
一篇文章讀懂分散式服務框架ZooKeeper
在SOA架構設計中。系統對於業務邏輯複用的需求十分強烈,上層業務都想借用已有的底層服務,來快速搭建更多,更豐富的業務。從而降低新業務開展的人力和時間成本,已快速滿足瞬息萬變的市場需求。而公共的業務被拆分出來,形成可共用的服務,最大程度地保障了程式碼和邏輯的複用,避免重複建設。因此,服務消費者要通過服務名稱,根據服務的路由,在眾多服務中找到要呼叫的服務的地址列表:
大致流程圖如下所示:
服務消費者 服務列表 地址列表
service1---> server_address1
service2 server_address2 而對於負載較高的服務來說,往往對應著多臺主機組成的服務叢集。在請求到來時,為了將請求均衡地分配到後端伺服器,負載均衡程式將從服務對應的地址列表中,通過負載均衡演算法和規則,選出一臺最佳的伺服器進行訪問,這個過程稱為負載均衡。
呼叫者 負載均衡演算法 地址列表
round_robin server_address1
consumer --->random 服務規模較小,可以採用硬編碼的方法將服務地址和配置寫在程式碼中,提高編碼解決服務的路由和負載均衡問題,也可以通過軟硬體負載均衡裝置LVS,Nginx等通過相關配置來解決服務的路由和負載均衡問題。
當服務的機器數量在可控範圍內,上述維護成功較低,配置也簡單明瞭,但當服務越來越多,規模越來越大時,機器數量越來越龐大,靠上述維護方案將會越來越困難並且單點故障的問題也開始凸顯,一旦服務路由或者負載均衡伺服器宕機,所有依賴於它的服務全部不可用。
service1--->負載均衡演算法-->xxxx(叢集)
consumer --->service2--->負載均衡演算法-->xxxx(叢集)
service3--->負載均衡演算法-->xxxx(叢集)
此時需要一個能夠動態註冊和獲取服務資訊的地方,來統一管理服務名稱和其對應的伺服器列表資訊,稱之為服務配置中心。當服務提供者在啟動時,將其提供的服務名稱,服務地址註冊到服務配置中心。服務消費者通過服務配置中心來獲得需要呼叫的服務的機器列表,通過負載均衡演算法。選出其中一臺伺服器進行呼叫。當伺服器宕機或者下線時,相應的機器需要能夠動態的從服務配置中心中移除。並通知相應的服務消費者,否則服務消費者就有可能因為呼叫到已失效的服務而發生錯誤。在這個過程中,服務消費者只有第一次呼叫服務時需要查詢服務配置中心然後將查詢到的資訊快取到本地,後面的呼叫直接使用本地快取的服務地址列表資訊,而不需要重新發起請求到服務配置中心去獲取相應的服務地址列表。直到服務的地址有變更(機器上線和下線)。這種無中心化的結構解決了之前負載均衡裝置所導致的單點故障問題並且大大減輕了服務配置中心的壓力。
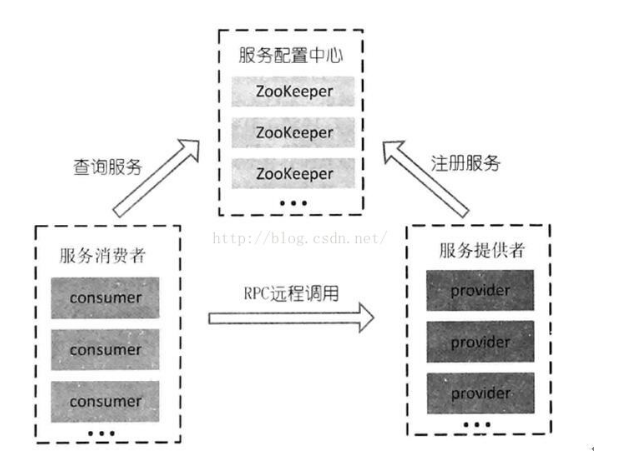
基於ZooKeeper的持久和非持久的特點,我們能夠近乎實時地感覺到後端服務的狀態(上線,下線,宕機)通過其叢集間的zab協議,使得服務配置資訊能夠保持一致。而zk本身的容錯特性和選舉機制能夠保障我們方便的進行擴容。通過zk來實現服務的動態註冊,機器上線和下線的動態感知,擴容方便容錯性好。且無中心化結構能夠解決之前使用負載均衡裝置所帶來的單機故障問題,只有當配置資訊更新時才回去zk上獲取最新的服務地址列表,其他的時候使用本地快取。
瞭解了zk之後,我們來看看zk的使用
關於zk的單機模式安裝與大部分軟體一樣,下載,解壓,修改環境變數。這裡不浪費篇幅了,也不浪費篇幅來寫配置檔案的含義了。只介紹幾個zk的關鍵特性和典型的應用場景:
資料模型
Zookeeper 分散式服務框架是 Apache Hadoop 的一個子專案,它主要是用來解決分散式應用中經常遇到的一些資料管理問題,如:統一命名服務、狀態同步服務、叢集管理、分散式應用配置項的管理等。
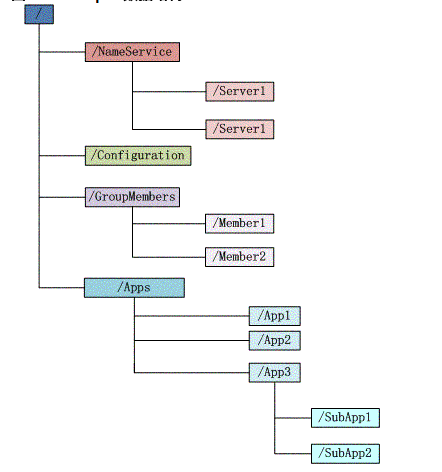
Zookeeper 會維護一個具有層次關係的資料結構,它非常類似於一個標準的檔案系統,如圖所示:
瞭解該資料介面特點前,先了解Zookeeper的節點型別:
持久節點(PERSISTENT)
所謂持久節點,是指在節點建立後,就一直存在,直到有刪除操作來主動清除這個節點——不會因為建立該節點的客戶端會話失效而消失。
持久順序節點(PERSISTENT_SEQUENTIAL)
這類節點的基本特性和上面的節點型別是一致的。額外的特性是,在ZK中,每個父節點會為他的第一級子節點維護一份時序,會記錄每個子節點建立的先後順序。基於這個特性,在建立子節點的時候,可以設定這個屬性,那麼在建立節點過程中,ZK會自動為給定節點名加上一個數字字尾,作為新的節點名。這個數字字尾的範圍是整型的最大值。
在建立節點的時候只需要傳入節點 “/test_”,這樣之後,zookeeper自動會給”test_”後面補充數字。
臨時節點(EPHEMERAL)
和持久節點不同的是,臨時節點的生命週期和客戶端會話繫結。也就是說,如果客戶端會話失效,那麼這個節點就會自動被清除掉。注意,這裡提到的是會話失效,而非連線斷開。另外,在臨時節點下面不能建立子節點。
這裡還要注意一件事,就是當你客戶端會話失效後,所產生的節點也不是一下子就消失了,也要過一段時間,大概是10秒以內,可以試一下,本機操作生成節點,在伺服器端用命令來檢視當前的節點數目,你會發現客戶端已經stop,但是產生的節點還在。
臨時順序節點(EPHEMERAL_SEQUENTIAL)
此節點是屬於臨時節點,不過帶有順序,客戶端會話結束節點就消失。可以利用該特性實現一個分散式鎖。
Zookeeper 這種資料結構有如下這些特點:
- 每個子目錄項如 NameService 都被稱作為 znode,這個 znode 是被它所在的路徑唯一標識,如 Server1 這個 znode 的標識為 /NameService/Server1
- znode 可以有子節點目錄,並且每個 znode 可以儲存資料,注意 EPHEMERAL 型別的目錄節點不能有子節點目錄
- znode 是有版本的,每個 znode 中儲存的資料可以有多個版本,也就是一個訪問路徑中可以儲存多份資料
- znode 可以是臨時節點,一旦建立這個 znode 的客戶端與伺服器失去聯絡,這個 znode 也將自動刪除,Zookeeper 的客戶端和伺服器通訊採用長連線方式,每個客戶端和伺服器通過心跳來保持連線,這個連線狀態稱為 session,如果 znode 是臨時節點,這個 session 失效,znode 也就刪除了
- znode 的目錄名可以自動編號,如 App1 已經存在,再建立的話,將會自動命名為 App2
- znode 可以被監控,包括這個目錄節點中儲存的資料的修改,子節點目錄的變化等,一旦變化可以通知設定監控的客戶端,這個是 Zookeeper 的核心特性,Zookeeper 的很多功能都是基於這個特性實現的,後面在典型的應用場景中會有例項介紹
如何使用
Zookeeper 作為一個分散式的服務框架,主要用來解決分散式叢集中應用系統的一致性問題,它能提供基於類似於檔案系統的目錄節點樹方式的資料儲存,但是 Zookeeper 並不是用來專門儲存資料的,它的作用主要是用來維護和監控你儲存的資料的狀態變化。通過監控這些資料狀態的變化,從而可以達到基於資料的叢集管理,後面將會詳細介紹 Zookeeper 能夠解決的一些典型問題,這裡先介紹一下,Zookeeper 的操作介面和簡單使用示例。
基本操作
客戶端要連線 Zookeeper 伺服器可以通過建立 org.apache.zookeeper. ZooKeeper 的一個例項物件,然後呼叫這個類提供的介面來和伺服器互動。
前面說了 ZooKeeper 主要是用來維護和監控一個目錄節點樹中儲存的資料的狀態,所有我們能夠操作 ZooKeeper 的也和操作目錄節點樹大體一樣,如建立一個目錄節點,給某個目錄節點設定資料,獲取某個目錄節點的所有子目錄節點,給某個目錄節點設定許可權和監控這個目錄節點的狀態變化。
public class App {
public static void main(String[] args) {
try {
// 建立一個與伺服器的連線
// 引數三 watch 引數4 canBeReadOnly
ZooKeeper zk = new ZooKeeper("localhost:2181", 2000, null, false);
// 建立一個目錄節點
/*
* 引數1 :節點路徑 引數2 :節點資料 引數3 :訪問許可權 Ids.OPEN_ACL_UNSAFE表示無許可權 引數4 :節點型別
* CreateMode.PERSISTENT持久節點,當該客戶端斷開連結時不會刪除節點
*/
zk.create("/testRootPath", "testRootData".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
// 建立一個子目錄節點
zk.create("/testRootPath/testChildPathOne", "testChildDataOne".getBytes(), Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
System.out.println(new String(zk.getData("/testRootPath", false, null)));
// 取出子目錄節點列表
System.out.println(zk.getChildren("/testRootPath", true));
// 修改子目錄節點資料
zk.setData("/testRootPath/testChildPathOne", "modifyChildDataOne".getBytes(), -1);
System.out.println("目錄節點狀態:[" + zk.exists("/testRootPath", true) + "]");
// 建立另外一個子目錄節點
zk.create("/testRootPath/testChildPathTwo", "testChildDataTwo".getBytes(), Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
System.out.println(new String(zk.getData("/testRootPath/testChildPathTwo", true, null)));
/*
* // 刪除子目錄節點 zk.delete("/testRootPath/testChildPathTwo",-1);
* zk.delete("/testRootPath/testChildPathOne",-1); // 刪除父目錄節點
* zk.delete("/testRootPath",-1); // 關閉連線 zk.close();
*/
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
對於生成ZooKeeper的例項,最後一個引數可以指定一個Watch:
ZooKeeper zk = new ZooKeeper("localhost:" + CLIENT_PORT,
ClientBase.CONNECTION_TIMEOUT, new Watcher() {
// 監控所有被觸發的事件
public void process(WatchedEvent event) {
System.out.println("已經觸發了" + event.getType() + "事件!");
}
});當對目錄節點監控狀態開啟時,一旦目錄節點的狀態發生變化,Watcher 物件的 process 方法就會被呼叫。
ZooKeeper 典型的應用場景
Zookeeper 從設計模式角度來看,是一個基於觀察者模式設計的分散式服務管理框架,它負責儲存和管理大家都關心的資料,然後接受觀察者的註冊,一旦這些資料的狀態發生變化,Zookeeper 就將負責通知已經在 Zookeeper 上註冊的那些觀察者做出相應的反應,從而實現叢集中類似 Master/Slave 管理模式。
下面詳細介紹這些典型的應用場景,也就是 Zookeeper 到底能幫我們解決那些問題?下面將給出答案。
統一命名服務(Name Service)
分散式應用中,通常需要有一套完整的命名規則,既能夠產生唯一的名稱又便於人識別和記住,通常情況下用樹形的名稱結構是一個理想的選擇,樹形的名稱結構是一個有層次的目錄結構,既對人友好又不會重複。說到這裡你可能想到了 JNDI,沒錯 Zookeeper 的 Name Service 與 JNDI 能夠完成的功能是差不多的,它們都是將有層次的目錄結構關聯到一定資源上,但是 Zookeeper 的 Name Service 更加是廣泛意義上的關聯,也許你並不需要將名稱關聯到特定資源上,你可能只需要一個不會重複名稱,就像資料庫中產生一個唯一的數字主鍵一樣。
Name Service 已經是 Zookeeper 內建的功能,你只要呼叫 Zookeeper 的 API 就能實現。如呼叫 create 介面就可以很容易建立一個目錄節點。
配置管理(Configuration Management)
配置的管理在分散式應用環境中很常見,例如同一個應用系統需要多臺 PC Server 執行,但是它們執行的應用系統的某些配置項是相同的,如果要修改這些相同的配置項,那麼就必須同時修改每臺執行這個應用系統的 PC Server,這樣非常麻煩而且容易出錯。
像這樣的配置資訊完全可以交給 Zookeeper 來管理,將配置資訊儲存在 Zookeeper 的某個目錄節點中,然後將所有需要修改的應用機器監控配置資訊的狀態,一旦配置資訊發生變化,每臺應用機器就會收到 Zookeeper 的通知,然後從 Zookeeper 獲取新的配置資訊應用到系統中。
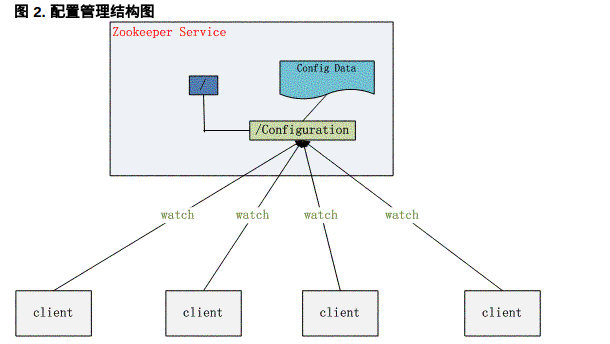
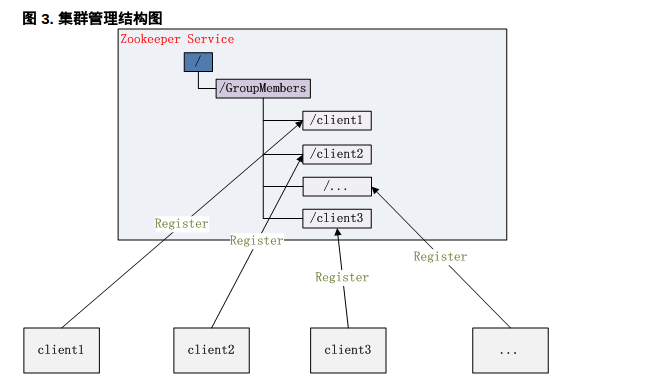
叢集管理(Group Membership)
Zookeeper 能夠很容易的實現叢集管理的功能,如有多臺 Server 組成一個服務叢集,那麼必須要一個“總管”知道當前叢集中每臺機器的服務狀態,一旦有機器不能提供服務,叢集中其它叢集必須知道,從而做出調整重新分配服務策略。同樣當增加叢集的服務能力時,就會增加一臺或多臺 Server,同樣也必須讓“總管”知道。
Zookeeper 不僅能夠幫你維護當前的叢集中機器的服務狀態,而且能夠幫你選出一個“總管”,讓這個總管來管理叢集,這就是 Zookeeper 的另一個功能 Leader Election。
它們的實現方式都是在 Zookeeper 上建立一個 EPHEMERAL 型別的目錄節點,然後每個 Server 在它們建立目錄節點的父目錄節點上呼叫 getChildren(String path, boolean watch) 方法並設定 watch 為 true,由於是 EPHEMERAL 目錄節點,當建立它的 Server 死去,這個目錄節點也隨之被刪除,所以 Children 將會變化,這時 getChildren上的 Watch 將會被呼叫,所以其它 Server 就知道已經有某臺 Server 死去了。新增 Server 也是同樣的原理。
Zookeeper 如何實現 Leader Election,也就是選出一個 Master Server。和前面的一樣每臺 Server 建立一個 EPHEMERAL 目錄節點,不同的是它還是一個 SEQUENTIAL 目錄節點,所以它是個 EPHEMERAL_SEQUENTIAL 目錄節點。之所以它是 EPHEMERAL_SEQUENTIAL 目錄節點,是因為我們可以給每臺 Server 編號,我們可以選擇當前是最小編號的 Server 為 Master,假如這個最小編號的 Server 死去,由於是 EPHEMERAL 節點,死去的 Server 對應的節點也被刪除,所以當前的節點列表中又出現一個最小編號的節點,我們就選擇這個節點為當前 Master。這樣就實現了動態選擇 Master,避免了傳統意義上單 Master 容易出現單點故障的問題。
Leader Election 關鍵程式碼:
void findLeader() throws InterruptedException {
byte[] leader = null;
try {
leader = zk.getData(root + "/leader", true, null);
} catch (Exception e) {
logger.error(e);
}
if (leader != null) {
following();
} else {
String newLeader = null;
try {
byte[] localhost = InetAddress.getLocalHost().getAddress();
newLeader = zk.create(root + "/leader", localhost,
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
} catch (Exception e) {
logger.error(e);
}
if (newLeader != null) {
leading();
} else {
mutex.wait();
}
}
}共享鎖(Locks)
共享鎖在同一個程序中很容易實現,但是在跨程序或者在不同 Server 之間就不好實現了。Zookeeper 卻很容易實現這個功能,實現方式也是需要獲得鎖的 Server 建立一個 EPHEMERAL_SEQUENTIAL 目錄節點,然後呼叫 getChildren方法獲取當前的目錄節點列表中最小的目錄節點是不是就是自己建立的目錄節點,如果正是自己建立的,那麼它就獲得了這個鎖,如果不是那麼它就呼叫 exists(String path, boolean watch) 方法並監控 Zookeeper 上目錄節點列表的變化,一直到自己建立的節點是列表中最小編號的目錄節點,從而獲得鎖,釋放鎖很簡單,只要刪除前面它自己所建立的目錄節點就行了。
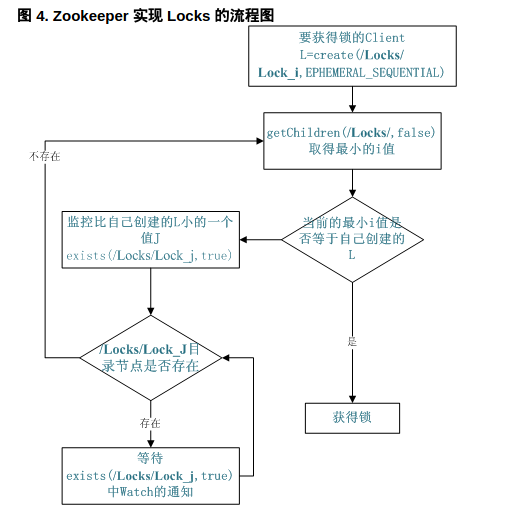
同步鎖的關鍵程式碼
void getLock() throws KeeperException, InterruptedException{
List<String> list = zk.getChildren(root, false);
String[] nodes = list.toArray(new String[list.size()]);
Arrays.sort(nodes);
if(myZnode.equals(root+"/"+nodes[0])){
doAction();
}
else{
waitForLock(nodes[0]);
}
}
void waitForLock(String lower) throws InterruptedException, KeeperException {
Stat stat = zk.exists(root + "/" + lower,true);
if(stat != null){
mutex.wait();
}
else{
getLock();
}
}佇列管理
Zookeeper 可以處理兩種型別的佇列:
- 當一個佇列的成員都聚齊時,這個佇列才可用,否則一直等待所有成員到達,這種是同步佇列。
- 佇列按照 FIFO 方式進行入隊和出隊操作,例如實現生產者和消費者模型。
同步佇列用 Zookeeper 實現的實現思路如下:
建立一個父目錄 /synchronizing,每個成員都監控標誌(Set Watch)位目錄 /synchronizing/start 是否存在,然後每個成員都加入這個佇列,加入佇列的方式就是建立 /synchronizing/member_i 的臨時目錄節點,然後每個成員獲取 / synchronizing 目錄的所有目錄節點,也就是 member_i。判斷 i 的值是否已經是成員的個數,如果小於成員個數等待 /synchronizing/start 的出現,如果已經相等就建立 /synchronizing/start。
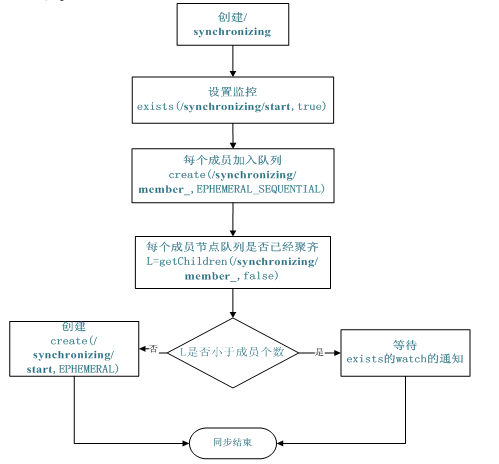
同步佇列
void addQueue() throws KeeperException, InterruptedException{
zk.exists(root + "/start",true);
zk.create(root + "/" + name, new byte[0], Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
synchronized (mutex) {
List<String> list = zk.getChildren(root, false);
if (list.size() < size) {
mutex.wait();
} else {
zk.create(root + "/start", new byte[0], Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
}
}
當佇列沒滿是進入 wait(),然後會一直等待 Watch 的通知,Watch 的程式碼如下:
public void process(WatchedEvent event) {
if(event.getPath().equals(root + "/start") &&
event.getType() == Event.EventType.NodeCreated){
System.out.println("得到通知");
super.process(event);
doAction();
}
}FIFO 佇列用 Zookeeper 實現思路如下:
實現的思路也非常簡單,就是在特定的目錄下建立 SEQUENTIAL 型別的子目錄 /queue_i,這樣就能保證所有成員加入佇列時都是有編號的,出佇列時通過 getChildren( ) 方法可以返回當前所有的佇列中的元素,然後消費其中最小的一個,這樣就能保證 FIFO。
下面是生產者和消費者這種佇列形式的示例程式碼:
生產者程式碼
boolean produce(int i) throws KeeperException, InterruptedException{
ByteBuffer b = ByteBuffer.allocate(4);
byte[] value;
b.putInt(i);
value = b.array();
zk.create(root + "/element", value, ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT_SEQUENTIAL);
return true;
} 消費者程式碼
int consume() throws KeeperException, InterruptedException{
int retvalue = -1;
Stat stat = null;
while (true) {
synchronized (mutex) {
List<String> list = zk.getChildren(root, true);
if (list.size() == 0) {
mutex.wait();
} else {
Integer min = new Integer(list.get(0).substring(7));
for(String s : list){
Integer tempValue = new Integer(s.substring(7));
if(tempValue < min) min = tempValue;
}
byte[] b = zk.getData(root + "/element" + min,false, stat);
zk.delete(root + "/element" + min, 0);
ByteBuffer buffer = ByteBuffer.wrap(b);
retvalue = buffer.getInt();
return retvalue;
}
}
}
}總結
Zookeeper 作為 Hadoop 專案中的一個子專案,是 Hadoop 叢集管理的一個必不可少的模組,它主要用來控制叢集中的資料,如它管理 Hadoop 叢集中的 NameNode,還有 Hbase 中 Master Election、Server 之間狀態同步等。
本文介紹的 Zookeeper 的基本知識,以及介紹了幾個典型的應用場景。這些都是 Zookeeper 的基本功能,最重要的是 Zoopkeeper 提供了一套很好的分散式叢集管理的機制,就是它這種基於層次型的目錄樹的資料結構,並對樹中的節點進行有效管理,從而可以設計出多種多樣的分散式的資料管理模型,而不僅僅侷限於上面提到的幾個常用應用場景。