
boost log庫使用 十二 架構研究和主要使用總結
架構
下面是boost log庫的架構圖:
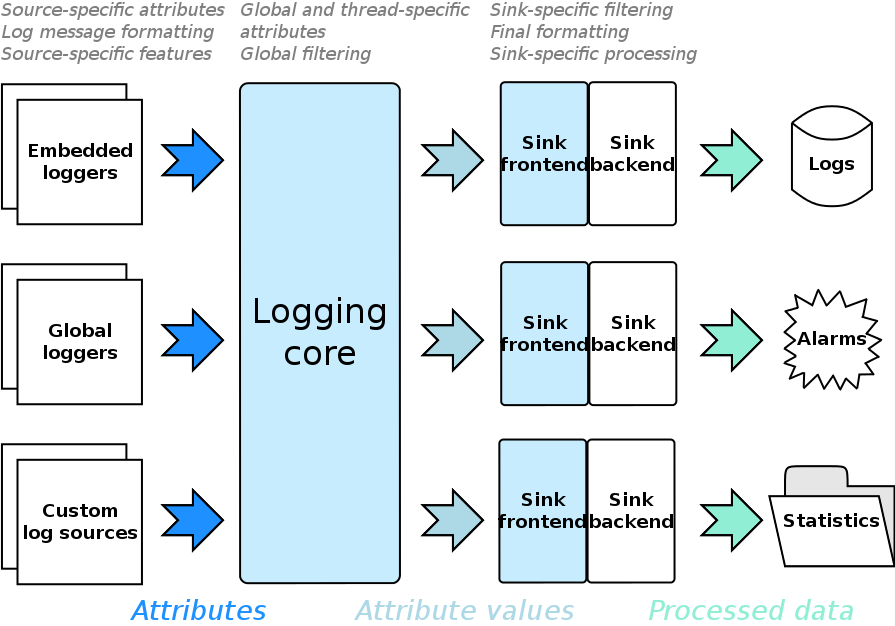
簡單使用
下面總結一下和這個架構相關的知識:
如何獲得Logging core
#include <boost/log/core.hpp>
...
boost::shared_ptr<logging::core> core = logging::core::get();
如何安裝Sink物件
一個core可以安裝多個Sink,下面的程式碼假定已經有了兩個Sink物件,將其安裝到core中
core->add_sink(sink1);
...
core->add_sink(sink2);如何建立一個Sink物件
需要先建立一個backend物件,然後在建立sink物件的時候,將backend物件傳遞給它。
typedef sinks::synchronous_sink<sinks::text_file_backend> TextSink; // init sink1 boost::shared_ptr<sinks::text_file_backend> backend1 = boost::make_shared<sinks::text_file_backend>( keywords::file_name = "sign_%Y-%m-%d_%H-%M-%S.%N.log", keywords::rotation_size = 10 * 1024 * 1024, keywords::time_based_rotation = sinks::file::rotation_at_time_point(0, 0, 0), keywords::min_free_space = 30 * 1024 * 1024); boost::shared_ptr<TextSink> sink1(new TextSink(backend1));
如何建立一個backend物件
指定frontend型別
前面的程式碼中已經演示,注意backend的型別需要制定一個frontend型別作為其模板類。因此,當建立一個backend物件的時候,已經確定了frontend。
這個frontend模板可以用synchronous_sink類,也可以用asynchronous_sink, 後者不會阻塞呼叫程式,會額外的建立執行緒去處理log,不過會慢點,記憶體消耗大點。一般都推薦先用後者。
用keywords構造引數
這裡看到一個概念:keywords. 在boost/log/keywords/目錄下27個hpp檔案:
auto_flush.hpp facility.hpp ident.hpp log_source.hpp open_mode.hpp rotation_size.hpp target.hpp channel.hpp file_name.hpp ip_version.hpp max_size.hpp order.hpp scan_method.hpp time_based_rotation.hpp delimiter.hpp filter.hpp iteration.hpp message_file.hpp ordering_window.hpp severity.hpp use_impl.hpp depth.hpp format.hpp log_name.hpp min_free_space.hpp registration.hpp start_thread.hpp
keywords是boost庫的基本概念,設計到一個巨集BOOST_PARAMETER_KEYWORD,定義在boost/parameter/keywords.hpp檔案中, 主要作用就是在指定的namespace中建立一個singleton的物件。所以上面的幾行keywords:: 程式碼就是給keywords namespace下面的幾個singleton物件file_name, rotation, time_based_rotation和min_free_space賦值。關鍵是要看看下面這個類的建構函式如何使用這些keywords.
sinks::text_file_backend參考文件:
注意,text_file_backend的建構函式語法上支援變參,但是語義上只支援有限的keywords:
template< typename ArgsT >
void construct(ArgsT const& args)
{
construct(
filesystem::path(args[keywords::file_name | filesystem::path()]),
args[keywords::open_mode | (std::ios_base::trunc | std::ios_base::out)],
args[keywords::rotation_size | (std::numeric_limits< uintmax_t >::max)()],
args[keywords::time_based_rotation | time_based_rotation_predicate()],
args[keywords::auto_flush | false]);
}文件中也的確如此描述。但是在text_file_backend.hpp檔案中發現還是有關於min_free_space的程式碼:
namespace aux {
//! Creates and returns a file collector with the specified parameters
BOOST_LOG_API shared_ptr< collector > make_collector(
filesystem::path const& target_dir,
uintmax_t max_size,
uintmax_t min_free_space
);
template< typename ArgsT >
inline shared_ptr< collector > make_collector(ArgsT const& args)
{
return aux::make_collector(
filesystem::path(args[keywords::target]),
args[keywords::max_size | (std::numeric_limits< uintmax_t >::max)()],
args[keywords::min_free_space | static_cast< uintmax_t >(0)]);
}
} // namespace aux所以估計還是可以使用target, max_size 和 min_free_space這些keywords. 以後試了就知道了。
target今天在libs/log/example/rotating_file裡面看到target的使用。也就是旋轉產生的日誌會放到target指定的目錄下,下面是例子程式碼:
// Create a text file sink
typedef sinks::synchronous_sink< sinks::text_file_backend > file_sink;
shared_ptr< file_sink > sink(new file_sink(
keywords::file_name = "%Y%m%d_%H%M%S_%5N.log", // file name pattern
keywords::rotation_size = 16384 // rotation size, in characters
));
// Set up where the rotated files will be stored
sink->locked_backend()->set_file_collector(sinks::file::make_collector(
keywords::target = "logs", // where to store rotated files
keywords::max_size = 16 * 1024 * 1024, // maximum total size of the stored files, in bytes
keywords::min_free_space = 100 * 1024 * 1024 // minimum free space on the drive, in bytes
));
// Upon restart, scan the target directory for files matching the file_name pattern
sink->locked_backend()->scan_for_files();
sink->set_formatter
(
expr::format("%1%: [%2%] - %3%")
% expr::attr< unsigned int >("RecordID")
% expr::attr< boost::posix_time::ptime >("TimeStamp")
% expr::smessage
);如何在sink中指定格式
下面到了指定日誌格式,這個需要在sink中指定,比如:
sink1->set_formatter (
expr::format("[%1%]<%2%>(%3%): %4%")
% expr::format_date_time< boost::posix_time::ptime>("TimeStamp", "%Y-%m-%d %H:%M:%S")
% expr::attr<sign_severity_level>("Severity")
% expr::attr<attrs::current_thread_id::value_type>("ThreadID")
% expr::smessage
);Boost::Format風格
這裡的關鍵是理解expr::format. 文件在這裡:http://www.boost.org/doc/libs/1_55_0/libs/log/doc/html/log/detailed/expressions.html#log.detailed.expressions.formatters我使用的是Boost::Format風格。下面這段程式碼表達了expr可以對某個屬性進行有無的判斷:
// Setup the common formatter for all sinks
logging::formatter fmt = expr::stream
<< std::setw(6) << std::setfill('0') << line_id << std::setfill(' ')
<< ": <" << severity << ">\t"
<< expr::if_(expr::has_attr(tag_attr))
[
expr::stream << "[" << tag_attr << "] "
]
<< expr::smessage;attributes
根據設計,日誌記錄是由attributes組成的,所以列印內容必須以attribute的方式傳給sink物件。
sink1->set_formatter (
expr::format("[%1%]<%2%>(%3%)(%4%): %5%")
% expr::attr<unsigned int>("LineID")
% expr::format_date_time< boost::posix_time::ptime >("TimeStamp", "%Y-%m-%d %H:%M:%S")
% expr::attr<sign_severity_level>("Severity")
% expr::attr<attrs::current_thread_id::value_type >("ThreadID")
% expr::smessage
);不要忘記新增commont attributes
logging::add_common_attributes();inline void add_common_attributes()
{
shared_ptr< core > pCore = core::get();
pCore->add_global_attribute(
aux::default_attribute_names::line_id(),
attributes::counter< unsigned int >(1));
pCore->add_global_attribute(
aux::default_attribute_names::timestamp(),
attributes::local_clock());
pCore->add_global_attribute(
aux::default_attribute_names::process_id(),
attributes::current_process_id());
#if !defined(BOOST_LOG_NO_THREADS)
pCore->add_global_attribute(
aux::default_attribute_names::thread_id(),
attributes::current_thread_id());
#endif
}高階使用
Name scope
Name scope也是前面格式的一種解決方案,但是由於它比較複雜,所以單獨描述。
stack element
named_scope_entry包含了scope_name, file_name和 line(原始碼行號), 每個stack element 就是一個name_scope_entry物件。
scope stack
最常見的是函式,此時scope stack就是函式棧。
boost log可以列印scope stack的資訊到日誌中
named_scope屬性
named scope屬性可以新增到全域性屬性中,這是執行緒相關的。新增屬性程式碼為:
logging::core::get()->add_global_attribute("Scope", attrs::named_scope());設定格式
下面是個簡單的例子:
首先設定格式的時候新增一種格式:
% expr::format_named_scope("Scopes", boost::log::keywords::format = "%n (%f : %l)")然後新增屬性:
core->add_global_attribute("Scopes", attrs::named_scope());之後呼叫程式碼中新增一個Bar和Foo函式,此處參考官方文件:http://www.boost.org/doc/libs/1_55_0/libs/log/doc/html/log/detailed/attributes.html#log.detailed.attributes.named_scope
void Bar() {
int x = 0;
}
void Foo(int n) {
src::severity_logger_mt<sign_severity_level>& lg = my_logger::get();
// Mark the scope of the function foo
BOOST_LOG_FUNCTION();
switch (n)
{
case 0:
{
// Mark the current scope
BOOST_LOG_NAMED_SCOPE("case 0");
BOOST_LOG(lg) << "Some log record";
Bar(); // call some function
}
break;
case 1:
{
// Mark the current scope
BOOST_LOG_NAMED_SCOPE("case 1");
BOOST_LOG(lg) << "Some log record";
Bar(); // call some function
}
break;
default:
{
// Mark the current scope
BOOST_LOG_NAMED_SCOPE("default");
BOOST_LOG(lg) << "Some log record";
Bar(); // call some function
}
break;
}
}最後在main.cc函式中呼叫:
Foo(1);執行結果:
[8]<2014-03-01 23:49:19>(0)(0x00007f21bf00e740)(void Foo(int) (./main.cc : 11)->case 1 (./main.cc : 27)): Some log record注意,上面的程式碼中用到兩個巨集:BOOST_LOG_NAMED_SCOPE和BOOST_LOG_FUNCTION。其實就是一個巨集,後面的巨集只是前面巨集的簡化版本,可以自動將當前函式作為scope name。定義在/boost/log/attributes/named_scope.hpp檔案
/*!
* Macro for function scope markup. The scope name is constructed with help of compiler and contains current function name.
* The scope name is pushed to the end of the current thread scope list.
*
* Not all compilers have support for this macro. The exact form of the scope name may vary from one compiler to another.
*/
#define BOOST_LOG_FUNCTION() BOOST_LOG_NAMED_SCOPE(BOOST_CURRENT_FUNCTION)/*!
* Macro for scope markup. The specified scope name is pushed to the end of the current thread scope list.
*/
#define BOOST_LOG_NAMED_SCOPE(name)\
BOOST_LOG_NAMED_SCOPE_INTERNAL(BOOST_LOG_UNIQUE_IDENTIFIER_NAME(_boost_log_named_scope_sentry_), name, __FILE__, __LINE__)#define BOOST_LOG_NAMED_SCOPE_INTERNAL(var, name, file, line)\
BOOST_LOG_UNUSED_VARIABLE(::boost::log::attributes::named_scope::sentry, var, (name, file, line));#if defined(__GNUC__)
//! The macro suppresses compiler warnings for \c var being unused
#define BOOST_LOG_UNUSED_VARIABLE(type, var, initializer) __attribute__((unused)) type var initializer
#else所以在FOO函式中使用BOOST_LOG_FUNCTION的時候,也就是寫下了這行程式碼:
__attribute__((unused)) ::boost::log::attributes::named_scope::sentry _boost_log_named_scope_sentry_18 (__PRETTY_FUNCTION__, "./main.cc", 18);;所以可以看到,這裡的程式碼行數是固定的18, 因此如果在記錄日誌時想要顯示程式碼的行數,寫入日誌時必須至少兩行巨集:
BOOST_LOG_FUNCTION 和 BOOST_LOG_SEV巨集。
Scoped Attribute
主要文件參考:
非同步日誌
如前面所述,一般推薦用非同步日誌,特別是最近對於高併發處理的伺服器來講,多一點點記憶體消耗不是問題,關鍵不能影響程式的正常邏輯的效能。
首先引入標頭檔案:
#include <boost/log/sinks/async_frontend.hpp>然後就是很簡單將sinks::synchronous_sink替換成sinks::asynchronous_sink即可。
但是這裡有個副作用,如果你想除錯的話,因為非同步日誌有一定的延遲,儘管用了se_auto_flush(true),也不會立刻看到日誌。
還有一些配置,可以參考文件:
注意一把推薦使用bounded和unbounded的區別。unbounded策略當日志非常多,backend來不及處理的時候,unbounded內部的佇列會變得非常大,如果出現這種情況,請用bounded進行限制。
旋轉日誌
其實前面例子程式碼中已經包含,因為這個比較常用,所以特別再提一下。下面是每月1日0點生成日誌:
boost::shared_ptr<sinks::text_file_backend> backend2 = boost::make_shared<sinks::text_file_backend>(
keywords::file_name = "sign_%Y-%m-%d.%N.csv",
keywords::time_based_rotation = sinks::file::rotation_at_time_point(boost::gregorian::greg_day(1), 0, 0, 0));下面是每小時生成日誌:
sinks::file::rotation_at_time_interval(posix_time::hours(1))filter
sink可以設定filter
filter可以過濾日誌級別,還可以更多,下面是個例子:
sink1->set_filter(expr::attr<sign_severity_level>("Severity") >= trace);高階filter的文件在這裡:
這裡sink的filter可以和scope聯合使用:
sink->set_filter(severity >= warning || (expr::has_attr(tag_attr) && tag_attr == "IMPORTANT_MESSAGE"));
...
{
BOOST_LOG_SCOPED_THREAD_TAG("Tag", "IMPORTANT_MESSAGE");
BOOST_LOG_SEV(slg, normal) << "An important message";
}sink的filter也可以使用phonex
bool my_filter(logging::value_ref< severity_level, tag::severity > const& level,
logging::value_ref< std::string, tag::tag_attr > const& tag)
{
return level >= warning || tag == "IMPORTANT_MESSAGE";
}
void init()
{
// ...
namespace phoenix = boost::phoenix;
sink->set_filter(phoenix::bind(&my_filter, severity.or_none(), tag_attr.or_none()));
// ...
}formatter也可以有自己的filter:
logging::formatter fmt = expr::stream
<< std::setw(6) << std::setfill('0') << line_id << std::setfill(' ')
<< ": <" << severity << ">\t"
<< expr::if_(expr::has_attr(tag_attr))
[
expr::stream << "[" << tag_attr << "] "
]
<< expr::smessage;一個backend輸出多個日誌檔案
根據attr的值生成多個日誌
我希望能夠某一個attributes的值進行區分,將一個日誌拆分成多個日誌。
首先要引入標頭檔案:
#include <boost/log/sinks/text_multifile_backend.hpp>void InitLog() {
boost::shared_ptr<logging::core> core = logging::core::get();
typedef sinks::synchronous_sink<sinks::text_multifile_backend> TextSink1;
// init sink1
boost::shared_ptr< sinks::text_multifile_backend > backend1 =
boost::make_shared< sinks::text_multifile_backend >();
// Set up the file naming pattern
backend1->set_file_name_composer
(
sinks::file::as_file_name_composer(expr::stream << "logs/" << expr::attr<sign_severity_level>("Severity") << ".log")
);
boost::shared_ptr<TextSink1> sink1(new TextSink1(backend1));
sink1->set_formatter (
expr::format("(%1%)(%2%)(%3%)(%4%)<%5%>: %6%")
% expr::attr<unsigned int>("LineID")
% expr::format_date_time< boost::posix_time::ptime >("TimeStamp", "%Y-%m-%d %H:%M:%S")
% expr::attr<sign_severity_level>("Severity")
% expr::attr<attrs::current_thread_id::value_type>("ThreadID")
% expr::format_named_scope("Scopes", boost::log::keywords::format = "%n (%f : %l)")
% expr::smessage
);
sink1->set_filter(expr::attr<sign_severity_level>("Severity") >= trace);
core->add_sink(sink1);執行的結果是log目錄下出現了下面的日誌:
[email protected]:~/work/gitlab_cloud/boost_log/sink/logs$ ls
0.log 1.log 2.log 3.log 4.log 5.log 6.log但是遺憾的是text_multifil_backend不支援旋轉日誌等text_file_backend的功能。text_file_backend建構函式支援很多的keywords.
而且請注意,這種機制不能根據smessage裡面的欄位來拆分日誌。如果想要這個,還是需要自己定義sink front-end的過濾器。
和scoped attributed聯合使用
參考boost log的例子,boost_1_55_0/libs/log/example/doc/sinks_multifile.cpp檔案中有如下程式碼:
void init_logging()
{
boost::shared_ptr< logging::core > core = logging::core::get();
boost::shared_ptr< sinks::text_multifile_backend > backend =
boost::make_shared< sinks::text_multifile_backend >();
// Set up the file naming pattern
backend->set_file_name_composer
(
sinks::file::as_file_name_composer(expr::stream << "logs/" << expr::attr< std::string >("RequestID") << ".log")
);
// Wrap it into the frontend and register in the core.
// The backend requires synchronization in the frontend.
typedef sinks::synchronous_sink< sinks::text_multifile_backend > sink_t;
boost::shared_ptr< sink_t > sink(new sink_t(backend));
// Set the formatter
sink->set_formatter
(
expr::stream
<< "[RequestID: " << expr::attr< std::string >("RequestID")
<< "] " << expr::smessage
);
core->add_sink(sink);
}
//]
void logging_function()
{
src::logger lg;
BOOST_LOG(lg) << "Hello, world!";
}
int main(int, char*[])
{
init_logging();
{
BOOST_LOG_SCOPED_THREAD_TAG("RequestID", "Request1");
logging_function();
}
{
BOOST_LOG_SCOPED_THREAD_TAG("RequestID", "Request2");
logging_function();
}
return 0;
}