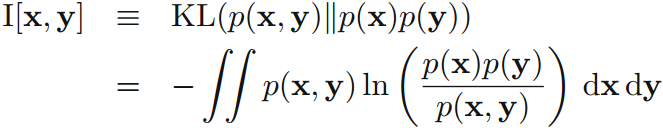模式識別與機器學習(一):概率論、決策論、資訊理論
阿新 • • 發佈:2019-01-03
本系列是經典書籍《Pattern Recognition and Machine Learning》的讀書筆記,正在研讀中,歡迎交流討論。
5. 強化學習(reinforcement learning) 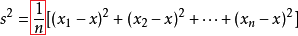
協方差(covariance): 。
而貝葉斯學派認為:引數w的值不是固定的,引數本身存在概率分佈,而資料集(觀測值)是固定的。
4 貝葉斯方法
在多項式曲線擬合中,我們假設似然函式和先驗分佈服從高斯分佈:
似然函式:
。
而貝葉斯學派認為:引數w的值不是固定的,引數本身存在概率分佈,而資料集(觀測值)是固定的。
4 貝葉斯方法
在多項式曲線擬合中,我們假設似然函式和先驗分佈服從高斯分佈:
似然函式:
期望損失為: 表示正確的類,而
表示正確的類,而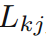 表示把屬於類k的資料判斷為類j的代價。
3. 拒絕選擇(the reject option):
當推理得到的最大後驗概率不夠大,難以判斷時,則應該拒絕進行判斷,另行處理(例如:由人工判斷)。
4. 推理(inference)和決策(decision)
(1)生成式模型(generative models):對聯合概率
表示把屬於類k的資料判斷為類j的代價。
3. 拒絕選擇(the reject option):
當推理得到的最大後驗概率不夠大,難以判斷時,則應該拒絕進行判斷,另行處理(例如:由人工判斷)。
4. 推理(inference)和決策(decision)
(1)生成式模型(generative models):對聯合概率 建模,可通過Bayes定理得到後驗概率,再決策。(聯合概率有多種用途,例如生成新的近似資料)
(2)判別式模型(discriminative models):直接對後驗概率
建模,可通過Bayes定理得到後驗概率,再決策。(聯合概率有多種用途,例如生成新的近似資料)
(2)判別式模型(discriminative models):直接對後驗概率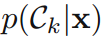 進行建模,一般比生成式模型的效能更好。
(可考慮組合使用生成式和判別式)
進行建模,一般比生成式模型的效能更好。
(可考慮組合使用生成式和判別式)
(3)判別函式(discriminant function):構建直接將輸入對映到輸出的函式。 (例如,小於x0則屬於類A,大於等於x0則屬於類B) 判別函式的不足: (1)若損失矩陣發生改變,則需要重新訓練函式; (2)因為判別函式不涉及概率,不能進行拒絕選擇; (3)若資料集中某一類的概率非常小,則訓練得到的判別函式不準確; (4)若有多個子任務,用判別函式則不能有效組合多個子任務的結果,從而不能有效進行有效的最終結果判斷。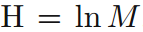 。
(每個資訊出現的概率越不確定,熵的值越大,資訊量也越大)
2.
條件熵(conditional entropy)
。
(每個資訊出現的概率越不確定,熵的值越大,資訊量也越大)
2.
條件熵(conditional entropy)
基本概念
1. 模式識別(Pattern Recognition):是指通過演算法自動發現數據的規律,並進行資料分類等任務。 2. 泛化(generalization):是指對與訓練集資料不同的新樣本進行正確分類的能力。(模式識別的主要目標) 3. 分類(classification):將輸入資料分到有限個數的類別中。 4. 迴歸(regression):預測輸入資料對應的輸出值,該輸出值由一個或多個連續變數的值組成。5. 強化學習(reinforcement learning)
8. 在多項式曲線擬合中,多項式的階數越高,引數的值也會越高。 當階數過大時,將導致過擬合,此時引數的值非常大(正值)或非常小(負值),使擬合曲線出現很大的振盪。 解決過擬合的方法之一是:正則化,避免參數值過大或過小。正則化引數(懲罰項)越大,引數值越小。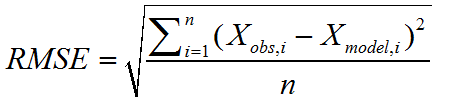
概率理論
模式識別中的不確定性(uncertainty)一方面由於資料集的大小有限,另一方面是由於噪音。 概率規則: 加法規則(sum rule):乘法規則(product rule):(marginal probability,邊緣概率)
1 貝葉斯理論(Bayes's theorem):(joint probability,聯合概率)
邊緣概率可用加法規則計算:

先驗概率(prior probability):某個類發生的概率(主觀)。 後驗概率(posterior probability):給定輸入資料,其被分到某一類的概率。 2 期望與方差 條件期望(conditional expectation)=函式值 x 函式值發生的概率:
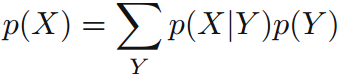
方差(variance):函式值和期望值的偏差的平方的期望值
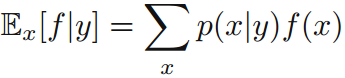
對照:
協方差(covariance):
3 貝葉斯學派 vs. 頻率學派
頻率學派認為:引數w雖然是未知的,但引數值是固定的,所以重點在於求取似然函式
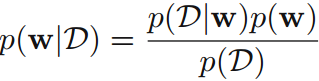
先驗分佈:
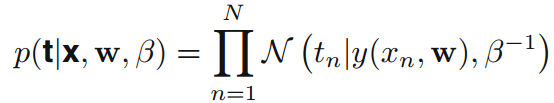
在訓練集中通過最大化後驗分佈(MAP)求引數值:

等價於最小化以下公式:
該公式等價於正則化的誤差函式平方和公式:

正則化引數等價於:
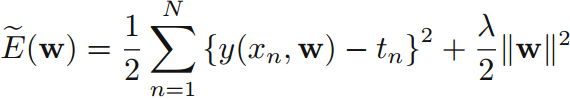
(MAP中已經包含了正則化項,也能解決over-fitting的問題) 5 預測分佈(predictIve distribution) 在測試集中,預測分佈為:
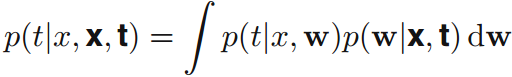
模型選擇
交叉驗證: (1)S-fold cross-validation:將資料集分成S份,取其中的一份作為驗證集,剩下的S-1份作為訓練集;驗證S次,每次取一份不同的驗證集。 (2)leave-one-out:沒份資料集剛好只有一個數據,適用於資料集稀少的情況。 不足:(1)訓練次數隨著S的取值增加,而某些情況下訓練一次的計算開銷就很大; (2)不同引數的組合設定將可能導致訓練次數的指數級增加。The Curse of Dimensionality
(1)計算複雜度; (2)不是所有低維空間的直觀都能泛化到高維空間中去。 P(X=x1)是概率質量函式(probability mass function),當且僅當,X是離散變數。 P(X=x1)是概率密度函式(probability density function),當且僅當,X是連續變數。決策理論
1. 最小化誤分類率(the misclassification rate)對於多類情況,則相當於:

2. 最小化期望損失(the expected loss) 不同的錯誤造成損失的不同,損失矩陣舉例:
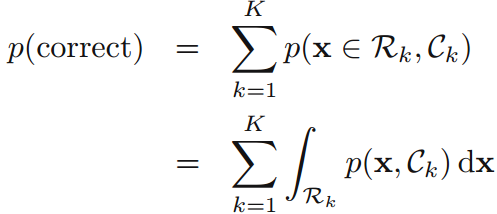
(矩陣說明:例如第一行“cancer”和第二列“normal”對應的值為1000,表示癌症患者被判定為正常的損失值為1000)
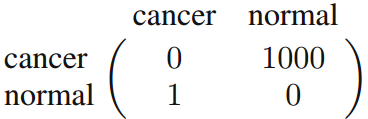
期望損失為:
其中,

(3)判別函式(discriminant function):構建直接將輸入對映到輸出的函式。 (例如,小於x0則屬於類A,大於等於x0則屬於類B) 判別函式的不足: (1)若損失矩陣發生改變,則需要重新訓練函式; (2)因為判別函式不涉及概率,不能進行拒絕選擇; (3)若資料集中某一類的概率非常小,則訓練得到的判別函式不準確; (4)若有多個子任務,用判別函式則不能有效組合多個子任務的結果,從而不能有效進行有效的最終結果判斷。
資訊理論
1.熵(Entropy)表示了資訊的不確定性(隨機變數傳遞的平均資訊量): 若變數x和y相互獨立,則資訊量h(x):出現該資訊所對應的聯合概率:
則資訊量可被表示為:
那麼熵則被表示為資訊量的期望值:
可證明,當所有資訊發生的概率都相等時,熵H最大,且最大值
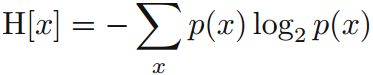
以離散變數為例證明條件熵公式:
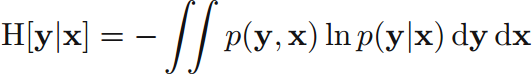
3. 相對熵(relative entropy)和互資訊(mutual information) KL散度(KL divergence):

其中,q(x)是p(x)的近似分佈。 可由Jensen不等式(凸函式的性質):
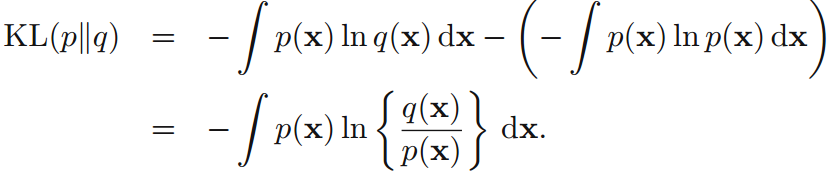
證明:或
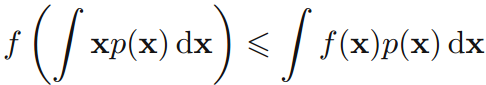
當且僅當q(x)=p(x)時,KL散度為零。即,KL散度可用於表示兩個分佈p(x)和q(x)的不相似性。 若兩個變數x,y不相互獨立,為了測試其不相互獨立的程度,引出互資訊:
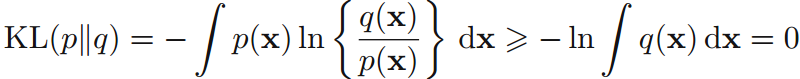
當且僅當p(x, y) = p(x)p(y),即x和y相互獨立時,互資訊為零。 所以,互資訊可用來表示兩個變數的獨立性,也可表示在給定變數y的情況下,變數x的不確定性的減少量。 (例如:先驗分佈和後驗分佈)