
VALSE2017系列之二: 邊緣檢測領域年度進展報告
 編者按:邊緣檢測是影象處理和計算機視覺中的基本問題,通過標識數字影象中亮度變化明顯的點,來捕捉影象屬性中的顯著變化,包括深度上的不連續、表面方向的不連續、物質屬性變化、和場景照明變化。南開大學的程明明副教授將帶領大家回顧過去一年中,邊緣檢測領域在學術界的研究進展。文末提供報告中提到全部文章的下載地址以及程明明副教授組內工作的開原始碼地址。
編者按:邊緣檢測是影象處理和計算機視覺中的基本問題,通過標識數字影象中亮度變化明顯的點,來捕捉影象屬性中的顯著變化,包括深度上的不連續、表面方向的不連續、物質屬性變化、和場景照明變化。南開大學的程明明副教授將帶領大家回顧過去一年中,邊緣檢測領域在學術界的研究進展。文末提供報告中提到全部文章的下載地址以及程明明副教授組內工作的開原始碼地址。 邊緣檢測在計算機視覺領域的很多應用中都有非常重要的作用。影象邊緣檢測能夠大幅減少資料量,在保留重要的結構屬性的同時,剔除弱相關資訊。
邊緣檢測在計算機視覺領域的很多應用中都有非常重要的作用。影象邊緣檢測能夠大幅減少資料量,在保留重要的結構屬性的同時,剔除弱相關資訊。 在深度學習出現之前,傳統的Sobel濾波器,Canny檢測器具有廣泛的應用,但是這些檢測器只考慮到區域性的急劇變化,特別是顏色、亮度等的急劇變化,通過這些特徵來找邊緣。
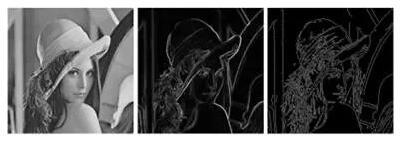
在深度學習出現之前,傳統的Sobel濾波器,Canny檢測器具有廣泛的應用,但是這些檢測器只考慮到區域性的急劇變化,特別是顏色、亮度等的急劇變化,通過這些特徵來找邊緣。 但這些特徵很難模擬較為複雜的場景,如伯克利的分割資料集(Berkeley segmentation Dataset),僅通過亮度、顏色變化並不足以把邊緣檢測做好。2013年,開始有人使用資料驅動的方法來學習怎樣聯合顏色、亮度、梯度這些特徵來做邊緣檢測。當然,還有些流行的方法,比如Pb, gPb,StrucutredEdge。為了更好地評測邊緣檢測演算法,伯克利研究組建立了一個國際公認的評測集,叫做Berkeley Segmentation Benchmark。從圖中的結果可以看出,即使可以學習顏色、亮度、梯度等low-level特徵,但是在特殊場景下,僅憑這樣的特徵很難做到魯棒的檢測。比如上圖的動物影象,我們需要用一些high-level 比如 object-level的資訊才能夠把中間的細節紋理去掉,使其更加符合人的認知過程(舉個形象的例子,就好像畫家在畫這個物體的時候,更傾向於只畫外面這些輪廓,而把裡面的細節給忽略掉)。
但這些特徵很難模擬較為複雜的場景,如伯克利的分割資料集(Berkeley segmentation Dataset),僅通過亮度、顏色變化並不足以把邊緣檢測做好。2013年,開始有人使用資料驅動的方法來學習怎樣聯合顏色、亮度、梯度這些特徵來做邊緣檢測。當然,還有些流行的方法,比如Pb, gPb,StrucutredEdge。為了更好地評測邊緣檢測演算法,伯克利研究組建立了一個國際公認的評測集,叫做Berkeley Segmentation Benchmark。從圖中的結果可以看出,即使可以學習顏色、亮度、梯度等low-level特徵,但是在特殊場景下,僅憑這樣的特徵很難做到魯棒的檢測。比如上圖的動物影象,我們需要用一些high-level 比如 object-level的資訊才能夠把中間的細節紋理去掉,使其更加符合人的認知過程(舉個形象的例子,就好像畫家在畫這個物體的時候,更傾向於只畫外面這些輪廓,而把裡面的細節給忽略掉)。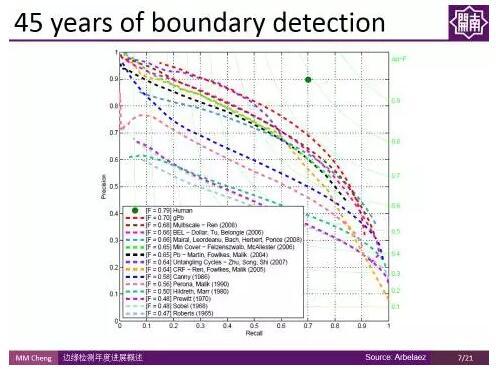 上圖展示了過去45年間特別有代表性的工作在 Berkekey Segmentation Benchmark 上的PR(Precision-Recall)曲線。右上角綠色點是人類表現的均值,F-Measure值在0.8左右。
上圖展示了過去45年間特別有代表性的工作在 Berkekey Segmentation Benchmark 上的PR(Precision-Recall)曲線。右上角綠色點是人類表現的均值,F-Measure值在0.8左右。 傳統的基於特徵的方法,最好的結果只有0.7,這很大程度上是因為傳統的人工設計的特徵並沒有包含高層的物體級別資訊,導致有很多的誤檢。因而研究者們嘗試用卷積神經網路CNN,探索是否可以通過內嵌很多高層的、多尺度的資訊來解決這一問題。
傳統的基於特徵的方法,最好的結果只有0.7,這很大程度上是因為傳統的人工設計的特徵並沒有包含高層的物體級別資訊,導致有很多的誤檢。因而研究者們嘗試用卷積神經網路CNN,探索是否可以通過內嵌很多高層的、多尺度的資訊來解決這一問題。 近幾年,有很多基於CNN的方法的工作。這裡從2014 ACCV N4_Fields開始說起。
近幾年,有很多基於CNN的方法的工作。這裡從2014 ACCV N4_Fields開始說起。 N4-Fields:
N4-Fields:如何從一張圖片裡面找邊緣?我們會想到計算區域性梯度的大小、紋理變化等這些直觀的方法。其實N4-Fields這個方法也很直觀,影象有很多的patch,用卷積神經網路(CNN)算出每個patch的特徵,然後在字典裡面進行檢索,查詢與其相似的邊緣,把這些相似的邊緣資訊整合起來,就成了最終的結果,可以看到,由於特徵更加強大了,結果有了較好的提升。
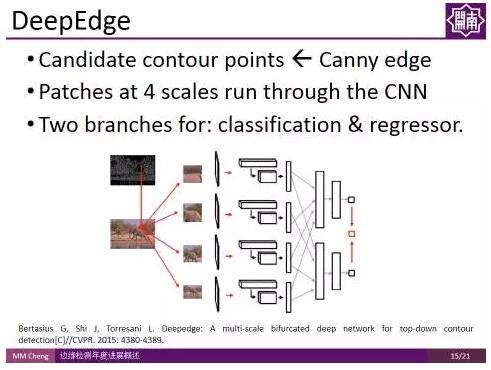 DeepEdge:
DeepEdge:發表在CVPR 2015的DeepEdge對上述工作進行了擴充套件,首先使用Canny edge得到候選輪廓點,然後對這些點建立不同尺度的patch,將這些 patch 輸入兩路的CNN,一路用作分類,一路用作迴歸。最後得到每個候選輪廓點的概率。
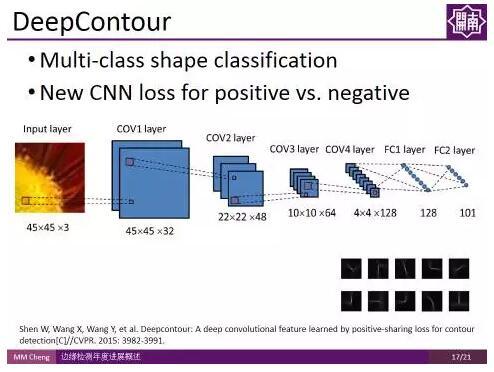 DeepContour:
DeepContour:這是CVPR2015中的另一個工作,該工作還是基於patch的。首先在影象中尋找patch,然後對patch 做多類形狀分類,來判斷這個邊緣是屬於哪一類的邊緣,最後把不同類別的邊緣融合起來得到最終的結果。
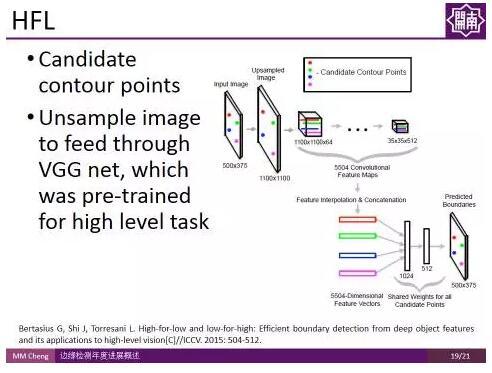 HFL:
HFL:ICCV 2015的工作High-for-Low (HFL)也用CNN對可能的候選輪廓點進行判斷。由於使用了經過高層語義資訊訓練得到的VGG Net,在一定程度上用到了高層語義資訊,因此取得了不錯的結果。
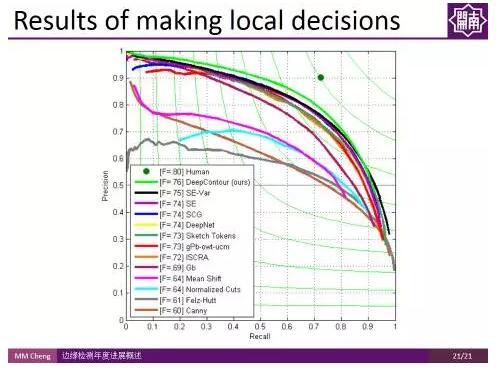 由上圖結果可以看出,這些工作雖然取得了一些進展,但是離人類的表現還有很大的差距。 這些方法的缺點在於都是基於區域性策略所做的結果,每次只看一個區域,即只針對一個patch,並沒有很充分的利用高層級的資訊。
由上圖結果可以看出,這些工作雖然取得了一些進展,但是離人類的表現還有很大的差距。 這些方法的缺點在於都是基於區域性策略所做的結果,每次只看一個區域,即只針對一個patch,並沒有很充分的利用高層級的資訊。 Holistically-Nested Edge Detection:
Holistically-Nested Edge Detection:Holistically-Nested Edge Detection 是屠卓文教授課題組在ICCV 2015 的工作。該工作最大的亮點在於,一改之前邊緣檢測方法基於區域性策略的方式,而是採用全域性的影象到影象的處理方式。即不再針對一個個patch進行操作,而是對整幅影象進行操作,為高層級資訊的獲取提供了便利。
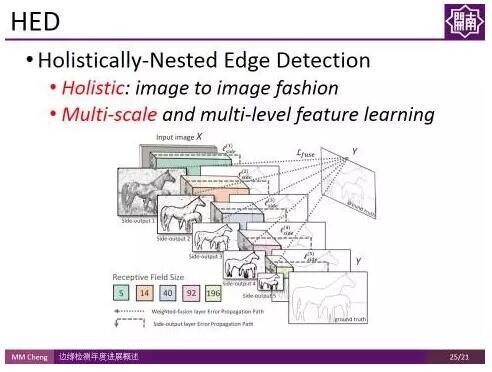 與此同時,該方法使用了multi-scale 和multi-level, 通過groundtruth的對映在卷積層側邊插入一個side output layer,在side output layer上進行deep supervision,將最終的結果和不同的層連線起來。
與此同時,該方法使用了multi-scale 和multi-level, 通過groundtruth的對映在卷積層側邊插入一個side output layer,在side output layer上進行deep supervision,將最終的結果和不同的層連線起來。 如圖所示,加上deep supervision後,該方法可以在不同尺度得到對應抽象程度的邊緣。
如圖所示,加上deep supervision後,該方法可以在不同尺度得到對應抽象程度的邊緣。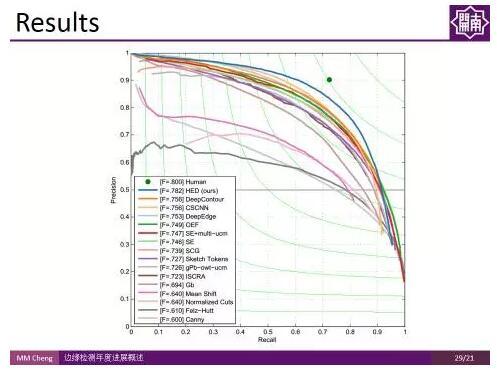 可以看到該方法在伯克利分割Benchmark上的結果較之前有了很大的提升。
可以看到該方法在伯克利分割Benchmark上的結果較之前有了很大的提升。 RCF:
RCF:接下來,介紹的是程明明副教授課題組CVPR2017的工作。其實想法很簡單,一句話就能概括,由於不同卷積層之間的資訊是可以互補的,傳統方法的問題在於資訊利用不充分,相當於只使用了Pooling前最後一個卷積層的資訊,如果我們使用所有卷積層的資訊是不是能夠更好的利用卷積特徵,進而得到更好的結果?
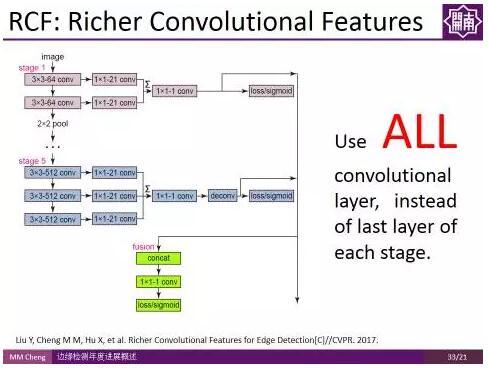 使用所有卷積層的資訊,而不是池化之前的最後一層,這樣一個非常簡單的改變,使得檢測結果有了很大的改善。這種方法也有望遷移到其他領域。
使用所有卷積層的資訊,而不是池化之前的最後一層,這樣一個非常簡單的改變,使得檢測結果有了很大的改善。這種方法也有望遷移到其他領域。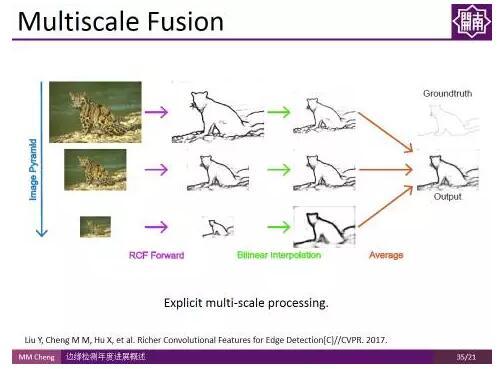 實驗結果表明,雖然卷積神經網路自帶多尺度特徵,但顯式地使用多尺度融合對邊緣檢測結果的提升依然有效。
實驗結果表明,雖然卷積神經網路自帶多尺度特徵,但顯式地使用多尺度融合對邊緣檢測結果的提升依然有效。 這是部分示例結果。
這是部分示例結果。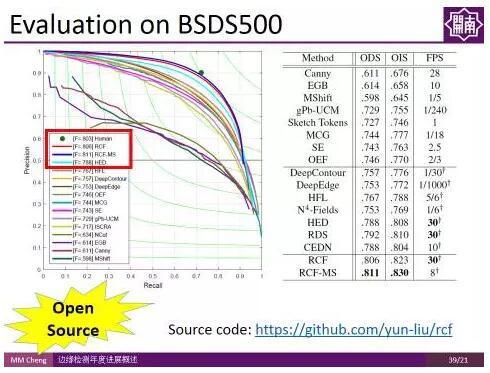 該方法操作簡單,且不明顯增加計算時間,雖然程式碼量少,但在BSDS500資料集上的結果甚至超過人類標註者的平均表現水平,而且在Titan X上能夠達到實時檢測速度(30fps)。且,這部分程式碼是開源的,可通過訪問如下網址獲得: https://github.com/yun-liu/rcf。
該方法操作簡單,且不明顯增加計算時間,雖然程式碼量少,但在BSDS500資料集上的結果甚至超過人類標註者的平均表現水平,而且在Titan X上能夠達到實時檢測速度(30fps)。且,這部分程式碼是開源的,可通過訪問如下網址獲得: https://github.com/yun-liu/rcf。aHR0cDovL21tY2hlbmcubmV0Lw== (二維碼自動識別)
最後,大講堂喜大普奔地告知各位小夥伴:程明明副教授組內幾乎所有工作均開源,可通過掃描上圖二維碼來獲得。致謝:
本文主編袁基睿,誠摯感謝志願者連春燕、賀嬌瑜、李珊如對本文進行了細緻的整理工作。
該文章屬於“深度學習大講堂”原創,如需要轉載,請聯絡@果果是枚開心果.
作者簡介:
 程明明,南開大學副教授,博導,中科協青年人才託舉工程、天津市青年千人、南開大學百名青年學科帶頭人計劃入選者。2012年博士畢業於清華大學,之後在英國牛津從事計算機視覺研究,並於2014年加入南開大學。其主要研究方向包括:計算機圖形學、計算機視覺、影象處理等。已在IEEE PAMI等CCF-A類國際會議及期刊發表論文20餘篇。相關研究成果受到國內外同行的廣泛認可,論文他引5000餘次,最高單篇他引1700餘次。其研究工作曾被英國《BBC》,《每日電訊報》,德國《明鏡週刊》,美國《赫芬頓郵報》等權威國際媒體撰文報道。
程明明,南開大學副教授,博導,中科協青年人才託舉工程、天津市青年千人、南開大學百名青年學科帶頭人計劃入選者。2012年博士畢業於清華大學,之後在英國牛津從事計算機視覺研究,並於2014年加入南開大學。其主要研究方向包括:計算機圖形學、計算機視覺、影象處理等。已在IEEE PAMI等CCF-A類國際會議及期刊發表論文20餘篇。相關研究成果受到國內外同行的廣泛認可,論文他引5000餘次,最高單篇他引1700餘次。其研究工作曾被英國《BBC》,《每日電訊報》,德國《明鏡週刊》,美國《赫芬頓郵報》等權威國際媒體撰文報道。歡迎大家關注我們的微信公眾號,搜尋微信名稱:深度學習大講堂