
xpath: Python網頁爬蟲定位輔助利器
網頁爬蟲可以使用Python的正則模組(re), 當然我今天要隆重推薦的是xpath.
xpath需要安裝xpath的基礎包:lxml
首先看一個例子:(爬取果殼的最新推薦文章列表)
import requests
from lxml import etree
url = 'http://www.guokr.com/'
page = requests.get(url).content
s = etree.HTML(page)
h = s.xpath('/html/body/div[1]/div[2]/div[1]/div[2]/div[2]/ul/li/h2/a/text()')
for i in h:
print 輸出結果是:
早餐!早餐!
螞蟻為什麼會繞著手機轉圈走?
螞蟻、蜜蜂都是近親繁殖嗎?
大王烏賊的吃法 怎樣用藥才安全?
五個“第一次”,
蟻人跑起來會跟正常大小的人一樣嗎?
巧克力分子學: 絲滑口感,卵磷脂造
同樣, 可以通過@href來獲取連結, ,通過 @屬性名
h = s.xpath('/html/body/div[1]/div[2]/div[1]/div[2]/div[2]/ul/li/h2/a/@href')
for i in h:
print i如下:
http://www.guokr.com/post/699154/
http: 在這裡稍稍介紹一下xpath的語法:
- //定位根節點
- /往下尋找節點
- 提取文字內容: /text()
- 提取屬性內容:/@hello
當然, 通常我們會通過一些工具來快速獲取網頁元素的xpath, 比如Chrome: 右鍵–>”審查元素”–>相應元素右鍵–>Copy XPath 就可以獲得元素的xpath.
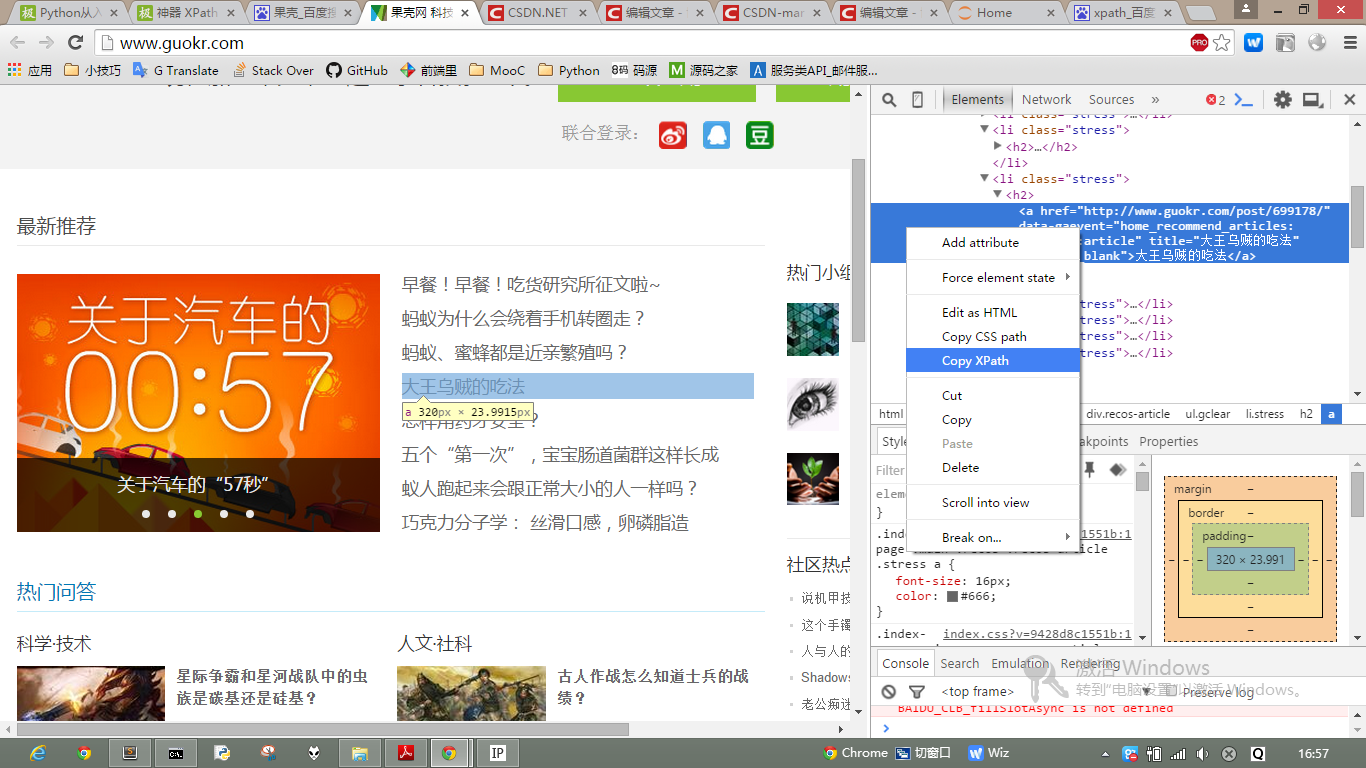
提取結果如下:
/html/body/div[1]/div[2]/div[1]/div[2]/div[2]/ul/li[4]/h2/a
然後稍作修改:
加提取文字字尾/text():
/html/body/div[1]/div[2]/div[1]/div[2]/div[2]/ul/li[4]/h2/a/text()
為了提取更通用, 將最後一個li[4]標籤的4刪除, 匹配所有專案,而不是第四條內容 /html/body/div[1]/div[2]/div[1]/div[2]/div[2]/ul/li[4]/h2/a/text()
/html/body/div[1]/div[2]/div[1]/div[2]/div[2]/ul/li/h2/a/text()
如果需要提取的一組標籤的名字不一樣,但開始部分一樣, 可以startwith: ‘//div[startwith[@id(標籤屬性), ‘hello’)]/text()’