
大資料小白系列——MR(1)
一部程式設計發展史就是一部程式設計師偷懶史,MapReduce(下稱MR)同樣是程式設計師們用來偷懶的工具。
來了一份大資料,我們寫了一個程式準備分析它,需要怎麼做?
老式的處理方法不行,資料量太大時,所需的時間無法忍受,所以,必須平行計算。好比1000塊磚,1個人搬需要1小時,10個人同時搬,只需要6分鐘。
不過進行平行計算,面臨幾個細思頭大問題:
- 如何切分資料
- 如何處理部分任務失敗
- 如何對多路計算的結果進行彙總

不過不用擔心,世界就是這樣的,少部分人發明創造工具,大部分人使用工具。總有聰明人在合適的時候出來解決問題。
Google在2004年出了個paper,《MapReduce: Simplifed Data Processing on Large Clusters》,提出來一種針對大資料的並行處理模型、並基於此理論做了一個計算框架。
所以,你可以說MR是一種計算模型、也可以叫它一個計算框架。廣義的MR甚至還包括一套資源管理(JobTracker、TaskTracker),後面這個我們不講,因為,過,時,了。
Q 框架是什麼?
A 就是套路。內部會幫你處理那些讓你頭大的問題。
作為小白系列,我們先來看看MR簡單的流程圖:
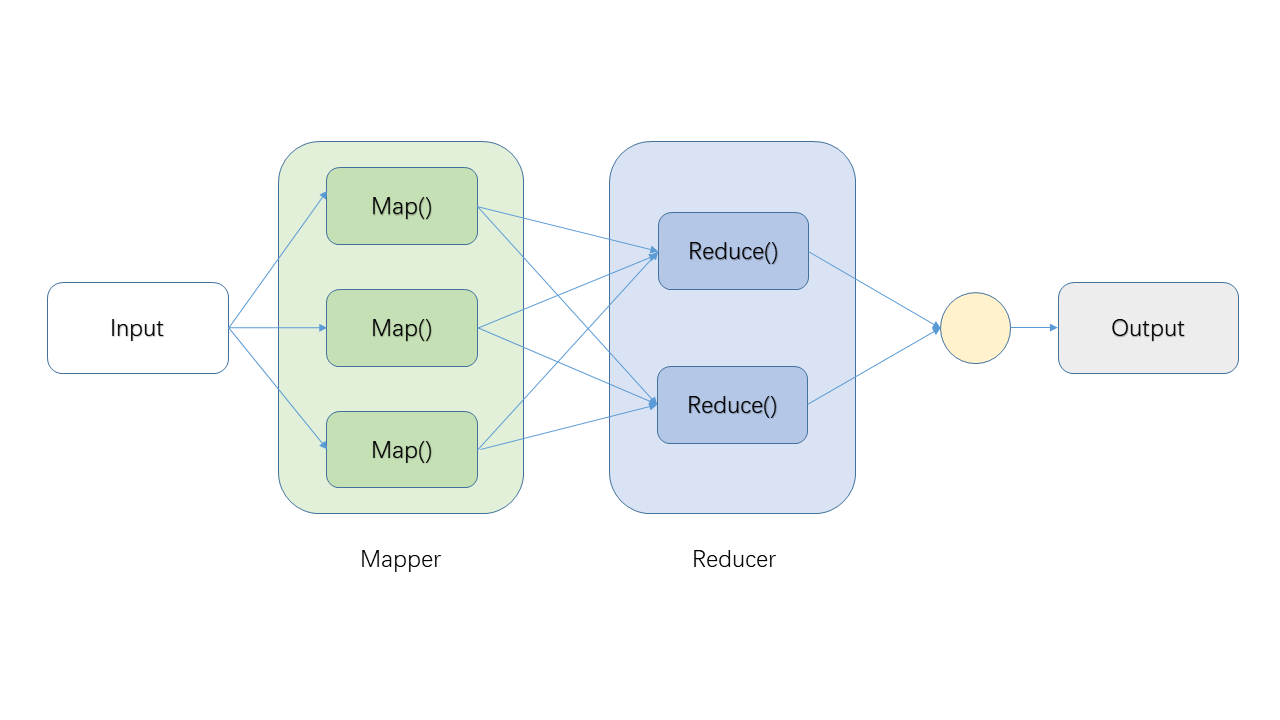
為方便理解,來一個WorkCount示例(WordCount就好比大資料的HelloWorld,總要來一個的)。假設我們有一個檔案包含內容:
Live for nothing, die for something
統計每一個單詞出現的次數:

Q Splitting是怎麼做的,分成幾份?
A 框架決定(通常是檔案有多少個數據塊,就分成幾份,資料塊不懂的回去看HDFS系列)。
Q k1,v1是什麼?
A 一般來說,k1是行號(在WordCount示例中用不到),v1是檔案的某一行。本例只是概念示例,不用糾結。
Q Mapping產生的結果儲存在哪裡?
A 所在機器的本地檔案系統,非HDFS,以避免產生多餘的副本(HDFS預設多個副本)。
Q Shuffling是做什麼的?
A 負責將Mapping產生的中間結果發給Reducer,哪些資料發個哪個Reducer,有框架決定。
Q Reducer有幾個,執行在哪些機器上?
A 框架決定。
Q 哪些是需要程式設計師進行程式碼實現的?
A Mapping及Reducing,即圖中兩個紅框部分。
好了,這期就先說到這,下期將稍微深入瞭解一下MR中的Shuffling、Sorting等概念。Cheers!
—END—
歡迎關注“程式設計師雜書館”公眾號,領取大資料經典紙質書。
