hadoop原始碼學習 InputFormat抽象類
阿新 • • 發佈:2019-01-03
hadoop最cool的就是MapReduce了,那麼當執行一個MapReduce作業的時候,你有沒有想過內部是如何實現的?儲存在HDFS上的資料到底是特麼的怎樣被讀取的?HelloWord級別的worldcount程式,是對文字檔案一行一行的讀的,為此我們需要對我們的文字進行處理,讓其老老實實的一行一行的排著隊。但是在生產環境中,各種格式的資料檔案,恐怕一行一行的排隊就滿足不了我們的要求了。比如需要誇張的處理100G的excel檔案,這個時候就需要自己來定義一個輸入格式了。所以,我就想來解決這個問題。
幹掉敵人之前,先要弄清楚他的底細,那麼我們就從hadoop的原始碼開始研讀。
第一個被研讀的物件就是InputFormat。
InputFormat作為hadoop作業的所有的輸入格式的抽象基類(與之相對應的hadoop作業的所有的輸出格式的抽象基類OutputFormat我等下再來學習),它描述了作業的輸入需要滿足的規範細節。也就是說,你要實現自己的一個指定輸入格式的類,必須滿足這個規範,不然遊戲就玩不下去了,因為你用的就是hadoop這個平臺。
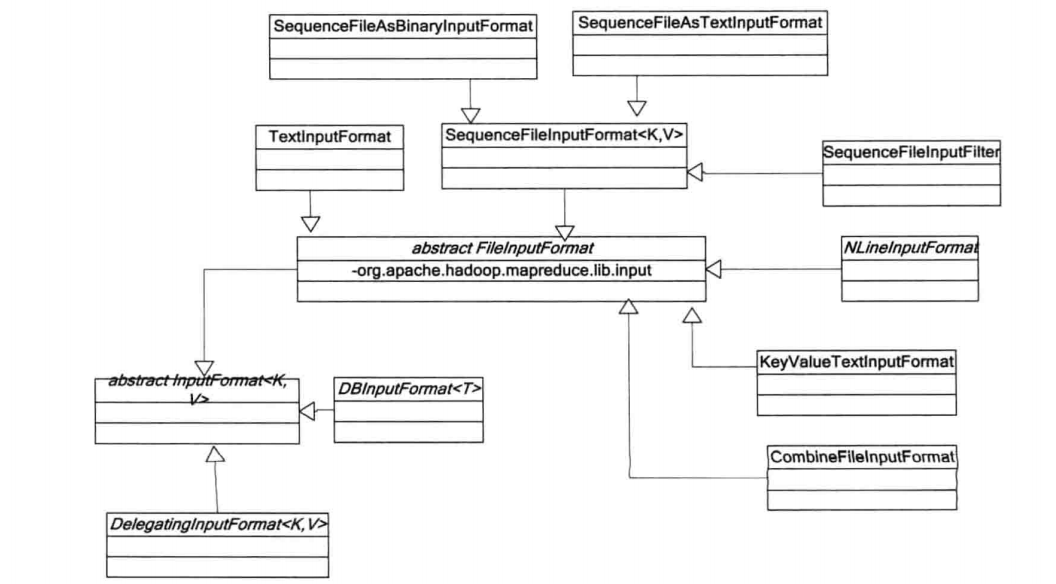
InputFormat這個抽象類的原始碼內部定義了兩個抽象方法:
public abstract List<InputSplit> getSplits(JobContext context) throws IOException,InterruptedException;改方法的主要作用就是將hdfs上要處理的檔案分割成許多個InputSplit,這裡的InputSplit就是hadoop平臺上的邏輯分片,對應的還有物理分片blocks,以後學習HDFS原始碼的時候再來講這個。每一個分片(InputSplit),通過其內部定義的檔案路徑,起始位置,偏移量三個位置來唯一確定。
public abstract RecordReader<K,V> createRecordReader 該方法就是為指定的InputSplit建立記錄讀取器(後面我們將實現自己的RecordReader),通過記錄讀取器從輸入分片中讀取鍵值對,然後將鍵值對交給Map來處理。看到這裡,我想我們應該一些什麼。
當hadoop執行MapReduce作業的時候需要依賴InputFormat來完成以下幾方面的工作:
- 檢查作業的輸入是否有效;
- 將輸入檔案分割成多個InputSplit,然後將每個InputSplit分別傳給單獨的Map進行處理,也就是說有多少個InputSplit就會有多少個Map任務,Number(Map)==Number(InputSplit)
- InputSplit是由一個個記錄組成的,所以InputSplit需要提供一個RecordReader的實現,然後通過RecordReader的實現來讀取InputFormat中的每一條記錄,並將讀取的記錄交給Map函式來進行處理。以下是hadoop預設為我們提供的InputFormat實現類: