
從IA32到X86-64的擴充套件所導致的函式傳參棧模型的變化
先來看一段小程式
#include <stdio.h> int main(){ float f = 2.5; int i = 2; printf("%d\n%f\n%d\n%f\n\n", f, f, i, i); //printf("%d\n%f\n%f\n%d\n\n", f, f, i, i); //printf("%d\n%d\n%f\n%f\n\n", f, f, i, i); //printf("%f\n%f\n%d\n%d\n\n", f, f, i, i); //printf("%f\n%d\n%f\n%d\n\n", f, f, i, i); //printf("%f\n%d\n%d\n%f\n\n", f, f, i, i); return 0; }
這段程式的輸出是什麼呢?如果我們使用IA32的棧模型分析,就會是如下圖的樣子
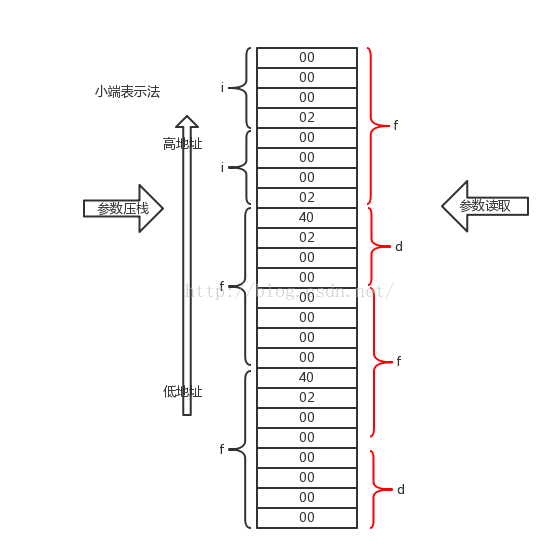
f=2.5本來應該是0X40200000,但是傳引數的時候浮點型別預設轉換為double變為0X4002000000000000(double和float的格式參考IEEE754),下面是在32-bit win7下面的彙編程式碼(intel格式):
00410970 push ebp 00410971 mov ebp,esp 00410973 sub esp,48h 00410976 push ebx 00410977 push esi 00410978 push edi 00410979 lea edi,[ebp-48h] 0041097C mov ecx,12h 00410981 mov eax,0CCCCCCCCh 00410986 rep stos dword ptr [edi] 4: 5: float f = 2.5; 00410988 mov dword ptr [ebp-4],40200000h 6: int i = 2; 0041098F mov dword ptr [ebp-8],2 7: printf("%d\n%f\n%d\n%f\n",f,f,i,i); 00410996 mov eax,dword ptr [ebp-8] 00410999 push eax 0041099A mov ecx,dword ptr [ebp-8] 0041099D push ecx 0041099E fld dword ptr [ebp-4] 004109A1 sub esp,8 004109A4 fstp qword ptr [esp] 004109A7 fld dword ptr [ebp-4] 004109AA sub esp,8 004109AD fstp qword ptr [esp] 004109B0 push offset string "a=%f,b=%d\n" (00427010) 004109B5 call printf (004010a0) 004109BA add esp,1Ch
如果是32-bit的平臺,那麼輸出就是按照上圖棧模型讀取引數,結果就是輸出0 0.000000 1074003968(0x40020000) 0.000000,浮點數之所以是0.000000,因為此時讀出來的都不是規格化的浮點數(IEEE規定浮點數階碼不為全0或全1時為規格化,全0時表示很接近0的非規格化數,全1表示其他的),這裡的兩個浮點數都是接近0的很小的數,精度有限,直接輸出0.000000
在X86-64平臺下是不是這樣的呢?結果出乎意料,能輸出正確的結果:
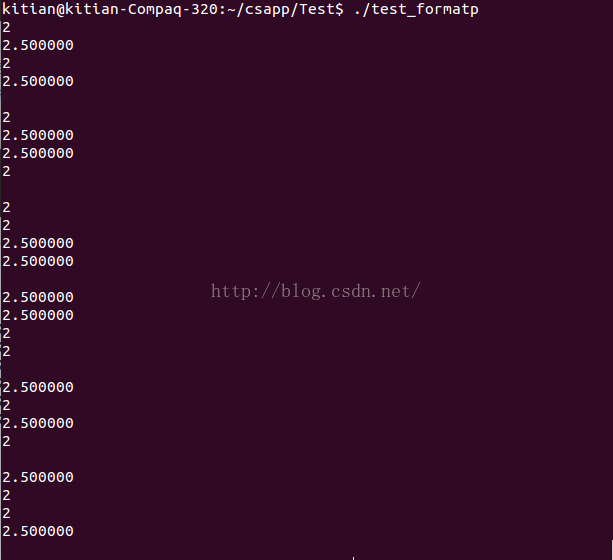
從上面看出,不管怎麼輸出,都能找到2.5和2,就好象不是從棧中取出來一樣。說明X86-64並不和IA32一樣,看一下彙編程式碼(ubuntu14.04 gcc)(AT&T格式):
基本上完全不一樣,沒有嚴格按照順序將引數壓棧,經查證,X86-64擴充套件了IA32的暫存器數目,並且帶浮點運算的程式會用到專用的浮點運算協處理器(包括SSE,%xmm暫存器等),這個可以查閱amd64 ABI文件。規定整數型別的引數通過暫存器%rdi %rsi %rdx %rcx %r8 %r9來傳遞,多餘的引數通過棧來傳遞。浮點型別的引數通過%xmm0~%xmm7來傳遞。因此這裡的兩個i分別傳遞給%esi %edx (第一個字串地址傳遞給%edi),兩個f分別傳遞給%xmm0和xmm1,%eax表示使用的%xmm暫存器的個數。所以,printf並不從棧中取引數,而是直接從指定暫存器中取,因此,這裡不管前面的格式化串如何,只用是按兩個d和兩個f來,他都會通過找%esi和%edx以及%xmm0和%xmm1來讀取引數,編譯器會對printf的引數進行優化和重新排列,printf對格式化串兒的解析過程只會按順序看有哪幾個整數哪幾個浮點數,預設程式設計師給出前後匹配的引數。並且一般不匹配的時候,編譯器會給出警告,但是不負責當錯誤來處理。.file "test_formatp.c" .section .rodata .LC1: .string "%d\n%f\n%d\n%f\n\n" .text .globl main .type main, @function main: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 subq $16, %rsp movl .LC0(%rip), %eax movl %eax, -8(%rbp) movl $2, -4(%rbp) movss -8(%rbp), %xmm1 cvtps2pd %xmm1, %xmm1 movss -8(%rbp), %xmm0 cvtps2pd %xmm0, %xmm0 movl -4(%rbp), %edx movl -4(%rbp), %eax movl %eax, %esi movl $.LC1, %edi movl $2, %eax call printf movl $0, %eax leave .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size main, .-main .section .rodata .align 4 .LC0: .long 1075838976 .ident "GCC: (Ubuntu 4.8.4-2ubuntu1~14.04) 4.8.4" .section .note.GNU-stack,"",@progbits

有了以上分析,我們再看看下面這個例子:
#include <stdio.h>
int main(){
int a = 10, d = 100;
float f = 2.5;
printf("f=%f,d=%d\n", f, d);
printf("f=%f,d=%f\n", f, d);
printf("f=%d,d=%d\n", f, d);
printf("f=%d,d=%f\n", f, d);
return 0;
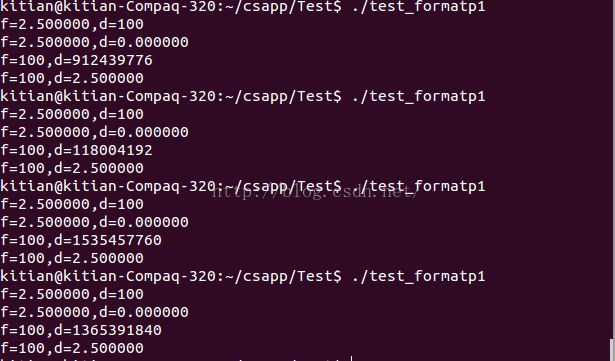
}f=2.500000,d=100
f=2.500000,d=0.000000
f=0,d=1074003968
f=0,d=0.000000
在ubuntu14.04 X86-64下面輸出第一個列印和第四個列印肯定是f=2.500000(%xmm0),d=100(%esi)和f=100(%esi),d=2.500000(%xmm0);第二個列印f=2.500000(%xmm0),d=?(%xmm1);第三個列印f=100(%esi),d=?(%edx);
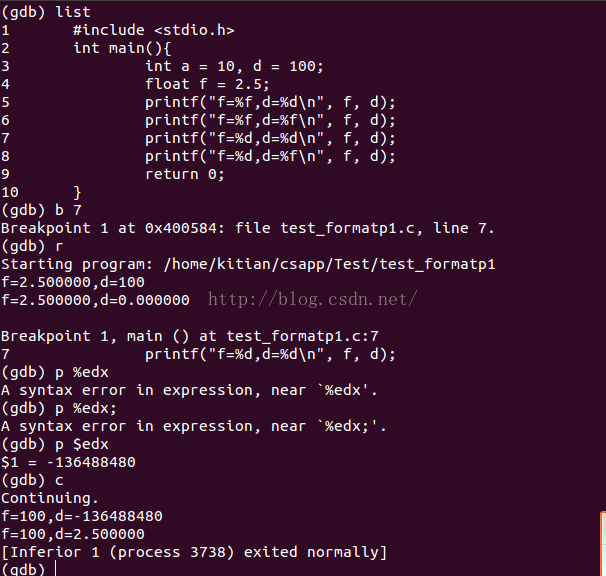
第三個列印的d的確是從%edx取出的,而%edx並沒有用於傳遞真實的d,因此打印出隨機的結果。以下是除錯時候的驗證結果:
綜上所述,對於不同的平臺(32-bit和64-bit cpu OS以及不同的編譯環境),函式的傳參模型並不像書本上講的那樣死板,特別是64-bit處理器的使用,暫存器的擴充套件,編譯器已經充分對程式碼做了底層優化來使用擴充套件的計算能力(包括SSE)。
1.對於32-bit平臺,可以使用傳統的棧模型來分析引數傳遞過程。
2.對於64-bit平臺,需要了解ABI以及相關文件,檢視傳參模型。如本例中的AMD64 ABI 就規定整數型別的引數通過暫存器%rdi %rsi %rdx %rcx %r8 %r9來傳遞,多餘的引數通過棧來傳遞。浮點型別的引數通過%xmm0~%xmm7來傳遞。
參考:
《深入理解計算機系統》
http://blog.codinglabs.org/articles/trouble-of-x86-64-platform.html