
網站點選流資料分析專案
什麼是點選流資料
1.1.1 WEB訪問日誌
即指使用者訪問網站時的所有訪問、瀏覽、點選行為資料。比如點選了哪一個連結,在哪個網頁停留時間最多,採用了哪個搜尋項、總體瀏覽時間等。而所有這些資訊都可被儲存在網站日誌中。通過分析這些資料,可以獲知許多對網站運營至關重要的資訊。採集的資料越全面,分析就能越精準。
日誌的生成渠道:
1)是網站的web伺服器所記錄的web訪問日誌;
2)是通過在頁面嵌入自定義的js程式碼來獲取使用者的所有訪問行為(比如滑鼠懸停的位置,點選的頁面元件等),然後通過ajax請求到後臺記錄日誌;這種方式所能採集的資訊最全面;
3)通過在頁面上埋點1畫素的圖片,將相關頁面訪問資訊請求到後臺記錄日誌;
日誌資料內容詳述:
在實際操作中,有以下幾個方面的資料可以被採集:
1) 訪客的系統屬性特徵。比如所採用的作業系統、瀏覽器、域名和訪問速度等。
2) 訪問特徵。包括停留時間、點選的URL等。
3) 來源特徵。包括網路內容資訊型別、內容分類和來訪URL等。
4) 產品特徵。包括所訪問的產品編號、產品類別、產品顏色、產品價格、產品利潤、產品數量和特價等級等。
以電商某東為例,其點選日誌格式如下:
GET /log.gif?t=item.010001&m=UA-J2011-1&pin=-&uid=1679790178&sid=1679790178|12&v=je=1
1.1.2 點選流資料模型
點選流概念
點選流這個概念更注重使用者瀏覽網站的整個流程,網站日誌中記錄的使用者點選就像是圖上的“點”,而點選流更像是將這些“點”串起來形成的“線”。也可以把“點”認為是網站的Page,而“線”則是訪問網站的Session。所以點選流資料是由網站日誌中整理得到的,它可以比網站日誌包含更多的資訊,從而使基於點選流資料統計得到的結果更加豐富和高效。
點選的關鍵度量與指標
1) 請求數(Hits)-使用者點選次數,對伺服器資源的請求個數。
2) 點選數(Clicks)-頁面資源的請求數。
3) 會話數(Sessions)-超過30分鐘沒有請求,重新開始一次會話
4) 訪問數(Visits)
5) 唯一訪客數(Unique Visitor,UV)
6) 重複訪客數(Repearted Visitors)
7) 頁面瀏覽量(Page Views,PV)
使用者行為分析
1) 每次會話PV數
2) 每日/每小時PV數
3) 網站訪問時長
4) 離開退出率
解決方案:
1. 基於命令列和sql的純手工分析
常用的linux命令有:
Sort、tail、less、uniq、grep、sed、awk等
如統計日誌中訪問量最高的前100個ip地址
Shell命令:
Cat localhost_access_log.2017-08-05.txt|awk ‘{a[$1]++}END{for(b in a) print b”\t”a[b]}’|sort-k2-r|head –n 100
點選流模型生成
點選流資料在具體操作上是由散點狀的點選日誌資料梳理所得,從而,點選資料在資料建模時應該存在兩張模型表(Pageviews和visits):
1、用於生成點選流的訪問日誌表
時間戳 IP地址 Cookie Session 請求URL Referal
2012-01-01 12:31:12 101.0.0.1 User01 S001 /a/… somesite.com
2012-01-01 12:31:16 201.0.0.2 User02 S002 /a/… -
2012-01-01 12:33:06 101.0.0.2 User03 S002 /b/… baidu.com
2012-01-01 15:16:39 234.0.0.3 User01 S003 /c/… google.com
2012-01-01 15:17:11 101.0.0.1 User01 S004 /d/… /c/…
2012-01-01 15:19:23 101.0.0.1 User01 S004 /e/… /d/….
2、頁面點選流模型Pageviews表
Session userid 時間 訪問頁面URL 停留時長 第幾步
S001 User01 2012-01-01 12:31:12 /a/…. 30 1
S002 User02 2012-01-01 12:31:16 /a/…. 10 1
S002 User02 2012-01-01 12:33:06 /b/…. 110 2
S002 User02 2012-01-01 12:35:06 /e/…. 30 3
3、點選流模型Visits表
Session 起始時間 結束時間 進入頁面 離開頁面 訪問頁面數 IP cookie referal
S001 2012-01-01 12:31:12 2012-01-01 12:31:12 /a/… /a/… 1 101.0.0.1 User01 somesite.com
S002 2012-01-01 12:31:16 2012-01-01 12:35:06 /a/… /e/… 3 201.0.0.2 User02 -
S003 2012-01-01 12:35:42 2012-01-01 12:35:42 /c/… /c/… 1 234.0.0.3 User03 baidu.com
S003 2012-01-01 15:16:39 2012-01-01 15:19:23 /c/… /e/… 3 101.0.0.1 User01 google.com
…… …… …… …… …… …… …… …… ……
這就是點選流模型。當WEB日誌轉化成點選流資料的時候,很多網站分析度量的計算變得簡單了,這就是點選流的“魔力”所在。基於點選流資料我們可以統計出許多常見的網站分析度量
1.2網站流量資料分析的意義
網站流量統計分析,可以幫助網站管理員、運營人員、推廣人員等實時獲取網站流量資訊,並從流量來源、網站內容、網站訪客特性等多方面提供網站分析的資料依據。從而幫助提高網站流量,提升網站使用者體驗,讓訪客更多的沉澱下來變成會員或客戶,通過更少的投入獲取最大化的收入。
如下表:
網站的眼睛 網站的神經 網站的大腦
訪問者來自哪裡?
訪問者在尋找什麼?
哪些頁面最受歡迎?
訪問者從哪裡進入?
網頁佈局合理嗎?
網站導航清晰嗎?
哪些功能存在問題
網站內容有效嗎
轉化路徑靠譜嗎? 如何分解目標?
如何分配廣告預算?
如何衡量產品表現?
哪些產品需要優化?
哪些指標需要關注?
點選流分析的意義可分為兩大方面:
1、技術上
可以合理修改網站結構及適度分配資源,構建後臺伺服器群組,比如
輔助改進網路的拓撲設計,提高效能
在有高度相關性的節點之間安排快速有效的訪問路徑
幫助企業更好地設計網站主頁和安排網頁內容
2、業務上
1) 幫助企業改善市場營銷決策,如把廣告放在適當的Web頁面上。
2) 優化頁面及業務流程設計,提高流量轉化率。
3) 幫助企業更好地根據客戶的興趣來安排內容。
4) 幫助企業對客戶群進行細分,針對不同客戶制定個性化的促銷策略等。
終極目標是:改善網站(電商、社交、電影、小說)的運營,獲取更高投資回報率(ROI)
如何進行網站流量分析
流量分析整體來說是一個內涵非常豐富的體系,其整體過程是一個金字塔結構:
1.3.1 流量分析模型舉例
通常有以下幾大類的分析需求:
1)網站流量質量分析
流量對於每個網站來說都是很重要,但流量並不是越多越好,應該更加看重流量的質量,換句話來說就是流量可以為我們帶來多少收入。
2)網站流量多維度細分
細分是指通過不同維度對指標進行分割,檢視同一個指標在不同維度下的表現,進而找出有問題的那部分指標,對這部分指標進行優化。
3)網站內容及導航分析
對於所有網站來說,頁面都可以被劃分為三個類別:
導航頁
功能頁
內容頁
首頁和列表頁都是典型的導航頁;
站內搜尋頁面、登錄檔單頁面和購物車頁面都是典型的功能頁,
而產品詳情頁、新聞和文章頁都是典型的內容頁。
比如從內容導航分析中,以下兩類行為就是網站運營者不希望看到的行為:
第一個問題:訪問者從導航頁進入,在還沒有看到內容頁面之前就從導航頁離開網站,需要分析導航頁造成訪問者中途離開的原因。
第二個問題:訪問者從導航頁進入內容頁後,又返回到導航頁,說明需要分析內容頁的最初設計,並考慮中內容頁提供交叉的資訊推薦
4)網站轉化及漏斗分析
所謂轉化,即網站業務流程中的一個封閉渠道,引導使用者按照流程最終實現業務目標(比如商品成交);而漏斗模型則是指進入渠道的使用者在各環節遞進過程中逐漸流失的形象描述;
對於轉化渠道,主要進行兩部分的分析:
訪問者的流失和迷失
1、阻力和流失
造成流失的原因很多,如:
不恰當的商品或活動推薦
對支付環節中專業名詞的解釋、幫助資訊等內容不當
2、迷失
造成迷失的主要原因是轉化流量設計不合理,訪問者在特定階段得不到需要的資訊,並且不能根據現有的資訊作出決策
總之,網站流量分析是一門內容非常豐富的學科,本課程中主要關注網站分析過程中的技術運用,更多關於網站流量分析的業務知識可學習推薦資料。
1.3.2 流量分析常見指標
課程中涉及的分析指標主要位於以下幾大方面:
1)基礎分析(PV,IP,UV)
趨勢分析:根據選定的時段,提供網站流量資料,通過流量趨勢變化形態,為您分析網站訪客的訪問規律、網站發展狀況提供參考。
對比分析:根據選定的兩個對比時段,提供網站流量在時間上的縱向對比報表,幫您發現網站發展狀況、發展規律、流量變化率等。
當前線上:提供當前時刻站點上的訪客量,以及最近15分鐘流量、來源、受訪、訪客變化情況等,方便使用者及時瞭解當前網站流量狀況。
訪問明細:提供最近7日的訪客訪問記錄,可按每個PV或每次訪問行為(訪客的每次會話)顯示,並可按照來源、搜尋詞等條件進行篩選。 通過訪問明細,使用者可以詳細瞭解網站流量的累計過程,從而為使用者快速找出流量變動原因提供最原始、最準確的依據。
來源分析
來源分類:提供不同來源形式(直接輸入、搜尋引擎、其他外部連結、站內來源)、不同來源項引入流量的比例情況。通過精確的量化資料,幫助使用者分析什麼型別的來路產生的流量多、效果好,進而合理優化推廣方案。
搜尋引擎:提供各搜尋引擎以及搜尋引擎子產品引入流量的比例情況。從搜尋引擎引入流量的的角度,幫助使用者瞭解網站的SEO、SEM效果,從而為制定下一步SEO、SEM計劃提供依據。
搜尋詞:提供訪客通過搜尋引擎進入網站所使用的搜尋詞,以及各搜尋詞引入流量的特徵和分佈。幫助使用者瞭解各搜尋詞引入流量的質量,進而瞭解訪客的興趣關注點、網站與訪客興趣點的匹配度,為優化SEO方案及SEM提詞方案提供詳細依據。
最近7日的訪客搜尋記錄,可按每個PV或每次訪問行為(訪客的每次會話)顯示,並可按照訪客型別、地區等條件進行篩選。為您搜尋引擎優化提供最詳細的原始資料。
來路域名:提供具體來路域名引入流量的分佈情況,並可按“社會化媒體”、“搜尋引擎”、“郵箱”等網站型別對來源域名進行分類。 幫助使用者瞭解哪類推廣渠道產生的流量多、效果好,進而合理優化網站推廣方案。
來路頁面:提供具體來路頁面引入流量的分佈情況。 尤其對於通過流量置換、包廣告位等方式從其他網站引入流量的使用者,該功能可以方便、清晰地展現廣告引入的流量及效果,為優化推廣方案提供依據。
來源升降榜:提供開通統計後任意兩日的TOP10000搜尋詞、來路域名引入流量的對比情況,並按照變化的劇烈程度提供排行榜。 使用者可通過此功能快速找到哪些來路對網站流量的影響比較大,從而及時排查相應來路問題。
3)受訪分析
受訪域名:提供訪客對網站中各個域名的訪問情況。 一般情況下,網站不同域名提供的產品、內容各有差異,通過此功能使用者可以瞭解不同內容的受歡迎程度以及網站運營成效。
受訪頁面:提供訪客對網站中各個頁面的訪問情況。 站內入口頁面為訪客進入網站時瀏覽的第一個頁面,如果入口頁面的跳出率較高則需要關注並優化;站內出口頁面為訪客訪問網站的最後一個頁面,對於離開率較高的頁面需要關注並優化。
受訪升降榜:提供開通統計後任意兩日的TOP10000受訪頁面的瀏覽情況對比,並按照變化的劇烈程度提供排行榜。 可通過此功能驗證經過改版的頁面是否有流量提升或哪些頁面有巨大流量波動,從而及時排查相應問題。
熱點圖:記錄訪客在頁面上的滑鼠點選行為,通過顏色區分不同區域的點選熱度;支援將一組頁面設定為”關注範圍”,並可按來路細分點選熱度。 通過訪客在頁面上的點選量統計,可以瞭解頁面設計是否合理、廣告位的安排能否獲取更多佣金等。
使用者視點:提供受訪頁面對頁面上鍊接的其他站內頁面的輸出流量,並通過輸出流量的高低繪製熱度圖,與熱點圖不同的是,所有記錄都是實際打開了下一頁面產生了瀏覽次數(PV)的資料,而不僅僅是擁有滑鼠點選行為。
訪問軌跡:提供觀察焦點頁面的上下游頁面,瞭解訪客從哪些途徑進入頁面,又流向了哪裡。 通過上游頁面列表比較出不同流量引入渠道的效果;通過下游頁面列表瞭解使用者的瀏覽習慣,哪些頁面元素、內容更吸引訪客點選。
4)訪客分析
地區運營商:提供各地區訪客、各網路運營商訪客的訪問情況分佈。 地方網站、下載站等與地域性、網路鏈路等結合較為緊密的網站,可以參考此功能資料,合理優化推廣運營方案。
終端詳情:提供網站訪客所使用的瀏覽終端的配置情況。 參考此資料進行網頁設計、開發,可更好地提高網站相容性,以達到良好的使用者互動體驗。
新老訪客:當日訪客中,歷史上第一次訪問該網站的訪客記為當日新訪客;歷史上已經訪問過該網站的訪客記為老訪客。 新訪客與老訪客進入網站的途徑和瀏覽行為往往存在差異。該功能可以輔助分析不同訪客的行為習慣,針對不同訪客優化網站,例如為製作新手導航提供資料支援等。
忠誠度:從訪客一天內回訪網站的次數(日訪問頻度)與訪客上次訪問網站的時間兩個角度,分析訪客對網站的訪問粘性、忠誠度、吸引程度。 由於提升網站內容的更新頻率、增強使用者體驗與使用者價值可以有更高的忠誠度,因此該功能在網站內容更新及使用者體驗方面提供了重要參考。
活躍度:從訪客單次訪問瀏覽網站的時間與網頁數兩個角度,分析訪客在網站上的活躍程度。 由於提升網站內容的質量與數量可以獲得更高的活躍度,因此該功能是網站內容分析的關鍵指標之一。
5)轉化路徑分析
轉化定義
·訪客在您的網站完成了某項您期望的活動,記為一次轉化,如註冊或下載。
目標示例
·獲得使用者目標:線上註冊、建立賬號等。
·諮詢目標:諮詢、留言、電話等。
·互動目標:視訊播放、加入購物車、分享等。
·收入目標:線上訂單、付款等。
轉化資料的應用
·在報告的自定義指標中勾選轉化指標,實時掌握網站的推廣及運營情況。
·結合“全部來源”、“轉化路徑”、“頁面上下游”等報告分析訪問漏斗,提高轉化率。
·對“轉化目標”設定價值,預估轉化收益,衡量ROI。
路徑分析:根據設定的特定路線,監測某一流程的完成轉化情況,算出每步的轉換率和流失率資料,如註冊流程,購買流程等。
轉化型別:
1、頁面
2、事件
2 整體技術流程及架構
2.1 資料處理流程
該專案是一個純粹的資料分析專案,其整體流程基本上就是依據資料的處理流程進行,依此有以下幾個大的步驟:
1) 資料採集
首先,通過頁面嵌入JS程式碼的方式獲取使用者訪問行為,併發送到web服務的後臺記錄日誌
然後,將各伺服器上生成的點選流日誌通過實時或批量的方式匯聚到HDFS檔案系統中
當然,一個綜合分析系統,資料來源可能不僅包含點選流資料,還有資料庫中的業務資料(如使用者資訊、商品資訊、訂單資訊等)及對分析有益的外部資料。
2) 資料預處理
通過mapreduce程式對採集到的點選流資料進行預處理,比如清洗,格式整理,濾除髒資料等
3) 資料入庫
將預處理之後的資料匯入到HIVE倉庫中相應的庫和表中
4) 資料分析
專案的核心內容,即根據需求開發ETL分析語句,得出各種統計結果
5) 資料展現
將分析所得資料進行視覺化
2.2 專案結構
由於本專案是一個純粹資料分析專案,其整體結構亦跟分析流程匹配,並沒有特別複雜的結構,如下圖:
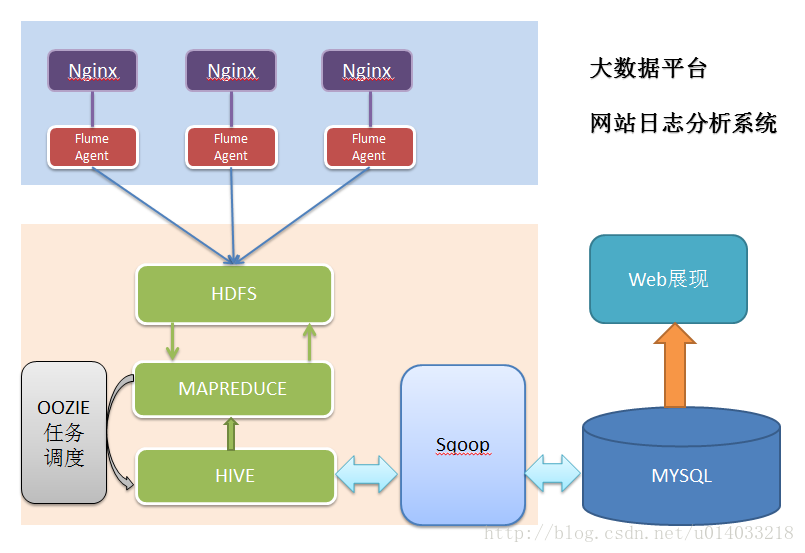
模組開發——資料採集
3.1 需求
資料採集的需求廣義上來說分為兩大部分。
1)是在頁面採集使用者的訪問行為,具體開發工作:
1、開發頁面埋點js,採集使用者訪問行為
2、後臺接受頁面js請求記錄日誌
此部分工作也可以歸屬為“資料來源”,其開發工作通常由web開發團隊負責
2)是從web伺服器上匯聚日誌到HDFS,是資料分析系統的資料採集,此部分工作由資料分析平臺建設團隊負責,具體的技術實現有很多方式:
Shell指令碼
優點:輕量級,開發簡單
缺點:對日誌採集過程中的容錯處理不便控制
Java採集程式
優點:可對採集過程實現精細控制
缺點:開發工作量大
Flume日誌採集框架
成熟的開源日誌採集系統,且本身就是hadoop生態體系中的一員,與hadoop體系中的各種框架元件具有天生的親和力,可擴充套件性強
3.2 技術選型
在點選流日誌分析這種場景中,對資料採集部分的可靠性、容錯能力要求通常不會非常嚴苛,因此使用通用的flume日誌採集框架完全可以滿足需求。
本專案即使用flume來實現日誌採集。
3.3 Flume日誌採集系統搭建
1、資料來源資訊
本專案分析的資料用nginx伺服器所生成的流量日誌,存放在各臺nginx伺服器上,如:
/var/log/httpd/access_log.2015-11-10-13-00.log
/var/log/httpd/access_log.2015-11-10-14-00.log
/var/log/httpd/access_log.2015-11-10-15-00.log
/var/log/httpd/access_log.2015-11-10-16-00.log
2、資料內容樣例
資料的具體內容在採集階段其實不用太關心。
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000] “GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1” 304 0 “http://blog.fens.me/nodejs-socketio-chat/” “Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0”
欄位解析:
1、訪客ip地址: 58.215.204.118
2、訪客使用者資訊: - -
3、請求時間:[18/Sep/2013:06:51:35 +0000]
4、請求方式:GET
5、請求的url:/wp-includes/js/jquery/jquery.js?ver=1.10.2
6、請求所用協議:HTTP/1.1
7、響應碼:304
8、返回的資料流量:0
9、訪客的來源url:http://blog.fens.me/nodejs-socketio-chat/
10、訪客所用瀏覽器:Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0
3、日誌檔案生成規律
基本規律為:
當前正在寫的檔案為access_log;
檔案體積達到64M,或時間間隔達到60分鐘,即滾動重新命名切換成歷史日誌檔案;
形如: access_log.2015-11-10-13-00.log
當然,每個公司的web伺服器日誌策略不同,可在web程式的log4j.properties中定義,如下:
log4j.appender.logDailyFile = org.apache.log4j.DailyRollingFileAppender
log4j.appender.logDailyFile.layout = org.apache.log4j.PatternLayout
log4j.appender.logDailyFile.layout.ConversionPattern = [%-5p][%-22d{yyyy/MM/dd HH:mm:ssS}][%l]%n%m%n
log4j.appender.logDailyFile.Threshold = DEBUG
log4j.appender.logDailyFile.ImmediateFlush = TRUE
log4j.appender.logDailyFile.Append = TRUE
log4j.appender.logDailyFile.File = /var/logs/access_log
log4j.appender.logDailyFile.DatePattern = ‘.’yyyy-MM-dd-HH-mm’.log’
log4j.appender.logDailyFile.Encoding = UTF-8
4、Flume採集實現
Flume採集系統的搭建相對簡單:
1、在個web伺服器上部署agent節點,修改配置檔案
2、啟動agent節點,將採集到的資料匯聚到指定的HDFS目錄中
版本選擇:apache-flume-1.6.0
採集規則設計:
1、 採集源:nginx伺服器日誌目錄
2、 存放地:hdfs目錄/home/hadoop/weblogs/
採集規則配置詳情
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
Describe/configure spooldir source1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /var/logs/nginx/
agent1.sources.source1.fileHeader = false
Describe/configure tail -F source1
使用exec作為資料來源source元件
agent1.sources.source1.type = exec
使用tail -F命令實時收集新產生的日誌資料
agent1.sources.source1.command = tail -F /var/logs/nginx/access_log
agent1.sources.source1.channels = channel1
configure host for source
配置一個攔截器外掛
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = host
使用攔截器外掛獲取agent所在伺服器的主機名
agent1.sources.source1.interceptors.i1.hostHeader = hostname
配置sink元件為hdfs
agent1.sinks.sink1.type = hdfs
a1.sinks.k1.channel = c1
agent1.sinks.sink1.hdfs.path=hdfs://hdp-node-01:9000/weblog/flume-collection/%y-%m-%d/%H%M%S
指定檔案sink到hdfs上的路徑
agent1.sinks.sink1.hdfs.path=
hdfs://hdp-node-01:9000/weblog/flume-collection/%y-%m-%d/%H-%M_%hostname
指定檔名字首
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
指定每批下沉資料的記錄條數
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
指定下沉檔案按1G大小滾動
agent1.sinks.sink1.hdfs.rollSize = 1024*1024*1024
指定下沉檔案按1000000條數滾動
agent1.sinks.sink1.hdfs.rollCount = 1000000
指定下沉檔案按30分鐘滾動
agent1.sinks.sink1.hdfs.rollInterval = 30
agent1.sinks.sink1.hdfs.round = true
agent1.sinks.sink1.hdfs.roundValue = 10
agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
Use a channel which buffers events in memory
使用memory型別channel
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
啟動採集
在部署了flume的nginx伺服器上,啟動flume的agent,命令如下:
bin/flume-ng agent –conf ./conf -f ./conf/weblog.properties.2 -n agent
注意:啟動命令中的 -n 引數要給配置檔案中配置的agent名稱
4 模組開發——資料預處理
4.1 主要目的:
過濾“不合規”資料
格式轉換和規整
根據後續的統計需求,過濾分離出各種不同主題的基礎資料
4.2 實現方式:
開發一個mr程式WeblogPreProcess(內容太長,見工程程式碼)
public class WeblogPreProcess {
static class WeblogPreProcessMapper extends Mapper
##
mm string 分割槽欄位–月
dd string 分割槽欄位–日
5.2 維度表
時間維度 v_year_month_date
year
month
day
hour
minute
訪客地域維度t_dim_area
北京
上海
廣州
深圳
河北
河南
終端型別維度t_dim_termination
uc
firefox
chrome
safari
ios
android
網站欄目維度 t_dim_section
跳蚤市場
房租資訊
休閒娛樂
建材裝修
本地服務
人才市場
6 模組開發——ETL
該專案的資料分析過程在hadoop叢集上實現,主要應用hive資料倉庫工具,因此,採集並經過預處理後的資料,需要載入到hive資料倉庫中,以進行後續的挖掘分析。
6.1建立原始資料表
–在hive倉庫中建貼源資料表
drop table if exists ods_weblog_origin;
create table ods_weblog_origin(
valid string,
remote_addr string,
remote_user string,
time_local string,
request string,
status string,
body_bytes_sent string,
http_referer string,
http_user_agent string)
partitioned by (datestr string)
row format delimited
fields terminated by ‘\001’;
點選流模型pageviews表
drop table if exists ods_click_pageviews;
create table ods_click_pageviews(
Session string,
remote_addr string,
time_local string,
request string,
visit_step string,
page_staylong string,
http_referer string,
http_user_agent string,
body_bytes_sent string,
status string)
partitioned by (datestr string)
row format delimited
fields terminated by ‘\001’;
時間維表建立
drop table dim_time if exists ods_click_pageviews;
create table dim_time(
year string,
month string,
day string,
hour string)
row format delimited
fields terminated by ‘,’;
6.2匯入資料
匯入清洗結果資料到貼源資料表ods_weblog_origin
load data inpath ‘/weblog/preprocessed/16-02-24-16/’ overwrite into table ods_weblog_origin partition(datestr=’2013-09-18’);
0: jdbc:hive2://localhost:10000> show partitions ods_weblog_origin;
+——————-+–+
| partition |
+——————-+–+
| timestr=20151203 |
+——————-+–+
0: jdbc:hive2://localhost:10000> select count(*) from ods_origin_weblog;
+——–+–+
| _c0 |
+——–+–+
| 11347 |
+——–+–+
匯入點選流模型pageviews資料到ods_click_pageviews表
0: jdbc:hive2://hdp-node-01:10000> load data inpath ‘/weblog/clickstream/pageviews’ overwrite into table ods_click_pageviews partition(datestr=’2013-09-18’);
0: jdbc:hive2://hdp-node-01:10000> select count(1) from ods_click_pageviews;
+——+–+
| _c0 |
+——+–+
| 66 |
+——+–+
匯入點選流模型visit資料到ods_click_visit表
匯入時間維表:
load data inpath ‘/dim_time.txt’ into table dim_time;
6.3 生成ODS層明細寬表
6.3.1 需求概述
整個資料分析的過程是按照資料倉庫的層次分層進行的,總體來說,是從ODS原始資料中整理出一些中間表(比如,為後續分析方便,將原始資料中的時間、url等非結構化資料作結構化抽取,將各種欄位資訊進行細化,形成明細表),然後再在中間表的基礎之上統計出各種指標資料
6.3.2 ETL實現
建表——明細表 (源:ods_weblog_origin) (目標:ods_weblog_detail)
drop table ods_weblog_detail;
create table ods_weblog_detail(
valid string, –有效標識
remote_addr string, –來源IP
remote_user string, –使用者標識
time_local string, –訪問完整時間
daystr string, –訪問日期
timestr string, –訪問時間
month string, –訪問月
day string, –訪問日
hour string, –訪問時
request string, –請求的url
status string, –響應碼
body_bytes_sent string, –傳輸位元組數
http_referer string, –來源url
ref_host string, –來源的host
ref_path string, –來源的路徑
ref_query string, –來源引數query
ref_query_id string, –來源引數query的值
http_user_agent string –客戶終端標識
)
partitioned by(datestr string);
–抽取refer_url到中間表 “t_ods_tmp_referurl”
–將來訪url分離出host path query query id
drop table if exists t_ods_tmp_referurl;
create table t_ ods _tmp_referurl as
SELECT a.,b.
FROM ods_origin_weblog a LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, “\”“, “”), ‘HOST’, ‘PATH’,’QUERY’, ‘QUERY:id’) b as host, path, query, query_id;
–抽取轉換time_local欄位到中間表明細表 ”t_ ods _detail”
drop table if exists t_ods_tmp_detail;
create table t_ods_tmp_detail as
select b.*,substring(time_local,0,10) as daystr,
substring(time_local,11) as tmstr,
substring(time_local,5,2) as month,
substring(time_local,8,2) as day,
substring(time_local,11,2) as hour
From t_ ods _tmp_referurl b;
以上語句可以改寫成:
insert into table zs.ods_weblog_detail partition(datestr=’$day_01’)
select c.valid,c.remote_addr,c.remote_user,c.time_local,
substring(c.time_local,0,10) as daystr,
substring(c.time_local,12) as tmstr,
substring(c.time_local,6,2) as month,
substring(c.time_local,9,2) as day,
substring(c.time_local,11,3) as hour,
c.request,c.status,c.body_bytes_sent,c.http_referer,c.ref_host,c.ref_path,c.ref_query,c.ref_query_id,c.http_user_agent
from
(SELECT
a.valid,a.remote_addr,a.remote_user,a.time_local,
a.request,a.status,a.body_bytes_sent,a.http_referer,a.http_user_agent,b.ref_host,b.ref_path,b.ref_query,b.ref_query_id
FROM zs.ods_weblog_origin a LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, “\”“, “”), ‘HOST’, ‘PATH’,’QUERY’, ‘QUERY:id’) b as ref_host, ref_path, ref_query, ref_query_id) c
”
0: jdbc:hive2://localhost:10000> show partitions ods_weblog_detail;
+———————+–+
| partition |
+———————+–+
| dd=18%2FSep%2F2013 |
+———————+–+
1 row selected (0.134 seconds)
7 模組開發——統計分析
注:每一種統計指標都可以跟各維度表進行叉乘,從而得出各個維度的統計結果
篇幅限制,叉乘的程式碼及註釋資訊詳見專案工程程式碼檔案
為了在前端展示時速度更快,每一個指標都事先算出各維度結果存入mysql
提前準備好維表資料,在hive倉庫中建立相應維表,如:
時間維表:
create table v_time(year string,month string,day string,hour string)
row format delimited
fields terminated by ‘,’;
load data local inpath ‘/home/hadoop/v_time.txt’ into table v_time;
在實際生產中,究竟需要哪些統計指標通常由相關資料需求部門人員提出,而且會不斷有新的統計需求產生,以下為網站流量分析中的一些典型指標示例。
1. PV統計
1.1 多維度統計PV總量
1. 時間維度
–計算指定的某個小時pvs
select count(*),month,day,hour from dw_click.ods_weblog_detail group by month,day,hour;
–計算該處理批次(一天)中的各小時pvs
drop table dw_pvs_hour;
create table dw_pvs_hour(month string,day string,hour string,pvs bigint) partitioned by(datestr string);
insert into table dw_pvs_hour partition(datestr=’2016-03-18’)
select a.month as month,a.day as day,a.hour as hour,count(1) as pvs from ods_weblog_detail a
where a.datestr=’2016-03-18’ group by a.month,a.day,a.hour;
或者用時間維表關聯
維度:日
drop table dw_pvs_day;
create table dw_pvs_day(pvs bigint,month string,day string);
insert into table dw_pvs_day
select count(1) as pvs,a.month as month,a.day as day from dim_time a
join ods_weblog_detail b
on b.dd=’18/Sep/2013’ and a.month=b.month and a.day=b.day
group by a.month,a.day;
–或者,從之前算好的小時結果中統計
Insert into table dw_pvs_day
Select sum(pvs) as pvs,month,day from dw_pvs_hour group by month,day having day=’18’;
結果如下:
維度:月
drop table t_display_pv_month;
create table t_display_pv_month (pvs bigint,month string);
insert into table t_display_pv_month
select count(*) as pvs,a.month from t_dim_time a
join t_ods_detail_prt b on a.month=b.month group by a.month;
- 按終端維度統計pv總量
注:探索資料中的終端型別
select distinct(http_user_agent) from ods_weblog_detail where http_user_agent like ‘%Mozilla%’ limit 200;
終端維度:uc
drop table t_display_pv_terminal_uc;
create table t_display_pv_ terminal_uc (pvs bigint,mm string,dd string,hh string);
終端維度:chrome
drop table t_display_pv_terminal_chrome;
create table t_display_pv_ terminal_ chrome (pvs bigint,mm string,dd string,hh string);
終端維度:safari
drop table t_display_pv_terminal_safari;
create table t_display_pv_ terminal_ safari (pvs bigint,mm string,dd string,hh string);
- 按欄目維度統計pv總量
欄目維度:job
欄目維度:news
欄目維度:bargin
欄目維度:lane
1.2 人均瀏覽頁數
需求描述:比如,今日所有來訪者,平均請求的頁面數
–總頁面請求數/去重總人數
drop table dw_avgpv_user_d;
create table dw_avgpv_user_d(
day string,
avgpv string);
insert into table dw_avgpv_user_d
select ‘2013-09-18’,sum(b.pvs)/count(b.remote_addr) from
(select remote_addr,count(1) as pvs from ods_weblog_detail where datestr=’2013-09-18’ group by remote_addr) b;
1.3 按referer維度統計pv總量
需求:按照來源及時間維度統計PVS,並按照PV大小倒序排序
– 按照小時粒度統計,查詢結果存入:( “dw_pvs_referer_h” )
drop table dw_pvs_referer_h;
create table dw_pvs_referer_h(referer_url string,referer_host string,month string,day string,hour string,pv_referer_cnt bigint) partitioned by(datestr string);
insert into table dw_pvs_referer_h partition(datestr=’2016-03-18’)
select http_referer,ref_host,month,day,hour,count(1) as pv_referer_cnt
from ods_weblog_detail
group by http_referer,ref_host,month,day,hour
having ref_host is not null
order by hour asc,day asc,month asc,pv_referer_cnt desc;
按天粒度統計各來訪域名的訪問次數並排序
drop table dw_ref_host_visit_cnts_h;
create table dw_ref_host_visit_cnts_h(ref_host string,month string,day string,hour string,ref_host_cnts bigint) partitioned by(datestr string);
insert into table dw_ref_host_visit_cnts_h partition(datestr=’2016-03-18’)
select ref_host,month,day,hour,count(1) as ref_host_cnts
from ods_weblog_detail
group by ref_host,month,day,hour
having ref_host is not null
order by hour asc,day asc,month asc,ref_host_cnts desc;
注:還可以按來源地域維度、訪客終端維度等計算
1.4 統計pv總量最大的來源TOPN
需求描述:按照時間維度,比如,統計一天內產生最多pvs的來源topN
需要用到row_number函式
以下語句對每個小時內的來訪host次數倒序排序標號,
select ref_host,ref_host_cnts,concat(month,hour,day),
row_number() over (partition by concat(month,hour,day) order by ref_host_cnts desc) as od
from dw_ref_host_visit_cnts_h
效果如下:
根據上述row_number的功能,可編寫Hql取各小時的ref_host訪問次數topn
drop table dw_pvs_refhost_topn_h;
create table dw_pvs_refhost_topn_h(
hour string,
toporder string,
ref_host string,
ref_host_cnts string
) partitioned by(datestr string);
insert into table zs.dw_pvs_refhost_topn_h partition(datestr=’2016-03-18’)
select t.hour,t.od,t.ref_host,t.ref_host_cnts from
(select ref_host,ref_host_cnts,concat(month,day,hour) as hour,
row_number() over (partition by concat(month,day,hour) order by ref_host_cnts desc) as od
from zs.dw_ref_host_visit_cnts_h) t where od<=3;
結果如下:
注:還可以按來源地域維度、訪客終端維度等計算
- 受訪分析
統計每日最熱門的頁面top10
drop table dw_pvs_d;
create table dw_pvs_d(day string,url string,pvs string);
insert into table dw_pvs_d
select ‘2013-09-18’,a.request,a.request_counts from
(select request as request,count(request) as request_counts from ods_weblog_detail where datestr=’2013-09-18’ group by request having request is not null) a
order by a.request_counts desc limit 10;
結果如下:
注:還可繼續得出各維度交叉結果
- 訪客分析
3.1 獨立訪客
需求描述:按照時間維度比如小時來統計獨立訪客及其產生的pvCnts
對於獨立訪客的識別,如果在原始日誌中有使用者標識,則根據使用者標識即很好實現;
此處,由於原始日誌中並沒有使用者標識,以訪客IP來模擬,技術上是一樣的,只是精確度相對較低
時間維度:時
drop table dw_user_dstc_ip_h;
create table dw_user_dstc_ip_h(
remote_addr string,
pvs bigint,
hour string);
insert into table dw_user_dstc_ip_h
select remote_addr,count(1) as pvs,concat(month,day,hour) as hour
from ods_weblog_detail
Where datestr=’2013-09-18’
group by concat(month,day,hour),remote_addr;
在此結果表之上,可以進一步統計出,每小時獨立訪客總數,每小時請求次數topn訪客等
如每小時獨立