
人臉關鍵點定位.Face Alignment by Coarse-to-Fine Shape Searching 演算法原始碼詳解(下)
首先按照原始碼中read me配置。可能執行出錯的部分,用黃字高亮瞭解決方案。
以下分別解說訓練和測試程式碼。
====訓練部分===============
l learnCFSS.m為核心訓練檔案。需要順序執行getParametricModels;addAll; learnCFSS;
執行需要matlabpool。如果資料N<100,則不啟動並行。如果沒有並行工具箱,可以手工修改程式碼不啟動並行。
至少需要約900個樣本,才能通過PCA部分的數量斷言。需要較大記憶體要求。
poseVoting.m中使用dist函式,需要神經網路工具箱。如果沒有該工具箱,可以手工新增dist函式。
至少需要約2700個樣本,才能通過traintestP.m中,訓練SVC時的數量斷言。
traintestP.m中呼叫了libsvm的函式svmtrain。未避免呼叫到VLFEAT中的同名函式,在進入這部分之前,先去除VLFEAT的路徑,之後再新增上。
learnCFSS
|
各種load |
|
|
for level = 1:stageTot 實際只用3次迭代 |
|
|
% Re-trains僅在第一次迭代呼叫 |
|
|
trainingSetGeneration:返回旋轉對齊影象(images),生成平均臉(referenceShape),影象旋轉回歸器B,對齊變換T。 Pr:先驗概率。,N *N,每行對應一個原始樣本,表示取得每一個原始樣本的概率。設定為均勻分佈,對角線零,其他位置均等。 model.tpt:當前level目標形狀。N*2L。用來在測試時依照概率生成樣本。 |
|
|
主要作用:歸一化樣本 |
|
|
% from Pr to sub-region center |
|
|
traintestReg:生成迴歸模型regModel和當前形狀currentPose(相當於論文中sub-region center)。 T:當前形狀到平均臉(referenceShape)的變換 images:用T進一步更新影象 model.tpt:當前level目標性狀,記為targetPose。 |
|
|
主要作用:根據概率Pr,生成擴充套件初始值,用迴歸器移動形狀,得到currentPose。 |
|
|
% Train-test Pr |
|
|
traintestP:估計當前各個訓練影象上,各個訓練集形狀的概率Pr。 |
|
trainingsetGeneration
只在第一次迭代呼叫
|
% 輸入 |
||
|
% Loading original images |
||
|
Tb:每個原始影象中simple face(左右眼角左右嘴角)到標準形狀的變換。N*2L。其中標準形狀為target_simple_face(0-1之間)放大到priorsInfo.win_size(250*250)。 targetPose:旋轉到標準simple shape之後的L個關鍵點。 referenceShape:平均形狀。 |
||
|
% Label angle estimation according to targetPose |
||
|
Te:每一個targetPose(已經粗略旋轉過)到referenceShape(平均形狀)的變換。是一個較小較精細的變換。 angle:Te變換的旋轉角度。 |
||
|
% Dataset partition |
||
|
set_id:N*1。把所有原始資料隨機分成均等兩組。用於訓練兩個旋轉角度迴歸器。 |
||
|
% Training |
||
|
B:兩個角度迴歸器。互為校驗。 |
||
|
for s = 1:2 分別使用兩組資料訓練B{s} |
||
|
Tb_train:本次訓練中,從原始影象到標準形狀的變換。 angle_train:本次訓練中,從粗略旋轉到精細旋轉的變化角度。 mp:用於本次訓練的樣本數。約為N/2。 MP:擴充套件後的樣本數。擴充套件10倍(priorsInfo.augTimes)。 im:本次訓練中,原始影象經過旋轉得到的augment結果。N/2*擴充套件數。 label:擴充套件樣本的隨機旋轉角度,最大旋轉45°(priorsInfo.maxRoll)。 |
||
|
for i = 1: augTimes |
||
|
Tr_train:從現有角度到擴充套件后角度的變換 Tbr_train:總體旋轉角度。融合了Tb_train和Tr_train。 im:用Tbr_train對原始影象進行旋轉。 |
||
|
F:本次訓練的樣本特徵,影象250*250,從中心部分擷取一個3*3視窗,提取31維hog特徵。特徵長度3*3*31 = 279。 B{s}:用前述特徵通過TreeBagger預測旋轉角度,得到ensemble of bagged decision trees。記為B。樣本隨機分成兩部分,s=1:2,分別計算兩個B。其用意參見測試部分。 |
||
|
images:原始影象通過Tb變換,粗略旋轉對齊到標準形狀上。 |
||
|
% 返回 |
||
|
粗略旋轉對齊到標準形狀上的images priorModel中的平均臉referenceShape priorModle中的旋轉回歸器B 旋轉對齊到平均形狀上的變換T |
||
traintestReg
|
% 輸入 |
|
|
images:原始形狀 targetPose:目標形狀 Pr:概率。N*N。 |
|
|
% 1. Sampling both for train and test 根據Pr為每個樣本生成訓練和測試樣本 |
|
|
currentPose_train, currentPose_test:對於每一個原始樣本,都有10個(regsInfo.trainSampleTot)用於訓練和10個(regsInfo.testSampleTot)用於測試的樣本,是從N個原始樣本中抽取的。N*2L*10. |
|
|
for i = 1:m 對於每一個樣本 |
|
|
第一次迭代 |
|
|
index_train:用randSampleNoReplace從原始樣本中根據Pr抽取10個樣本。此時Pr是除了當前樣本之外的均勻分佈。 index_test:用randSampleNoReplace從原始樣本中根據PrI_temp抽取10個樣本。其中PrI_temp是刨除10個訓練樣本之後的概率分佈。訓練和測試不能重複。 |
|
|
其他次迭代 |
|
|
tmp:將樣本按照Pr降序排列 index_train, index_test:概率最大的trainSampleTot個樣本。 |
|
|
從目標形狀中根據index_XXX取出currentPose_XXX。 |
|
|
% 2. learn regressors to get regModel % 2A. Augmentation 把訓練樣本進行隨機變換 |
|
|
M:N*訓練樣本數(10)。每個樣本有10個訓練,10個測試。 cu:當前形狀。10N*2L tg:目標形狀。10N*2L |
|
|
for i = 1:trainSampleTot 處理所有原始樣本的第i個訓練樣本,共N個。 |
|
|
selectPoses:返回每個目標形狀(targetPose)中,外眼角(regsInfo.aug_eyes_id)位置。N*4。 Ta:1*N個隨機變換。是通過原始樣本中隨機兩個樣本之間的變換而得。對於每一個i,都重新隨機一次。 cu:把currentPose_train中的相應的N個訓練樣本施加Ta中的N個變化,得到N個結果。 tg:把targetPose(共N個)施加Ta中的N個變化,得到N個結果。 im:把每個原始影象經過Ta中的N個變化,得到N個結果。 當訓練樣本序號i為偶數時,把cu、tg、im都映象。 |
|
|
% 2B. Training iteration |
|
|
for iter = 1:iterTot 共3次,訓練每一個迭代的一系列迴歸器 |
|
|
featOri:每一個原始樣本的 關鍵點SIFT特徵,使用自定義函式extractSIFTs_toosimple提取。維度128*L = 8704。所以至少需要871個原始樣本。 featReg:對featOri做PCA之後,保留98%能量,壓縮到3693維。 pca_model:PCA模型 reg_model:用trainLR_averageHalfBaggin訓練一個迴歸器,從特徵featReg預測形狀偏差tg-cu。相當於原始SDM中的一級迴歸器。 regModel:最終返回的模型。平均值mu設為PCA的平均特徵meanFeatOri,一次項A設為PCA的投影矩陣coeff和reg_model一次項的乘積,常數項定義為reg_model的常數項。 更新當前形狀cu:PCA和迴歸合併到一步完成。 |
|
|
featOri_batch:所有樣本對應測試樣本的SIFT特徵。N*8704*10。 currentPose_test:用前述特徵通過迴歸器進行更新。 |
|
|
currentPose:從測試樣本currentPose_test中,利用poseVoting(論文中的自動權重)計算。N*2L。描述一個概率分佈。 |
|
|
% 返回 |
|
|
包含PCA的偏移量回歸模型regModel 當前形狀currentPose |
|
traintestP
計算Pr的核心是inferenceP函式,前面的都在訓練模型。
|
% 輸入 |
|
|
images:原始影象 targetPose:目標形狀 currentPose:當前形狀 |
|
|
% A. Prior Prob Learning 論文中概率第一項:從偏差值推測概率 |
|
|
d:當前形狀currentPose到目標性狀targetPose偏移。N*2L d_pca:偏移量PCA結果,壓縮到17維。N*17。 PModel.sigma:d_pca的協方差。測試時用高斯模型估計偏差值的概率。 PModel.pca_model:偏移量投影的PCA模型 |
|
|
% B. Features Prob Learning 論文中概率第二項:從特徵和偏差推斷概率 % 1. Sampling for training and testing |
|
|
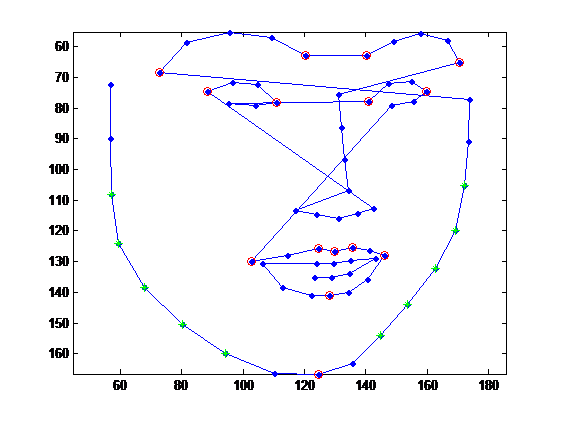
s:取樣個數probsInfo.probSamplings=5。擴充套件樣本用於訓練點偏移SVM。 ld:有15個semantic點,如下圖紅色。每個點有一個cell。儲存semantic點偏移量位置。 |
|
|
for i = 1 : length(semantic_id) 全部樣本的每個semantic點 |
|
|
dx,dy:半徑0-SVCradius之間,方向0-2PI之間的隨機向量。N*5。 ld的當前cell:N*5*2。全部樣本目標形狀targetPose的semantic點,加上上述隨機偏移。 |
|
|
% 2. Centralized feature extraction |
|
|
feat_all:每個尺度一級。尺度probsInfo.pyramidScale=3 |
|
|
for pyramid = 1:length(pyramidScale) |
|
|
pose:N*(2*15)*(5+1)。樣本數*semantic點數*(取樣數+1)。前5維為ld中的偏移位置targetPose+(dx,dy),最後一維是未偏移的當前形狀currentPose。 feat_all:在pose上提取SIFT特徵。 |
|
|
% Unroll them into training and test set |
|
|
F_train, L_train, F_current:每個semantic點對應一個cell, |
|
|
for i = 1:length(semantic_id) 每個semantic點單獨訓練 |
|
|
訓練資料個數:N*s。 F_train{i}:(N*s)*(128*3)。3尺度SIFT。偏移的s個取樣的特徵。 L_train{i}:(N*s)*2。pose到targetPose的偏移量。 F_current{i}:N*(128*3)。當前形狀的特徵。 |
|
|
% 3. Train SVM classifiers for each landmark |
|
|
svc_:每個semantic點有一個svc模型。 |
|
|
for i = 1:semantic_id 每個semantic點訓練SVC |
|
|
從N*s個原始樣本中挑選出正負樣本 ind_pos:偏移距離小於probsInfo.SVCthre = 0.3/0.6 ind_neg:偏移距離大於probsInfo.SVCthre 要求正負樣本中較少的數量 > 8倍維度 = 3072。約需要2700個樣本。 用正負樣本訓練當前SVC。偏差小的輸出1,偏差大的輸出0。(libsvm自動把+-1標記轉換為0/1標記??) |
|
|
PModel.SVC賦值為剛訓練出的模型。 |
|
|
% 4. tpt analysis |
|
|
PModel.representativeLocation:長度為semantic點數 |
|
|
for i = 1:length(semantic_id) |
|
|
location:全部目標形狀中當前semantic點位置 picked_id:用analyse_tpt.m函式找出該點在不同形狀中的代表位置。(詳細參看analyse_tpt)從全部形狀中選出probsInfo.representativ2Num1個, 從居於中心的形狀中選出probsInfo.representativeNum2個,共20個。 PModel.representativeLocation{i}:20*2,20個代表形狀的位置。 |
|
|
% C. Testing and training |
|
|
Pr:使用reference.Pm函式計算在PModel下,每一個當前形狀屬於每一個目標形狀的概率。(詳細參看inferenceP.m) |
|
|
% 返回 |
|
|
PModel:包含第一項PCA,以及第二項SVC的模型 Pr:當前形狀概率。 |
|
analyse_tpt.m
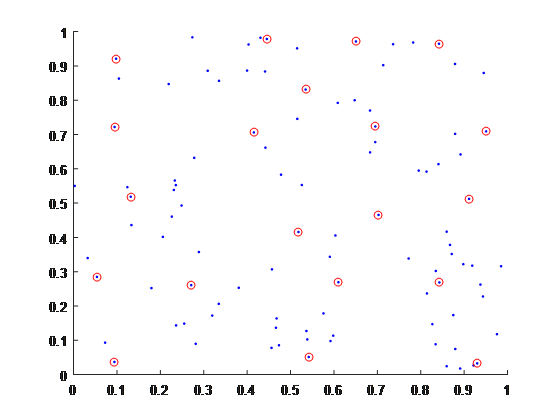
其核心函式為analyse_tpt_base:從若干個location中選擇出representativeNum個代表性點。
返回代表性點為picked_id,初始為空。
首先找出所有點的中心cent,距離cent最近的點放入picked_id。(knnsearch:返回距離某個點/某一組點最近的k個點序號)
而後,找出剩下的點。
對於每個點,找出所有點到現有picked_id的距離的最短距離。這個距離最大的點,認為和現有的點最不相似,放入picked_id中。下圖是從100個隨機點中選擇10個代表點。
返回的序號是從外圍到中心。最後一個點是最開始找出的cent。
|
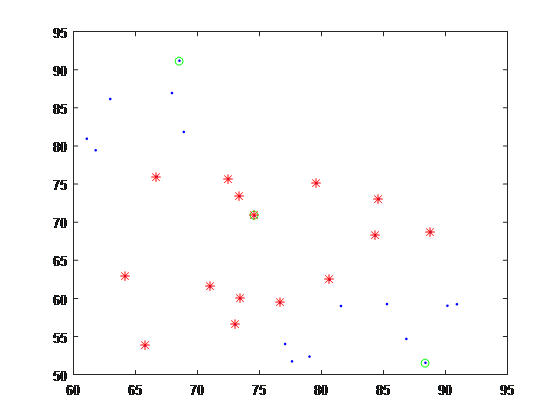
% Step A: For all locations |
|
pA:從location中找出的representativeNum1個代表性點序號(綠圈)。 capital_id:如果一個location點到pA所有點的距離。如果距離最近的點是pA的最後一點,則返回該location的序號(紅圈)。由於pA是按照從外圍到中心排列,的capital_id中包含location中中心部分的點。 |
|
% Step B: For capital location in Step A |
|
pB:從capital_id的店中,找出represntativeNum2+1個代表性點。由於最後一個點返回的中心和pA的相同,所以要多找一個。 |
|
% Merge and get assign |
|
picked_id:pA和pB拼合,去除重複的中心點。 assign:location到picked_id中最近的picked_id序號。相當於把location分配給這些代表性點。 |

referenceP.m
先計算包含紋理資訊的後驗概率,而後計算只由形狀決定的先驗概率。
|
% 輸入 |
|
|
images:對齊的影象。數量為M。 model:semantic點紋理->偏移的SVC模型,semantic點代表性位置representativeLocation,點偏移量的PCA模型 currentPose:當前形狀。數量為M。訓練時等於為訓練集樣本數N。測試時為測試集樣本數。 level:外層迭代次數,用於確定引數 probsInfo:引數 tpt:標定的目標形狀(targetPose)。數量為訓練集樣本數記為N。 |
|
|
% Validation over currentPose |
|
|
feat_current:當前形狀semantic點上的3尺度SIFT特徵。高為M,寬為128*15*3 = 5760。 scoring_board:長度=semantic點數。每個cell中是M*N,表示第i測試樣本和第j訓練樣本相似程度。 Pr:M*N*25,其中25為15個semantic點和10個fix點(人臉圖綠色點)。概率拆解為關鍵點概率的連乘。 record_point:M*(2*25)。semantic點和fix點。 record_mask:M*25。沒用。 |
|
|
for i = 1:length(semantic_id) % 處理全部當前形狀的第i個semantic點。 |
|
|
% 靠譜的用當前形狀,不靠譜的用模型中的代表性點 |
|
|
confidence_current:從feat_curretn中找出當前點對應的特徵,用model中的SVC模型,預測一個置信度。第一列為結果:離真實位置近,為1;離真實位置遠,為0;第二列為accuracy,刪除不用。 ind:當前形狀中置信度>=acceptThre=0.9的點序號。這些樣本離真實值足夠近。數量設為M1。 |
|
|
% for only current |
|
|
dX, dY:M1個當前正確形狀到目標形狀tpt的偏差。M1*N。 scoring_board{i}: 用M1個形狀偏差dX,dY的高斯 函式計算。其方差為預設的gamma_current。填入scoring_board{i}對應的測試樣本行內。 record_point:把當前形狀對應點,填入record_point中,semantic部分的對應位置。 |
|
|
ind:當前形狀中置信度<acceptThre=0.9的點序號。數量設為M2。M1+M2 = M |
|
|
% for considering resamping |
|
|
feat_search:M2個偏差形狀,第i個點的representativeLocation(共20個樣本)上提取的3級SIFT特徵。高度M2,寬度20*3*128 = 7680。 confidence_search:代表性點的置信度。用model中的SVC模型,預測feat_search。結果小於0.5的置為0,按行歸一化。M2*20。 searched_point:confidence_search(M2*20)*representativeLocation(20*2)。代表性點,用置信度加權的平均值。M2*2。 scoring_board{i}, record_point:同前處理。填入相應位置內。 |
|
|
Pr:把i對應的概率賦值為scoring_board{i} |
|
|
for i = 1:length(fix_id) |
|
|
record_point:把當前形狀的對應點填入 dX, dY:當前形狀到目標形狀偏差 Pr:用dX, dY計算的高斯概率。 |
|
|
連乘Pr的第三維,得到M*N的矩陣。此時得到的Pr為論文中概率第二項:和紋理相關的後驗概率。 |
|
|
% Multiply the prior |
|
|
for i = 1:m % 對於每個當前形狀 |
|
|
d:第i個當前形狀到目標形狀偏差。N*(2*L) d_pca:用模型中的PCA對d進行投影。N*(2*17)。 prior:每一行(1*N) = d_pca自身數乘,而後對第二維求和。相當於在投影后空間裡,到原點的距離。 |
|
|
prior:用高斯函式計算。方差為gamma_prior。 Pr:用Pr(後驗)乘上prior(先驗)。之後歸一化。 |
|
|
% 返回 |
|
|
Pr:M*N矩陣。第i個當前形狀等於第j個訓練集形狀的概率。 |
|
====測試部分===============
inferenceCFSS.m為核心訓練檔案。
測試單張圖片相當慢,超過5s,和論文所述25fps不符。不知是否並行未啟動所致。
如果更改了11行的測試資料數量,則末尾再次載入資料也要相應更改。
佔用記憶體較大,即使是隻測試2個樣本,在家用PC上也會有low memory警報。
inferenceCFSS
和訓練流程非常相似。
|
載入各種資料,模型 m:測試樣本數 mt:訓練樣本數 |
|
|
for level = 1:stageTot |
|
|
% 61. Re-trans |
|
|
testingsetGeneration:利用影象旋轉回歸器生成對齊的影象images,以及對齊的剛性形變T。 Pr:m×mt,設定為均勻分佈。 |
|
|
% 62. from Pr to sub-region center |
|
|
currentPose:m×(2L)。通過inferenceReg函式從Pr估計初始形狀,用迴歸器進行迭代。 T:記錄當前形狀到平均形狀priorModel.referenceShape的變換 images:用上述變換繼續對影象進行矯正。下圖示出迭代三次影象的變化。 currentPose:用上述變換對當前形狀進行矯正。 |
|
|
% 63. from sub-region center to Pr |
|
|
Pr:通過inferenceP函式,計算當前影象上,訓練樣本的概率分佈。 |
|
|
estimatedPose:用各次迭代記錄的變換T把currentPose反變換回去。 |
|
|
最後計算估計值estimatedPose和真實值data的誤差,用瞳距歸一化。 |
|
testingsetGeneration
和訓練流程中預處理部分很像。只在第一次迭代呼叫
|
m:測試樣本數 p:m×8,平均simple_face(眼角嘴角),數量和測試樣本數相同 Tb:每個原始影象中simple face到標準simple shape的變換。只有平移縮放剪下,不包含旋轉。 images:原始灰度影象經過Tb的轉換,進行對齊。取代人臉框作用,不算作弊。 |
|
F:影象中部3*3網格中的HOG特徵,共279維。 predicted:樣本數*2。分別用兩個ensemble of bagged decision trees(記為priorModel.B),從特徵F預測本圖片的旋轉角度。 此處的B模型有兩個,各由一半訓練樣本生成。如果兩個預測結果角度之差<180°,則將兩個結果平均輸出;否則,直接輸出0°正臉。 另外設定了引數priorsInfo.predictedVoteThre。對預測結果絕對值進行限制。 Tr:預測角度的反旋轉。 |
|
T:縮放平移的Tb + 預測出的旋轉Tr images:經過T變換的影象 |
|
% 返回 |
|
歸一化影象images,歸一化變換T。 |
inferenceReg
|
m:測試樣本數 tpt:本次迭代的訓練集樣本:N*2L mt:訓練集樣本數 currentPose_inference:N*2L*取樣數(regsInfo.samplingTot,每級都是10)。初始形狀。第一次迭代時,均勻從訓練樣本中取;其他次迭代,先對Pr進行排序,而後取概率最大的訓練樣本。 |
|
|
% inference Iteration |
|
|
for iter = 1:iterTot % 4個迴歸,更新初始形狀 |
|
|
featOri_batch:樣本數*8704*取樣數。使用128*L = 8704維SIFT特徵。 currentPose_inference:形狀變化量如下計算:(feaOri – model.reg.mu) * model.reg.A + model.reg.b。 |
|
|
currentPose:通過poseVoting從10個currentPose_inference中得到加權平均值。迭代次數為regsInfo.dominantIterTot=100。 |
|
inferenceP
和訓練中的infereceP一樣。計算當前形狀currentPose在當前影象上,屬於訓練樣本的概率。