試使用批量梯度下降(在第4章中介紹),而不是普通方程。 首先,我們將通過手動計算梯度來實現,然後我們將使用TensorFlow的自動擴充套件功能來使TensorFlow自動計算梯度,最後我們將使用幾個TensorFlow的優化器。
當使用梯度下降時,請記住,首先要對輸入特徵向量進行歸一化,否則訓練可能要慢得多。 您可以使用TensorFlow,NumPy,ScikitLearn的StandardScaler或您喜歡的任何其他解決方案。 以下程式碼假定此規範化已經完成。
手動計算漸變
以下程式碼應該是相當不言自明的,除了幾個新元素:
•random_uniform()函式在圖形中建立一個節點,它將生成包含隨機值的張量,給定其形狀和值範圍,就像NumPy的rand()函式一樣。
•assign()函式建立一個將為變數分配一個新值的節點。 在這種情況下,它實現了批次梯度下降步驟θ(next step)=θ-η∇θMSE(θ)。
•主迴圈一次又一次(n_epochs次)執行訓練步驟,每100次迭代都打印出當前均方誤差(mse)。 你應該看到MSE在每次迭代中都會下降。
housing = fetch_california_housing()
m, n = housing.data.shape
m, n = housing.data.shape
#np.c_按colunm來組合array
housing_data_plus_bias = np.c_[np.ones((m, 1)), housing.data]
scaled_housing_data_plus_bias = scale(housing_data_plus_bias)
n_epochs = 1000
learning_rate = 0.01
X = tf.constant(scaled_housing_data_plus_bias, dtype=tf.float32, name="X")
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name="y")
theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0), name="theta")
y_pred = tf.matmul(X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
gradients = 2/m * tf.matmul(tf.transpose(X), error)
training_op = tf.assign(theta, theta - learning_rate * gradients)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
if epoch % 100 == 0:
print("Epoch", epoch, "MSE =", mse.eval())
sess.run(training_op)
best_theta = theta.eval()Using autodiff
上述程式碼執行的不錯,但它需要從數學上損失成本函式(MSE)的梯度。 線上性迴歸的情況下,這是相當容易的,但是如果你必須用深層神經網路來做這個事情,你會感到頭痛:這將是乏味和容易出錯的。 您可以使用symbolic di‰erentiation來為您自動找到偏導數的方程式,但結果程式碼不一定非常有效。
為了理解為什麼,考慮函式f(x)= exp(exp(exp(x)))。 如果你知道微積分,你可以計算出它的導數f'(x)= exp(x)×exp(exp(x))×exp(exp(exp(x)))。如果您按照普通的計算方式分別去寫f(x)和f'(x),您的程式碼將不會如此有效。 一個更有效的解決方案是寫一個首先計算exp(x),然後exp(exp(x)),然後exp(exp(exp(x)))的函式,並返回所有三個。這給你直接(第三項)f(x),如果你需要派生,你可以把這三個子式相乘,你就完成了。
通過傳統的方法,您不得不將exp函式呼叫9次來計算f(x)和f'(x)。 使用這種方法,你只需要呼叫它三次。
當您的功能由某些任意程式碼定義時,它會變得更糟。 你可以找到方程(或程式碼)來計算以下函式的偏導數?
提示:不要嘗試。
def my_func(a, b):
z = 0
for i in range(100):
z = a * np.cos(z + i) + z * np.sin(b - i)
return z幸運的是,TensorFlow的自動計算梯度功能可以計算這個公式:它可以自動高效地為您梯度的計算。 只需用以下一行替換上一節中程式碼的gradients = ... 行,程式碼將繼續工作正常:
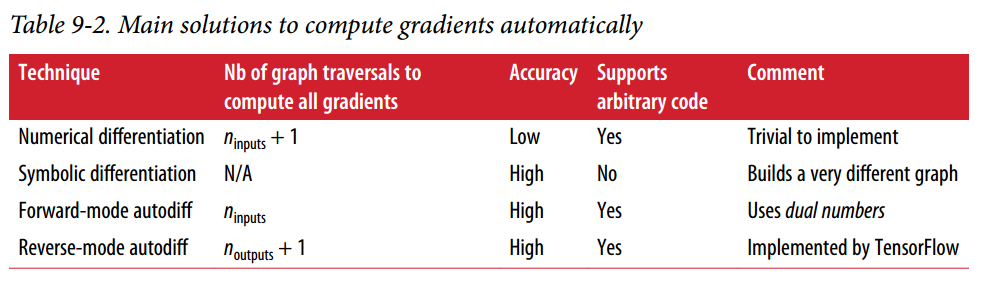
gradients = tf.gradients(mse, [theta])[0]自動計算梯度有四種主要方法。 它們總結在表9-2中。 TensorFlow使用反向模式,這是完美的(高效和準確),當有很多輸入和少量的輸出,如通常在神經網路的情況。 它只是在n(outputs) + 1圖遍歷中計算所有輸出的偏導數。
使用優化器
所以TensorFlow為您計算梯度。 但它還有更好的方法:它還提供了一些可以直接使用的優化器,包括梯度下降優化器。您可以使用以下程式碼簡單地替換以前的gradients = ... 和training_op = ...行,並且一切都將正常工作:
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(mse)optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate,
momentum=0.9)將資料提供給訓練演算法
我們嘗試修改以前的程式碼來實現小批量梯度(Mini-batch Gradient Descent)下降。 為此,我們需要一種在每次迭代時用下一個小批量替換X和Y的方法。 最簡單的方法是使用佔位符節點(placeholder)。 這些節點是特別的,因為它們實際上並不執行任何計算,只是輸出您在執行時輸出的資料。 它們通常用於在培訓期間將訓練資料傳遞TensorFlow。 如果在執行時沒有為佔位符指定值,則會收到異常。
要建立佔位符節點,您必須呼叫placeholder() 函式並指定輸出張量的資料型別。 或者,您還可以指定其形狀,如果要強制執行。 如果指定維度為“None”,則表示“任何大小”。例如,以下程式碼建立一個佔位符節點A,還有一個節點B = A + 5.當我們評估B時,我們將一個feed_dict傳遞給eval ()方法指定A的值。注意,A必須具有2級(即它必須是二維的),並且必須有三列(否則引發異常),但它可以有任意數量的行。
>>> A = tf.placeholder(tf.float32, shape=(None, 3))
>>> B = A + 5
>>> with tf.Session() as sess:
... B_val_1 = B.eval(feed_dict={A: [[1, 2, 3]]})
... B_val_2 = B.eval(feed_dict={A: [[4, 5, 6], [7, 8, 9]]})
...
>>> print(B_val_1)
[[ 6. 7. 8.]]
>>> print(B_val_2)
[[ 9. 10. 11.]
[ 12. 13. 14.]]要實現小批量漸變下降,我們只需稍微調整現有的程式碼。 首先更改X和Y的定義,使其佔位符節點:
X = tf.placeholder(tf.float32, shape=(None, n + 1), name="X")
y = tf.placeholder(tf.float32, shape=(None, 1), name="y")batch_size = 100
n_batches = int(np.ceil(m / batch_size))def fetch_batch(epoch, batch_index, batch_size):
[...] # load the data from disk
return X_batch, y_batch
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
for batch_index in range(n_batches):
X_batch, y_batch = fetch_batch(epoch, batch_index, batch_size)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
best_theta = theta.eval()在評估theta時,我們不需要傳遞X和y的值,因為它不依賴於它們。
MINI-BATCH完整程式碼
import numpy as np
from sklearn.datasets import fetch_california_housing
import tensorflow as tf
from sklearn.preprocessing import StandardScaler
housing = fetch_california_housing()
m, n = housing.data.shape
print("資料集:{}行,{}列".format(m,n))
housing_data_plus_bias = np.c_[np.ones((m, 1)), housing.data]
scaler = StandardScaler()
scaled_housing_data = scaler.fit_transform(housing.data)
scaled_housing_data_plus_bias = np.c_[np.ones((m, 1)), scaled_housing_data]
n_epochs = 1000
learning_rate = 0.01
X = tf.placeholder(tf.float32, shape=(None, n + 1), name="X")
y = tf.placeholder(tf.float32, shape=(None, 1), name="y")
theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42), name="theta")
y_pred = tf.matmul(X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(mse)
init = tf.global_variables_initializer()
n_epochs = 10
batch_size = 100
n_batches = int(np.ceil(m / batch_size)) #ceil()方法返回x的值上限 - 不小於x的最小整數。
def fetch_batch(epoch, batch_index, batch_size):
know = np.random.seed(epoch * n_batches + batch_index) # not shown in the book
print("我是know:",know)
indices = np.random.randint(m, size=batch_size) # not shown
X_batch = scaled_housing_data_plus_bias[indices] # not shown
y_batch = housing.target.reshape(-1, 1)[indices] # not shown
return X_batch, y_batch
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
for batch_index in range(n_batches):
X_batch, y_batch = fetch_batch(epoch, batch_index, batch_size)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
best_theta = theta.eval()
print(best_theta)