資料增強及預處理
阿新 • • 發佈:2019-01-03
一、資料增強
- 深層神經網路一般都需要大量的訓練資料才能獲得比較理想的結果。在資料量有限的情況下,可以通過資料增強(Data Augmentation)來
增加訓練樣本的多樣性, 提高模型魯棒性,避免過擬合。- 圖片資料增強通常只是針對訓練資料,對於測試資料則用得較少。
後者常用的是:做 5 次隨機剪裁,然後將 5 張圖片的預測結果做均值。
- 翻轉(Flip):將影象沿水平或垂直方法隨機翻轉一定角度;
- 旋轉(Rotation):將影象按順時針或逆時針方向隨機旋轉一定角度;
- 平移(Shift):將影象沿水平或垂直方法平移一定步長;
- 縮放(Resize):將影象放大或縮小;
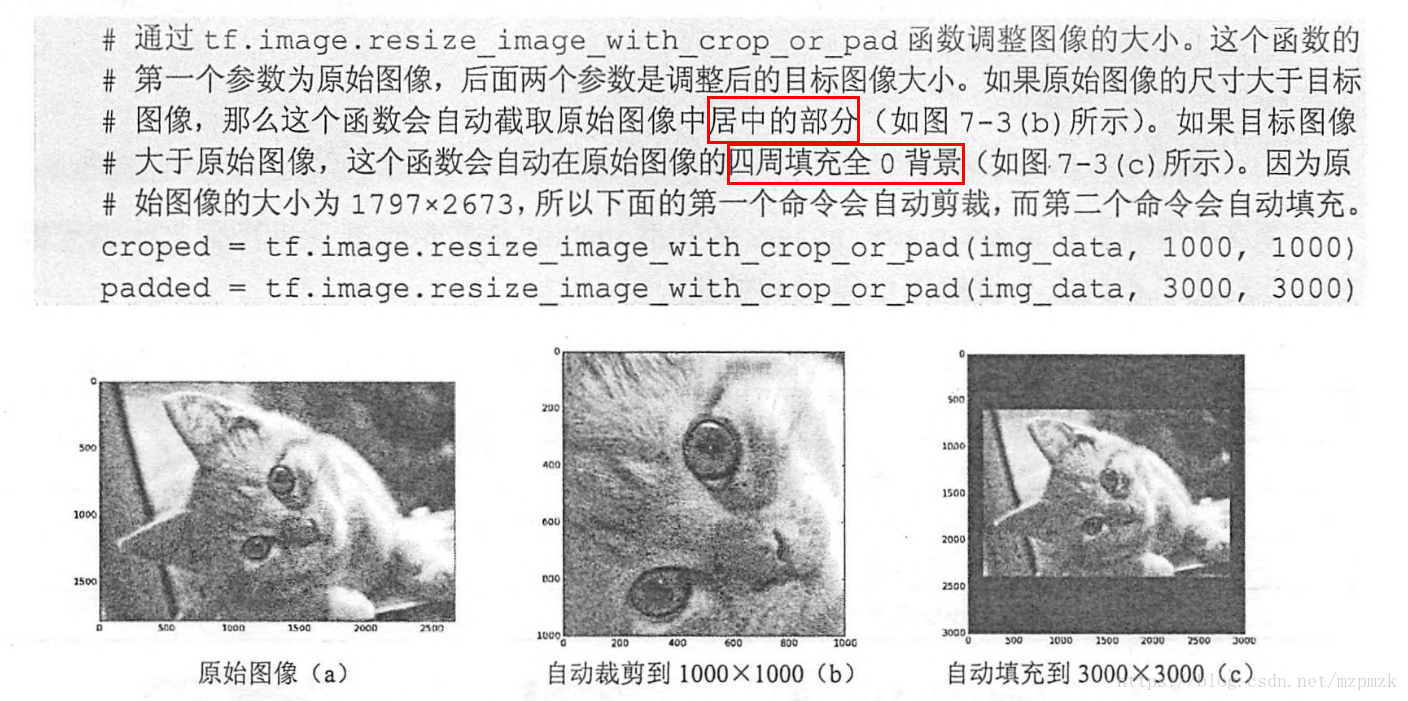
- 隨機裁剪或補零(Random Crop or Pad):將影象隨機裁剪或補零到指定大小
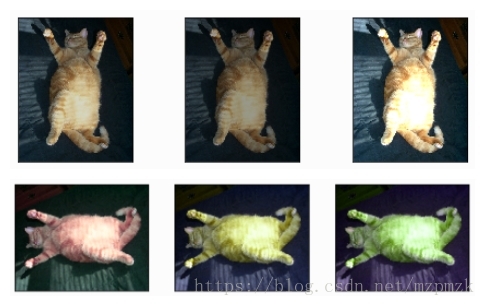
- 色彩抖動(Color jittering):HSV 顏色空間隨機改變影象原有的
飽和度和明度(即,改變 S 和 V 通道的值)或對色調(Hue)進行小範圍微調。
- 加噪聲(Noise):加入隨機噪聲。
- 特殊的資料增強方法:
- Fancy PCA(Alexnet)& 監督式資料擴充(海康)
- 使用生成對抗網路(GAN) 生成模擬影象
- 使用 HSV 來調整影象顏色的原理:
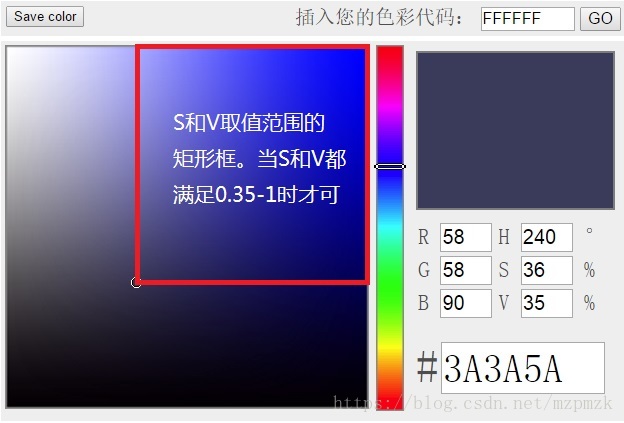
- 通常我們會想到使用影象的 RGB 值來判斷其顏色,但是影象顏色是由這三個值共同決定的,只固定其中一個分量(比如藍色分量),很難調節另外兩個分量的配比讓其一定呈現藍色。而 HSV 則非常適合影象顏色判斷的問題。其中,H(ue) 代表色調,取值範圍為:,紅色為 ,綠色為 ,藍色為 ;S(aturation)代表飽和度,取值範圍為:,值越大,色彩越飽和;V(alue) 代表明度,取值範圍為:,值越大,色彩越明亮。
- 色調(H) 是 HSV 顏色模型中唯一與顏色本質有關的變數,所以只要固定了 H 的值,並且保持飽和度(S)和明度(V)分量不太小,那麼表現的顏色就基本可以確定了。如下圖所示,當我們固定 時,只要飽和度(S)和明度(V)都大於 ,那麼我們就可以認為框中的顏色均為為藍色。
- 通常我們會想到使用影象的 RGB 值來判斷其顏色,但是影象顏色是由這三個值共同決定的,只固定其中一個分量(比如藍色分量),很難調節另外兩個分量的配比讓其一定呈現藍色。而 HSV 則非常適合影象顏色判斷的問題。其中,H(ue) 代表色調,取值範圍為:




二、資料預處理
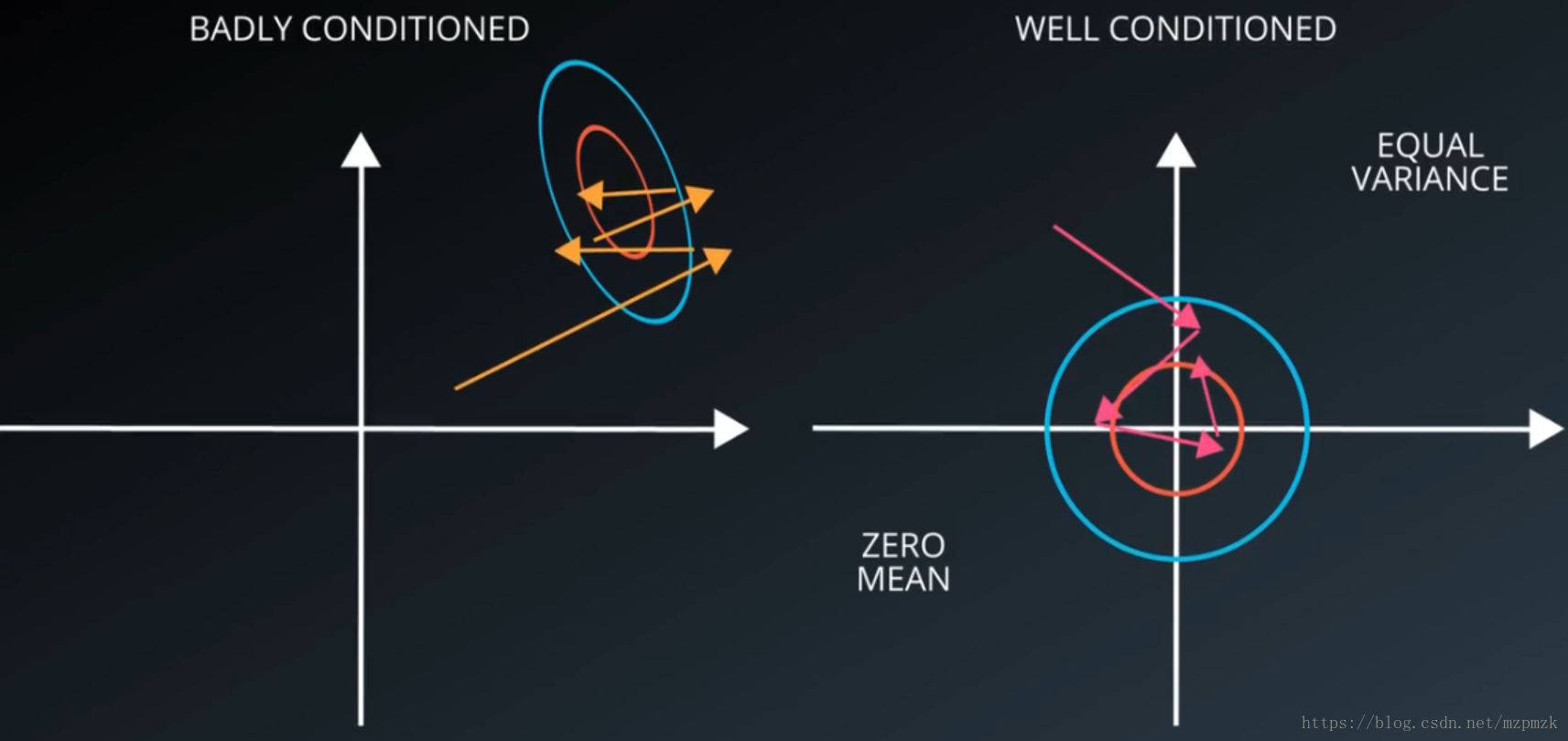
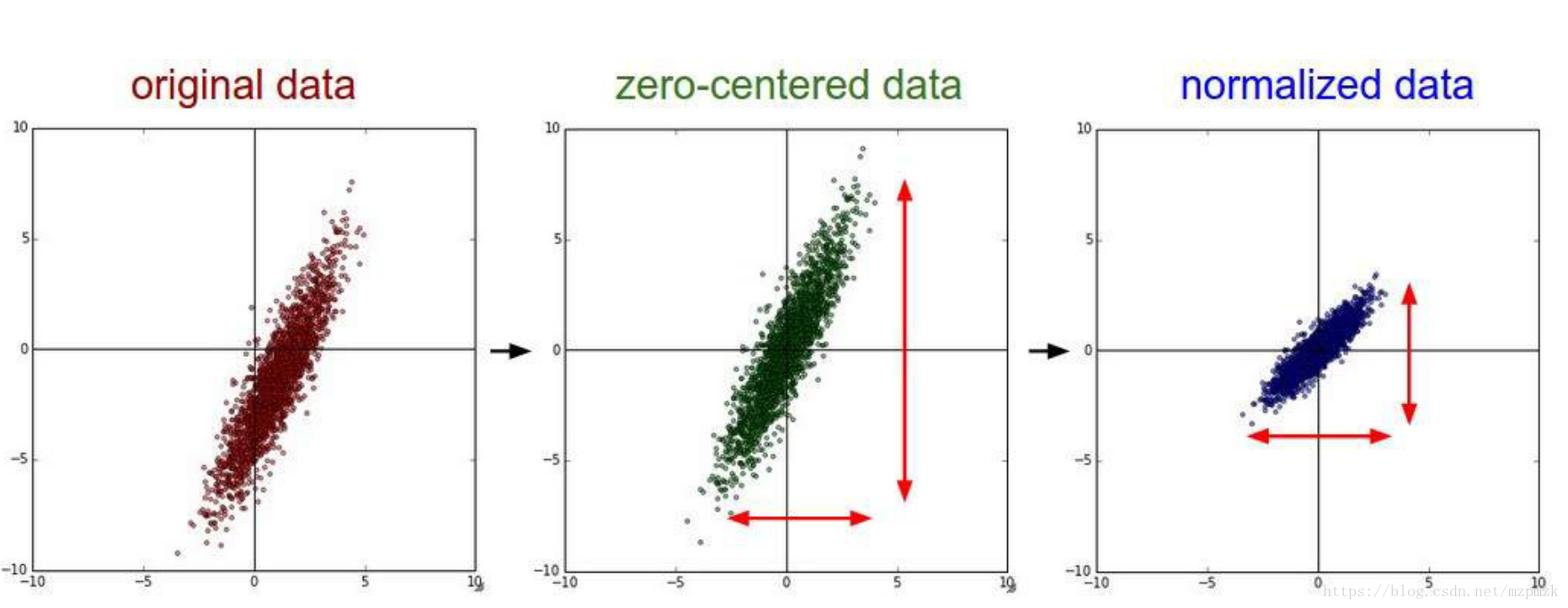
- 在影象處理中,影象的每個畫素資訊都可以看作是一種特徵,對每個特徵減去平均值來中心化特徵是非常重要的,它可以加快模型的收斂,如下圖所示:
注意:通常是計算訓練集影象畫素的均值,之後在處理訓練集、驗證集和測試集時需要分別減去該均值。在實踐中,直接減去 128 再除以 128或者直接做標準化處理都可以。- 去均值與歸一化過程如下圖所示: